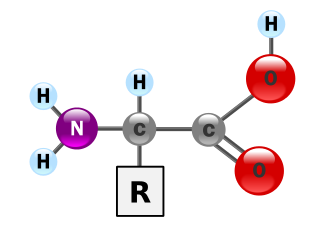
Amino acids are organic compounds that contain amine (-NH2) and carboxyl (-COOH) functional groups, along with a side chain (R group) specific to each amino acid. The key elements of an amino acid are carbon (C), hydrogen (H), oxygen (O), and nitrogen (N), although other elements are found in the side chains of certain amino acids. About 500 naturally occurring amino acids are known (though only 20 appear in the genetic code) and can be classified in many ways. They can be classified according to the core structural functional groups' locations as alpha- (α-), beta- (β-), gamma- (γ-) or delta- (δ-) amino acids; other categories relate to polarity, pH level, and side chain group type (aliphatic, acyclic, aromatic, containing hydroxyl or sulfur, etc.). In the form of proteins, amino acid residues form the second-largest component (water is the largest) of human muscles and other tissues. Beyond their role as residues in proteins, amino acids participate in a number of processes such as neurotransmitter transport and biosynthesis.

A base pair (bp) is a unit consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, Watson–Crick base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Proteins are large biomolecules, or macromolecules, consisting of one or more long chains of amino acid residues. Proteins perform a vast array of functions within organisms, including catalysing metabolic reactions, DNA replication, responding to stimuli, providing structure to cells and organisms, and transporting molecules from one location to another. Proteins differ from one another primarily in their sequence of amino acids, which is dictated by the nucleotide sequence of their genes, and which usually results in protein folding into a specific three-dimensional structure that determines its activity.

In chemistry, a zwitterion, formerly called a dipolar ion, is a molecule with two or more functional groups, of which at least one has a positive and one has a negative electrical charge and the net charge of the entire molecule is zero. Because they contain at least one positive and one negative charge, zwitterions are also sometimes called inner salts. The charges on the different functional groups balance each other out, and the molecule as a whole is electrically neutral. The pH where this happens is known as the isoelectric point.

Proline (symbol Pro or P) is a proteinogenic amino acid that is used in the biosynthesis of proteins. It contains an α-amino group (which is in the protonated NH2+ form under biological conditions), an α-carboxylic acid group (which is in the deprotonated −COO− form under biological conditions), and a side chain pyrrolidine, classifying it as a nonpolar (at physiological pH), aliphatic amino acid. It is non-essential in humans, meaning the body can synthesize it from the non-essential amino acid L-glutamate. It is encoded by all the codons starting CC (CCU, CCC, CCA, and CCG).
An acid dissociation constant, Ka, is a quantitative measure of the strength of an acid in solution. It is the equilibrium constant for a chemical reaction

Glutamic acid is an α-amino acid that is used by almost all living beings in the biosynthesis of proteins. It is non-essential in humans, meaning the body can synthesize it. It is also an excitatory neurotransmitter, in fact the most abundant one, in the vertebrate nervous system. It serves as the precursor for the synthesis of the inhibitory gamma-aminobutyric acid (GABA) in GABA-ergic neurons.

In molecular biology and genetics, translation is the process in which ribosomes in the cytoplasm or ER synthesize proteins after the process of transcription of DNA to RNA in the cell's nucleus. The entire process is called gene expression.
A biomolecule or biological molecule is a loosely used term for molecules and ions present in organisms that are essential to one or more typically biological processes, such as cell division, morphogenesis, or development. Biomolecules include large macromolecules such as proteins, carbohydrates, lipids, and nucleic acids, as well as small molecules such as primary metabolites, secondary metabolites, and natural products. A more general name for this class of material is biological materials. Biomolecules are usually endogenous, produced within the organism but organisms usually need exogenous biomolecules, for example certain nutrients, to survive.
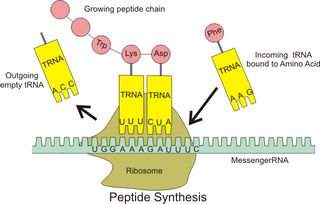
A transfer RNA is an adaptor molecule composed of RNA, typically 76 to 90 nucleotides in length, that serves as the physical link between the mRNA and the amino acid sequence of proteins. tRNA does this by carrying an amino acid to the protein synthetic machinery of a cell (ribosome) as directed by a 3-nucleotide sequence (codon) in a messenger RNA (mRNA). As such, tRNAs are a necessary component of translation, the biological synthesis of new proteins in accordance with the genetic code.
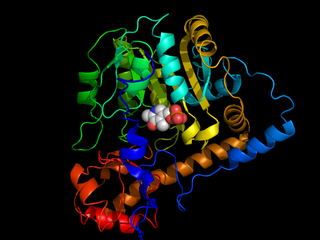
Aspartate transaminase (AST) or aspartate aminotransferase, also known as AspAT/ASAT/AAT or (serum) glutamic oxaloacetic transaminase, is a pyridoxal phosphate (PLP)-dependent transaminase enzyme that was first described by Arthur Karmen and colleagues in 1954. AST catalyzes the reversible transfer of an α-amino group between aspartate and glutamate and, as such, is an important enzyme in amino acid metabolism. AST is found in the liver, heart, skeletal muscle, kidneys, brain, and red blood cells. Serum AST level, serum ALT level, and their ratio are commonly measured clinically as biomarkers for liver health. The tests are part of blood panels.

Albumin is a family of globular proteins, the most common of which are the serum albumins. All the proteins of the albumin family are water-soluble, moderately soluble in concentrated salt solutions, and experience heat denaturation. Albumins are commonly found in blood plasma and differ from other blood proteins in that they are not glycosylated. Substances containing albumins, such as egg white, are called albuminoids.
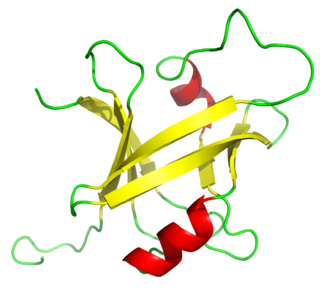
The B3 DNA binding domain (DBD) is a highly conserved domain found exclusively in transcription factors combined with other domains. It consists of 100-120 residues, includes seven beta strands and two alpha helices that form a DNA-binding pseudobarrel protein fold ; it interacts with the major groove of DNA.

Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary and quaternary.
PDBsum is a database that provides an overview of the contents of each 3D macromolecular structure deposited in the Protein Data Bank. The original version of the database was developed around 1995 by Roman Laskowski and collaborators at University College London. As of 2014, PDBsum is maintained by Laskowski and collaborators in the laboratory of Janet Thornton at the European Bioinformatics Institute (EBI).

Pedunculagin is an ellagitannin. It is formed from casuarictin via the loss of a gallate group.

Bicornin is an ellagitannin found in the Myrtales Trapa bicornis and Syzygium aromaticum (clove).

The WRKY domain is found in the WRKY transcription factor family, a class of transcription factors. The WRKY domain is found almost exclusively in plants although WRKY genes appear present in some diplomonads, social amoebae and other amoebozoa, and fungi incertae sedis. They appear absent in other non-plant species. WRKY transcription factors have been a significant area of plant research for the past 20 years. The WRKY DNA-binding domain recognizes the W-box (T)TGAC(C/T) cis-regulatory element.




