Corpus linguistics is an empirical method for the study of language by way of a text corpus. Corpora are balanced, often stratified collections of authentic, "real world", text of speech or writing that aim to represent a given linguistic variety. Today, corpora are generally machine-readable data collections.
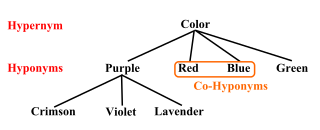
Hypernymy and hyponymy are the semantic relations between a generic term (hypernym) and a more specific term (hyponym). The hypernym is also called a supertype, umbrella term, or blanket term. The hyponym names a subtype of the hypernym. The semantic field of the hyponym is included within that of the hypernym. For example, pigeon, crow, and hen are all hyponyms of bird and animal; bird and animal are both hypernyms of pigeon, crow, and hen.
Readability is the ease with which a reader can understand a written text. The concept exists in both natural language and programming languages though in different forms. In natural language, the readability of text depends on its content and its presentation. In programming, things such as programmer comments, choice of loop structure, and choice of names can determine the ease with which humans can read computer program code.

Second language writing is the study of writing performed by non-native speakers/writers of a language as a second or foreign language. According to Oxford University, second language writing is the expression of one's actions and what one wants to say in writing in a language other than one's native language. The process of second language writing has been an area of research in applied linguistics and second language acquisition theory since the middle of the 20th century. The focus has been mainly on second-language writing in academic settings.
Stylometry is the application of the study of linguistic style, usually to written language. It has also been applied successfully to music, paintings, and chess.
The sequence between semantic related ordered words is classified as a lexical chain. A lexical chain is a sequence of related words in writing, spanning narrow or wide context window. A lexical chain is independent of the grammatical structure of the text and in effect it is a list of words that captures a portion of the cohesive structure of the text. A lexical chain can provide a context for the resolution of an ambiguous term and enable disambiguation of concepts that the term represents.
Beryl T. "Sue" Atkins was a British lexicographer, specialising in computational lexicography, who pioneered the creation of bilingual dictionaries from corpus data.

Distributional semantics is a research area that develops and studies theories and methods for quantifying and categorizing semantic similarities between linguistic items based on their distributional properties in large samples of language data. The basic idea of distributional semantics can be summed up in the so-called distributional hypothesis: linguistic items with similar distributions have similar meanings.
Kathleen Bardovi-Harlig is an American linguist. She is currently Provost Professor and ESL Coordinator at Indiana University (Bloomington).
Linguistic categories include
Computational lexicology is a branch of computational linguistics, which is concerned with the use of computers in the study of lexicon. It has been more narrowly described by some scholars as the use of computers in the study of machine-readable dictionaries. It is distinguished from computational lexicography, which more properly would be the use of computers in the construction of dictionaries, though some researchers have used computational lexicography as synonymous.
Coh-Metrix is a computational tool that produces indices of the linguistic and discourse representations of a text. Developed by Arthur C. Graesser and Danielle S. McNamara, Coh-Metrix analyzes texts on many different features.
In the fields of computational linguistics and applied linguistics, a morphological dictionary is a linguistic resource that contains correspondences between surface form and lexical forms of words. Surface forms of words are those found in natural language text. The corresponding lexical form of a surface form is the lemma followed by grammatical information. In English give, gives, giving, gave and given are surface forms of the verb give. The lexical form would be "give", verb. There are two kinds of morphological dictionaries: morpheme-aligned dictionaries and full-form (non-aligned) dictionaries.
Norbert Schmitt is an American applied linguist and Emeritus Professor of Applied Linguistics at the University of Nottingham in the United Kingdom. He is known for his work on second-language vocabulary acquisition and second-language vocabulary teaching. He has published numerous books and papers on vocabulary acquisition.

Marjolijn Verspoor is a Dutch linguist. She is a professor of English language and English as a second language at the University of Groningen, Netherlands. She is known for her work on Complex Dynamic Systems Theory and the application of dynamical systems theory to study second language development. Her interest is also in second language writing.

Rosa María Manchón Ruiz is a Spanish linguist. She is currently a professor of applied linguistics at the University of Murcia, Spain. Her research focuses on second language acquisition and second language writing. She was the editor of the Journal of Second Language Writing between 2008 and 2014.
L2 Syntactical Complexity Analyzer (L2SCA) developed by Xiaofei Lu at the Pennsylvania State University, is a computational tool which produces syntactic complexity indices of written English language texts. Along with Coh-Metrix, the L2SCA is one of the most extensively used computational tool to compute indices of second language writing development. The L2SCA is also widely utilised in the field of corpus linguistics. The L2SCA is available in a single and a batch mode. The first provides the possibility of analyzing a single written text for 14 syntactic complexity indices. The latter allows the user to analyze 30 written texts simultaneously.
Scott Jarvis is an American linguist. He is a Professor of Applied Linguistics at Northern Arizona University, United States. His research focuses on second language acquisition more broadly, with a special focus on lexical diversity.
Danielle S. McNamara is an educational researcher known for her theoretical and empirical work with reading comprehension and the development of game-based literacy technologies. She is professor of psychology and senior research scientist at Arizona State University. She has previously held positions at University of Memphis, Old Dominion University, and University of Colorado, Boulder.
In linguistics and language technology, a language resource is a "[composition] of linguistic material used in the construction, improvement and/or evaluation of language processing applications, (...) in language and language-mediated research studies and applications."