Natural language processing (NLP) is a subfield of computer science and especially artificial intelligence. It is primarily concerned with providing computers with the ability to process data encoded in natural language and is thus closely related to information retrieval, knowledge representation and computational linguistics, a subfield of linguistics. Typically data is collected in text corpora, using either rule-based, statistical or neural-based approaches in machine learning and deep learning.
Speech processing is the study of speech signals and the processing methods of signals. The signals are usually processed in a digital representation, so speech processing can be regarded as a special case of digital signal processing, applied to speech signals. Aspects of speech processing includes the acquisition, manipulation, storage, transfer and output of speech signals. Different speech processing tasks include speech recognition, speech synthesis, speaker diarization, speech enhancement, speaker recognition, etc.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.
The Viterbi algorithm is a dynamic programming algorithm for obtaining the maximum a posteriori probability estimate of the most likely sequence of hidden states—called the Viterbi path—that results in a sequence of observed events. This is done especially in the context of Markov information sources and hidden Markov models (HMM).
Lawrence R. Rabiner is an electrical engineer working in the fields of digital signal processing and speech processing; in particular in digital signal processing for automatic speech recognition. He has worked on systems for AT&T Corporation for speech recognition.
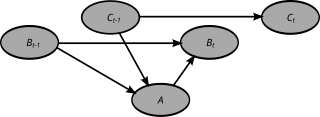
A dynamic Bayesian network (DBN) is a Bayesian network (BN) which relates variables to each other over adjacent time steps.
Multimodal interaction provides the user with multiple modes of interacting with a system. A multimodal interface provides several distinct tools for input and output of data.
A partially observable Markov decision process (POMDP) is a generalization of a Markov decision process (MDP). A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a sensor model and the underlying MDP. Unlike the policy function in MDP which maps the underlying states to the actions, POMDP's policy is a mapping from the history of observations to the actions.
Frederick Jelinek was a Czech-American researcher in information theory, automatic speech recognition, and natural language processing. He is well known for his oft-quoted statement, "Every time I fire a linguist, the performance of the speech recognizer goes up".
CMU Sphinx, also called Sphinx for short, is the general term to describe a group of speech recognition systems developed at Carnegie Mellon University. These include a series of speech recognizers and an acoustic model trainer (SphinxTrain).
Julius is a speech recognition engine, specifically a high-performance, two-pass large vocabulary continuous speech recognition (LVCSR) decoder software for speech-related researchers and developers. It can perform almost real-time computing (RTC) decoding on most current personal computers (PCs) in 60k word dictation task using word trigram (3-gram) and context-dependent Hidden Markov model (HMM). Major search methods are fully incorporated.
HTK is a proprietary software toolkit for handling HMMs. It is mainly intended for speech recognition, but has been used in many other pattern recognition applications that employ HMMs, including speech synthesis, character recognition and DNA sequencing.
In probability theory, a Markov model is a stochastic model used to model pseudo-randomly changing systems. It is assumed that future states depend only on the current state, not on the events that occurred before it. Generally, this assumption enables reasoning and computation with the model that would otherwise be intractable. For this reason, in the fields of predictive modelling and probabilistic forecasting, it is desirable for a given model to exhibit the Markov property.
Nelson Harold Morgan is an American computer scientist and professor in residence (emeritus) of electrical engineering and computer science at the University of California, Berkeley. Morgan is the co-inventor of the Relative Spectral (RASTA) approach to speech signal processing, first described in a technical report published in 1991.
Julia Hirschberg is an American computer scientist noted for her research on computational linguistics and natural language processing.
Emotion recognition is the process of identifying human emotion. People vary widely in their accuracy at recognizing the emotions of others. Use of technology to help people with emotion recognition is a relatively nascent research area. Generally, the technology works best if it uses multiple modalities in context. To date, the most work has been conducted on automating the recognition of facial expressions from video, spoken expressions from audio, written expressions from text, and physiology as measured by wearables.
Alberto Ciaramella is an Italian computer engineer and scientist. He is notable for extensive pioneering contributions in the field of speech technologies and applied natural language processing, most of them at CSELT and Loquendo, with the amount of 40 papers and four patents.
Ronjon Nag is a British-American inventor and entrepreneur specializing in the field of mobile technology. He co-founded the technology company Lexicus, acquired by Motorola in 1993 and Cellmania, acquired by Research in Motion in 2010. He later served as Vice-President of both Motorola and BlackBerry.
The IARPA Babel program developed speech recognition technology for noisy telephone conversations. The main goal of the program was to improve the performance of keyword search on languages with very little transcribed data, i.e. low-resource languages. Data from 26 languages was collected with certain languages being held-out as "surprise" languages to test the ability of the teams to rapidly build a system for a new language.
Fatmah Baothman is Saudi Arabian computer scientist who is the first woman in the Middle East with a Ph.D. in artificial intelligence. She was recently appointed the board president for the Artificial Intelligence Society. Baothman has worked over 25 years as, and is currently, an assistant professor at King Abdulaziz University Faculty of Computing & Information Technology Baothman established the women's Department which is the foundation of the Computer Science College at King Abdulaziz University, and became the first teaching assistant faculty member.
