In computer programming, feature-oriented programming (FOP) or feature-oriented software development (FOSD) is a programming paradigm for program generation in software product lines (SPLs) and for incremental development of programs.
In computer programming, feature-oriented programming (FOP) or feature-oriented software development (FOSD) is a programming paradigm for program generation in software product lines (SPLs) and for incremental development of programs.

FOSD arose out of layer-based designs and levels of abstraction in network protocols and extensible database systems in the late-1980s. [1] A program was a stack of layers. Each layer added functionality to previously composed layers and different compositions of layers produced different programs. Not surprisingly, there was a need for a compact language to express such designs. Elementary algebra fit the bill: each layer was a function (a program transformation) that added new code to an existing program to produce a new program, and a program's design was modeled by an expression, i.e., a composition of transformations (layers). The figure to the left illustrates the stacking of layers i, j, and h (where h is on the bottom and i is on the top). The algebraic notations i(j(h)), i•j•h, and i+j+h have been used to express these designs.
Over time, layers were equated to features, where a feature is an increment in program functionality. The paradigm for program design and generation was recognized to be an outgrowth of relational query optimization, where query evaluation programs were defined as relational algebra expressions, and query optimization was expression optimization. [2] A software product line is a family of programs where each program is defined by a unique composition of features. FOSD has since evolved into the study of feature modularity, tools, analyses, and design techniques to support feature-based program generation.
The second generation of FOSD research was on feature interactions, which originated in telecommunications. Later, the term feature-oriented programming was coined; [3] this work exposed interactions between layers. Interactions require features to be adapted when composed with other features.
A third generation of research focussed on the fact that every program has multiple representations (e.g., source, makefiles, documentation, etc.) and adding a feature to a program should elaborate each of its representations so that all are consistent. Additionally, some of representations could be generated (or derived) from others. In the sections below, the mathematics of the three most recent generations of FOSD, namely GenVoca, [1] AHEAD, [4] and FOMDD [5] [6] are described, and links to product lines that have been developed using FOSD tools are provided. Also, four additional results that apply to all generations of FOSD are: FOSD metamodels, FOSD program cubes, and FOSD feature interactions.
GenVoca (a portmanteau of the names Genesis and Avoca) [1] is a compositional paradigm for defining programs of product lines. Base programs are 0-ary functions or transformations called values:
f -- base program with feature f h -- base program with feature h
and features are unary functions/transformations that elaborate (modify, extend, refine) a program:
i + x -- adds feature i to program x j + x -- adds feature j to program x
where + denotes function composition. The design of a program is a named expression, e.g.:
p1 = j + f -- program p1 has features j and f p2 = j + h -- program p2 has features j and h p3 = i + j + h -- program p3 has features i, j, and h
A GenVoca model of a domain or software product line is a collection of base programs and features (see MetaModels and Program Cubes). The programs (expressions) that can be created defines a product line. Expression optimization is program design optimization, and expression evaluation is program generation.
GenVoca features were originally implemented using C preprocessor (#ifdef feature ... #endif) techniques. A more advanced technique, called mixin layers, showed the connection of features to object-oriented collaboration-based designs.
Algebraic Hierarchical Equations for Application Design (AHEAD) [4] generalized GenVoca in two ways. First, it revealed the internal structure of GenVoca values as tuples. Every program has multiple representations, such as source, documentation, bytecode, and makefiles. A GenVoca value is a tuple of program representations. In a product line of parsers, for example, a base parser f is defined by its grammar gf, Java source sf, and documentation df. Parser f is modeled by the tuple f=[gf, sf, df]. Each program representation may have subrepresentations, and they too may have subrepresentations, recursively. In general, a GenVoca value is a tuple of nested tuples that define a hierarchy of representations for a particular program.
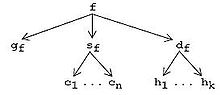
Example. Suppose terminal representations are files. In AHEAD, grammar gf corresponds to a single BNF file, source sf corresponds to a tuple of Java files [c1…cn], and documentation df is a tuple of HTML files [h1…hk]. A GenVoca value (nested tuples) can be depicted as a directed graph: the graph for parser f is shown in the figure to the right. Arrows denote projections, i.e., mappings from a tuple to one of its components. AHEAD implements tuples as file directories, so f is a directory containing file gf and subdirectories sf and df. Similarly, directory sf contains files c1…cn, and directory df contains files h1…hk.
Second, AHEAD expresses features as nested tuples of unary functions called deltas. Deltas can be program refinements (semantics-preserving transformations), extensions (semantics-extending transformations), or interactions (semantics-altering transformations). We use the neutral term “delta” to represent all of these possibilities, as each occurs in FOSD.
To illustrate, suppose feature j extends a grammar by Δgj (new rules and tokens are added), extends source code by Δsj (new classes and members are added and existing methods are modified), and extends documentation by Δdj. The tuple of deltas for feature j is modeled by j=[Δgj,Δsj,Δdj], which we call a delta tuple. Elements of delta tuples can themselves be delta tuples. Example: Δsj represents the changes that are made to each class in sf by feature j, i.e., Δsj=[Δc1…Δcn]. The representations of a program are computed recursively by nested vector addition. The representations for parser p2 (whose GenVoca expression is j+f) are:
p2 = j + f -- GenVoca expression = [Δgj, Δsj, Δdj] + [gf, sf, df] -- substitution = [Δgj+gf, Δsj+sf, Δdj+df] -- compose tuples element-wise
That is, the grammar of p2 is the base grammar composed with its extension (Δgj+gf), the source of p2 is the base source composed with its extension (Δsj+sf), and so on. As elements of delta tuples can themselves be delta tuples, composition recurses, e.g., Δsj+sf= [Δc1…Δcn]+[c1…cn]=[Δc1+c1…Δcn+cn]. Summarizing, GenVoca values are nested tuples of program artifacts, and features are nested delta tuples, where + recursively composes them by vector addition. This is the essence of AHEAD.
The ideas presented above concretely expose two FOSD principles. The Principle of Uniformity states that all program artifacts are treated and modified in the same way. (This is evidenced by deltas for different artifact types above). The Principle of Scalability states all levels of abstractions are treated uniformly. (This gives rise to the hierarchical nesting of tuples above).
The original implementation of AHEAD is the AHEAD Tool Suite and Jak language, which exhibits both the Principles of Uniformity and Scalability. Next-generation tools include CIDE [10] and FeatureHouse. [11]

Feature-Oriented Model-Driven Design (FOMDD) [5] [6] combines the ideas of AHEAD with Model-Driven Design (MDD) (a.k.a. Model-Driven Architecture (MDA)). AHEAD functions capture the lockstep update of program artifacts when a feature is added to a program. But there are other functional relationships among program artifacts that express derivations. For example, the relationship between a grammar gf and its parser source sf is defined by a compiler-compiler tool, e.g., javacc. Similarly, the relationship between Java source sf and its bytecode bf is defined by the javac compiler. A commuting diagram expresses these relationships. Objects are program representations, downward arrows are derivations, and horizontal arrows are deltas. The figure to the right shows the commuting diagram for program p3 = i+j+h = [g3,s3,b3].
A fundamental property of a commuting diagram is that all paths between two objects are equivalent. For example, one way to derive the bytecode b3 of parser p3 (lower right object in the figure to the right) from grammar gh of parser h (upper left object) is to derive the bytecode bh and refine to b3, while another way refines gh to g3, and then derive b3, where + represents delta composition and () is function or tool application:
There are possible paths to derive the bytecode b3 of parser p3 from the grammar gh of parser h. Each path represents a metaprogram whose execution generates the target object (b3) from the starting object (gf). There is a potential optimization: traversing each arrow of a commuting diagram has a cost. The cheapest (i.e., shortest) path between two objects in a commuting diagram is a geodesic, which represents the most efficient metaprogram that produces the target object from a given object.
Commuting diagrams are important for at least two reasons: (1) there is the possibility of optimizing the generation of artifacts (e.g., geodesics) and (2) they specify different ways of constructing a target object from a starting object. [5] [12] A path through a diagram corresponds to a tool chain: for an FOMDD model to be consistent, it should be proven (or demonstrated through testing) that all tool chains that map one object to another in fact yield equivalent results. If this is not the case, then either there is a bug in one or more of the tools or the FOMDD model is wrong.
In computing, a compiler is a computer program that translates computer code written in one programming language into another language. The name "compiler" is primarily used for programs that translate source code from a high-level programming language to a low-level programming language to create an executable program.
In computer science, the Earley parser is an algorithm for parsing strings that belong to a given context-free language, though it may suffer problems with certain nullable grammars. The algorithm, named after its inventor, Jay Earley, is a chart parser that uses dynamic programming; it is mainly used for parsing in computational linguistics. It was first introduced in his dissertation in 1968.
Eiffel is an object-oriented programming language designed by Bertrand Meyer and Eiffel Software. Meyer conceived the language in 1985 with the goal of increasing the reliability of commercial software development; the first version becoming available in 1986. In 2005, Eiffel became an ISO-standardized language.

The GNU Compiler Collection (GCC) is an optimizing compiler produced by the GNU Project supporting various programming languages, hardware architectures and operating systems. The Free Software Foundation (FSF) distributes GCC as free software under the GNU General Public License. GCC is a key component of the GNU toolchain and the standard compiler for most projects related to GNU and the Linux kernel. With roughly 15 million lines of code in 2019, GCC is one of the biggest free programs in existence. It has played an important role in the growth of free software, as both a tool and an example.

In computer science, an interpreter is a computer program that directly executes instructions written in a programming or scripting language, without requiring them previously to have been compiled into a machine language program. An interpreter generally uses one of the following strategies for program execution:
Parrot is a discontinued register-based process virtual machine designed to run dynamic languages efficiently. It is possible to compile Parrot assembly language and Parrot intermediate representation to Parrot bytecode and execute it. Parrot is free and open-source software.
In computer science, a compiler-compiler or compiler generator is a programming tool that creates a parser, interpreter, or compiler from some form of formal description of a programming language and machine.
Bytecode is a form of instruction set designed for efficient execution by a software interpreter. Unlike human-readable source code, bytecodes are compact numeric codes, constants, and references that encode the result of compiler parsing and performing semantic analysis of things like type, scope, and nesting depths of program objects.
In computing, just-in-time (JIT) compilation is compilation during execution of a program rather than before execution. This may consist of source code translation but is more commonly bytecode translation to machine code, which is then executed directly. A system implementing a JIT compiler typically continuously analyses the code being executed and identifies parts of the code where the speedup gained from compilation or recompilation would outweigh the overhead of compiling that code.
Grammar theory to model symbol strings originated from work in computational linguistics aiming to understand the structure of natural languages. Probabilistic context free grammars (PCFGs) have been applied in probabilistic modeling of RNA structures almost 40 years after they were introduced in computational linguistics.
Top-down parsing in computer science is a parsing strategy where one first looks at the highest level of the parse tree and works down the parse tree by using the rewriting rules of a formal grammar. LL parsers are a type of parser that uses a top-down parsing strategy.

Factor is a stack-oriented programming language created by Slava Pestov. Factor is dynamically typed and has automatic memory management, as well as powerful metaprogramming features. The language has a single implementation featuring a self-hosted optimizing compiler and an interactive development environment. The Factor distribution includes a large standard library.
An intermediate representation (IR) is the data structure or code used internally by a compiler or virtual machine to represent source code. An IR is designed to be conducive to further processing, such as optimization and translation. A "good" IR must be accurate – capable of representing the source code without loss of information – and independent of any particular source or target language. An IR may take one of several forms: an in-memory data structure, or a special tuple- or stack-based code readable by the program. In the latter case it is also called an intermediate language.
Feature-oriented software development (FOSD) is a general paradigm for software generation, where a model of a product line is a tuple of 0-ary and 1-ary functions. This page discusses a more abstract concept of models of product lines of product lines (PL**2) called metamodels, and product lines of product lines of product lines called meta-metamodels (PL**3), and further abstract concepts.
Feature-oriented programming or feature-oriented software development (FOSD) is a general paradigm for program synthesis in software product lines. The feature-oriented programming page is recommended, it explains how an FOSD model of a domain is a tuple of 0-ary functions and a set of 1-ary (unary) functions called features. This page discusses multidimensional generalizations of FOSD models, which are important for compact specifications of complex programs.
The key implementation technique of GenVoca is due to Smaragdakis called mixin-layers.

In computing, a compiler is a computer program that transforms source code written in a programming language or computer language, into another computer language. The most common reason for transforming source code is to create an executable program.
Vowpal Wabbit (VW) is an open-source fast online interactive machine learning system library and program developed originally at Yahoo! Research, and currently at Microsoft Research. It was started and is led by John Langford. Vowpal Wabbit's interactive learning support is particularly notable including Contextual Bandits, Active Learning, and forms of guided Reinforcement Learning. Vowpal Wabbit provides an efficient scalable out-of-core implementation with support for a number of machine learning reductions, importance weighting, and a selection of different loss functions and optimization algorithms.
In machine learning and computer vision, M-theory is a learning framework inspired by feed-forward processing in the ventral stream of visual cortex and originally developed for recognition and classification of objects in visual scenes. M-theory was later applied to other areas, such as speech recognition. On certain image recognition tasks, algorithms based on a specific instantiation of M-theory, HMAX, achieved human-level performance.
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.
