Accuracy and precision are two measures of observational error. Accuracy is how close a given set of measurements are to their true value, while precision is how close the measurements are to each other.

A decision tree is a decision support hierarchical model that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm that only contains conditional control statements.
In the field of machine learning and specifically the problem of statistical classification, a confusion matrix, also known as error matrix, is a specific table layout that allows visualization of the performance of an algorithm, typically a supervised learning one; in unsupervised learning it is usually called a matching matrix.
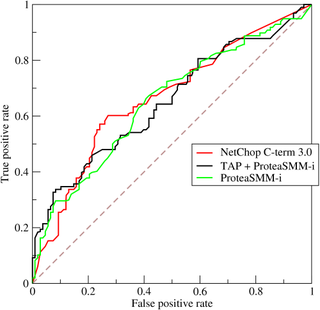
A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the performance of a binary classifier model at varying threshold values.

The positive and negative predictive values are the proportions of positive and negative results in statistics and diagnostic tests that are true positive and true negative results, respectively. The PPV and NPV describe the performance of a diagnostic test or other statistical measure. A high result can be interpreted as indicating the accuracy of such a statistic. The PPV and NPV are not intrinsic to the test ; they depend also on the prevalence. Both PPV and NPV can be derived using Bayes' theorem.
Cohen's kappa coefficient is a statistic that is used to measure inter-rater reliability for qualitative (categorical) items. It is generally thought to be a more robust measure than simple percent agreement calculation, as κ takes into account the possibility of the agreement occurring by chance. There is controversy surrounding Cohen's kappa due to the difficulty in interpreting indices of agreement. Some researchers have suggested that it is conceptually simpler to evaluate disagreement between items.
Given a population whose members each belong to one of a number of different sets or classes, a classification rule or classifier is a procedure by which the elements of the population set are each predicted to belong to one of the classes. A perfect classification is one for which every element in the population is assigned to the class it really belongs to. The bayes classifier is the classifier which assigns classes optimally based on the known attributes of the elements to be classified.

In statistical analysis of binary classification and information retrieval systems, the F-score or F-measure is a measure of predictive performance. It is calculated from the precision and recall of the test, where the precision is the number of true positive results divided by the number of all samples predicted to be positive, including those not identified correctly, and the recall is the number of true positive results divided by the number of all samples that should have been identified as positive. Precision is also known as positive predictive value, and recall is also known as sensitivity in diagnostic binary classification.

The Rand index or Rand measure in statistics, and in particular in data clustering, is a measure of the similarity between two data clusterings. A form of the Rand index may be defined that is adjusted for the chance grouping of elements, this is the adjusted Rand index. The Rand index is the accuracy of determining if a link belongs within a cluster or not.
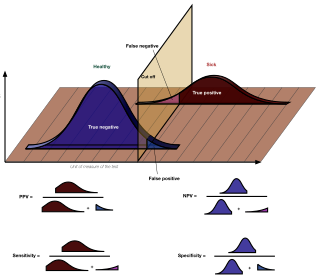
In medicine and statistics, sensitivity and specificity mathematically describe the accuracy of a test that reports the presence or absence of a medical condition. If individuals who have the condition are considered "positive" and those who do not are considered "negative", then sensitivity is a measure of how well a test can identify true positives and specificity is a measure of how well a test can identify true negatives:
Youden's J statistic is a single statistic that captures the performance of a dichotomous diagnostic test. (Bookmaker) Informedness is its generalization to the multiclass case and estimates the probability of an informed decision.
In pattern recognition, information retrieval, object detection and classification, precision and recall are performance metrics that apply to data retrieved from a collection, corpus or sample space.
In statistics, the phi coefficient is a measure of association for two binary variables.

In medical testing with binary classification, the diagnostic odds ratio (DOR) is a measure of the effectiveness of a diagnostic test. It is defined as the ratio of the odds of the test being positive if the subject has a disease relative to the odds of the test being positive if the subject does not have the disease.
The Fowlkes–Mallows index is an external evaluation method that is used to determine the similarity between two clusterings, and also a metric to measure confusion matrices. This measure of similarity could be either between two hierarchical clusterings or a clustering and a benchmark classification. A higher value for the Fowlkes–Mallows index indicates a greater similarity between the clusters and the benchmark classifications. It was invented by Bell Labs statisticians Edward Fowlkes and Collin Mallows in 1983.
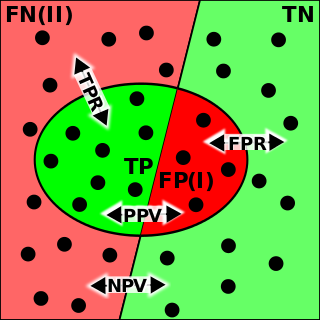
The evaluation of binary classifiers compares two methods of assigning a binary attribute, one of which is usually a standard method and the other is being investigated. There are many metrics that can be used to measure the performance of a classifier or predictor; different fields have different preferences for specific metrics due to different goals. For example, in medicine sensitivity and specificity are often used, while in computer science precision and recall are preferred. An important distinction is between metrics that are independent on the prevalence, and metrics that depend on the prevalence – both types are useful, but they have very different properties.

The discipline of forensic epidemiology (FE) is a hybrid of principles and practices common to both forensic medicine and epidemiology. FE is directed at filling the gap between clinical judgment and epidemiologic data for determinations of causality in civil lawsuits and criminal prosecution and defense.
Fairness in machine learning refers to the various attempts at correcting algorithmic bias in automated decision processes based on machine learning models. Decisions made by computers after a machine-learning process may be considered unfair if they were based on variables considered sensitive. For example gender, ethnicity, sexual orientation or disability. As it is the case with many ethical concepts, definitions of fairness and bias are always controversial. In general, fairness and bias are considered relevant when the decision process impacts people's lives. In machine learning, the problem of algorithmic bias is well known and well studied. Outcomes may be skewed by a range of factors and thus might be considered unfair with respect to certain groups or individuals. An example would be the way social media sites deliver personalized news to consumers.
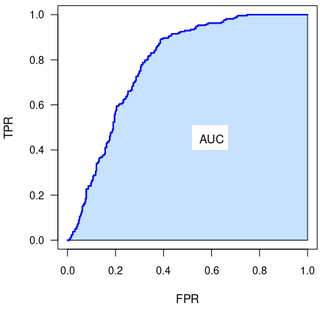
The Partial Area Under the ROC Curve (pAUC) is a metric for the performance of binary classifier.
P4 metric enables performance evaluation of the binary classifier. It is calculated from precision, recall, specificity and NPV (negative predictive value). P4 is designed in similar way to F1 metric, however addressing the criticisms leveled against F1. It may be perceived as its extension.
