
In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding and/or using such a code proceeds by means of Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes".

Information entropy is the average rate at which information is produced by a stochastic source of data.

In statistics, the Kolmogorov–Smirnov test is a nonparametric test of the equality of continuous, one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution, or to compare two samples. It is named after Andrey Kolmogorov and Nikolai Smirnov.
Probability theory is the branch of mathematics concerned with probability. Although there are several different probability interpretations, probability theory treats the concept in a rigorous mathematical manner by expressing it through a set of axioms. Typically these axioms formalise probability in terms of a probability space, which assigns a measure taking values between 0 and 1, termed the probability measure, to a set of outcomes called the sample space. Any specified subset of these outcomes is called an event.

In probability and statistics, a random variable, random quantity, aleatory variable, or stochastic variable is a variable whose possible values are outcomes of a random phenomenon. More specifically, a random variable is defined as a function that maps the outcomes of an unpredictable process to numerical quantities, typically real numbers. It is a variable, in the sense that it depends on the outcome of an underlying process providing the input to this function, and it is random in the sense that the underlying process is assumed to be random.
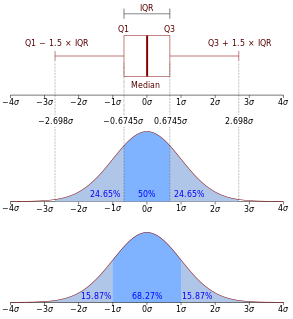
In probability theory, a probability density function (PDF), or density of a continuous random variable, is a function whose value at any given sample in the sample space can be interpreted as providing a relative likelihood that the value of the random variable would equal that sample. In other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would equal one sample compared to the other sample.

Hidden Markov Model (HMM) is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved states.
In probability theory and statistics, the Bernoulli distribution, named after Swiss mathematician Jacob Bernoulli, is the discrete probability distribution of a random variable which takes the value 1 with probability and the value 0 with probability that is, the probability distribution of any single experiment that asks a yes–no question; the question results in a boolean-valued outcome, a single bit of information whose value is success/yes/true/one with probability p and failure/no/false/zero with probability q. It can be used to represent a coin toss where 1 and 0 would represent "heads" and "tails", respectively, and p would be the probability of the coin landing on heads or tails, respectively. In particular, unfair coins would have
Unary coding, or the unary numeral system and also sometimes called thermometer code, is an entropy encoding that represents a natural number, n, with n ones followed by a zero or with n − 1 ones followed by a zero. For example 5 is represented as 111110 or 11110. Some representations use n or n − 1 zeros followed by a one. The ones and zeros are interchangeable without loss of generality. Unary coding is both a prefix-free code and a self-synchronizing code.
In statistics, Gibbs sampling or a Gibbs sampler is a Markov chain Monte Carlo (MCMC) algorithm for obtaining a sequence of observations which are approximated from a specified multivariate probability distribution, when direct sampling is difficult. This sequence can be used to approximate the joint distribution ; to approximate the marginal distribution of one of the variables, or some subset of the variables ; or to compute an integral. Typically, some of the variables correspond to observations whose values are known, and hence do not need to be sampled.
In statistics, a categorical variable is a variable that can take on one of a limited, and usually fixed number of possible values, assigning each individual or other unit of observation to a particular group or nominal category on the basis of some qualitative property. In computer science and some branches of mathematics, categorical variables are referred to as enumerations or enumerated types. Commonly, each of the possible values of a categorical variable is referred to as a level. The probability distribution associated with a random categorical variable is called a categorical distribution.
In statistics, a mixture model is a probabilistic model for representing the presence of subpopulations within an overall population, without requiring that an observed data set should identify the sub-population to which an individual observation belongs. Formally a mixture model corresponds to the mixture distribution that represents the probability distribution of observations in the overall population. However, while problems associated with "mixture distributions" relate to deriving the properties of the overall population from those of the sub-populations, "mixture models" are used to make statistical inferences about the properties of the sub-populations given only observations on the pooled population, without sub-population identity information.
In probability theory, the multinomial distribution is a generalization of the binomial distribution. For example, it models the probability of counts for rolling a k-sided die n times. For n independent trials each of which leads to a success for exactly one of k categories, with each category having a given fixed success probability, the multinomial distribution gives the probability of any particular combination of numbers of successes for the various categories.
In probability and statistics, the Dirichlet distribution, often denoted , is a family of continuous multivariate probability distributions parameterized by a vector of positive reals. It is a multivariate generalization of the beta distribution, hence its alternative name of Multivariate Beta distribution (MBD). Dirichlet distributions are commonly used as prior distributions in Bayesian statistics, and in fact the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution.
In probability theory and statistics, the Dirichlet-multinomial distribution is a family of discrete multivariate probability distributions on a finite support of non-negative integers. It is also called the Dirichlet compound multinomial distribution (DCM) or multivariate Pólya distribution. It is a compound probability distribution, where a probability vector p is drawn from a Dirichlet distribution with parameter vector , and an observation drawn from a multinomial distribution with probability vector p and number of trials n. The compounding corresponds to a Polya urn scheme. It is frequently encountered in Bayesian statistics, empirical Bayes methods and classical statistics as an overdispersed multinomial distribution.
In probability, statistics, economics, and actuarial science, the Benini distribution is a continuous probability distribution that is a statistical size distribution often applied to model incomes, severity of claims or losses in actuarial applications, and other economic data. Its tail behavior decays faster than a power law, but not as fast as an exponential. This distribution was introduced by Rodolfo Benini in 1905. Somewhat later than Benini's original work, the distribution has been independently discovered or discussed by a number of authors.

Asymmetric numeral systems (ANS) is a family of entropy encoding methods introduced by Jarosław (Jarek) Duda from Jagiellonian University, used in data compression since 2014 due to improved performance compared to previously used methods, being up to 30 times faster. ANS combines the compression ratio of arithmetic coding, with a processing cost similar to that of Huffman coding. In the tabled ANS (tANS) variant, this is achieved by constructing a finite-state machine to operate on a large alphabet without using multiplication.




