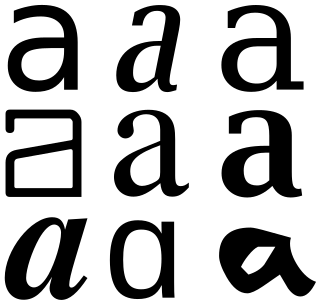
A glyph is any kind of purposeful mark. In typography, a glyph is "the specific shape, design, or representation of a character". It is a particular graphical representation, in a particular typeface, of an element of written language. A grapheme, or part of a grapheme, or sometimes several graphemes in combination can be represented by a glyph.
ISO/IEC 8859 is a joint ISO and IEC series of standards for 8-bit character encodings. The series of standards consists of numbered parts, such as ISO/IEC 8859-1, ISO/IEC 8859-2, etc. There are 15 parts, excluding the abandoned ISO/IEC 8859-12. The ISO working group maintaining this series of standards has been disbanded.

Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene photo or from subtitle text superimposed on an image.

A typeface is a design of letters, numbers and other symbols, to be used in printing or for electronic display. Most typefaces include variations in size, weight, slope, width, and so on. Each of these variations of the typeface is a font.
A cedilla, or cedille, is a hook or tail added under certain letters as a diacritical mark to modify their pronunciation. In Catalan, French, and Portuguese it is used only under the letter c, and the entire letter is called, respectively, c trencada, c cédille, and c cedilhado. It is used to mark vowel nasalization in many languages of sub-Saharan Africa, including Vute from Cameroon.
Han unification is an effort by the authors of Unicode and the Universal Character Set to map multiple character sets of the Han characters of the so-called CJK languages into a single set of unified characters. Han characters are a feature shared in common by written Chinese (hanzi), Japanese (kanji), Korean (hanja) and Vietnamese.
Magnetic ink character recognition code, known in short as MICR code, is a character recognition technology used mainly by the banking industry to streamline the processing and clearance of cheques and other documents. MICR encoding, called the MICR line, is at the bottom of cheques and other vouchers and typically includes the document-type indicator, bank code, bank account number, cheque number, cheque amount, and a control indicator. The format for the bank code and bank account number is country-specific.

The Romanian alphabet is a variant of the Latin alphabet used for writing the Romanian language. It is a modification of the classical Latin alphabet and consists of 31 letters, five of which have been modified from their Latin originals for the phonetic requirements of the language:
Wingdings is a series of dingbat fonts that render letters as a variety of symbols. They were originally developed in 1990 by Microsoft by combining glyphs from Lucida Icons, Arrows, and Stars licensed from Charles Bigelow and Kris Holmes. Certain versions of the font's copyright string include attribution to Type Solutions, Inc., the maker of a tool used to hint the font.

Code page 437 is the character set of the original IBM PC. It is also known as CP437, OEM-US, OEM 437, PC-8, or DOS Latin US. The set includes all printable ASCII characters as well as some accented letters (diacritics), Greek letters, icons, and line-drawing symbols. It is sometimes referred to as the "OEM font" or "high ASCII", or as "extended ASCII".

Bitstream Cyberbit is a commercial serif Unicode font designed by Bitstream Inc. It is freeware for non-commercial uses. It was one of the first widely available fonts to support a large portion of the Unicode repertoire.
Segoe is a typeface, or family of fonts, that is best known for its use by Microsoft. The company uses Segoe in its online and printed marketing materials, including recent logos for a number of products. Additionally, the Segoe UI font sub-family is used by numerous Microsoft applications, and may be installed by applications. It was adopted as Microsoft's default operating system font beginning with Windows Vista, and is also used on Outlook.com, Microsoft's web-based email service. In August 2012, Microsoft unveiled its new corporate logo typeset in Segoe, replacing the logo it had used for the previous 25 years.
A Unicode font is a computer font that maps glyphs to code points defined in the Unicode Standard. The vast majority of modern computer fonts use Unicode mappings, even those fonts which only include glyphs for a single writing system, or even only support the basic Latin alphabet. Fonts which support a wide range of Unicode scripts and Unicode symbols are sometimes referred to as "pan-Unicode fonts", although as the maximum number of glyphs that can be defined in a TrueType font is restricted to 65,535, it is not possible for a single font to provide individual glyphs for all defined Unicode characters. This article lists some widely used Unicode fonts that support a comparatively large number and broad range of Unicode characters.

Microsoft Sans Serif is a sans-serif typeface introduced with early Microsoft Windows versions. It is the successor of MS Sans Serif, formerly Helv, a proportional bitmap font introduced in Windows 1.0. Both typefaces are very similar in design to Arial and Helvetica. The typeface was designed to match the MS Sans bitmap included in the early releases of Microsoft Windows.

The Unicode Consortium and the ISO/IEC JTC 1/SC 2/WG 2 jointly collaborate on the list of the characters in the Universal Coded Character Set. The Universal Coded Character Set, most commonly called the Universal Character Set, is an international standard to map characters, discrete symbols used in natural language, mathematics, music, and other domains, to unique machine-readable data values. By creating this mapping, the UCS enables computer software vendors to interoperate, and transmit—interchange—UCS-encoded text strings from one to another. Because it is a universal map, it can be used to represent multiple languages at the same time. This avoids the confusion of using multiple legacy character encodings, which can result in the same sequence of codes having multiple interpretations depending on the character encoding in use, resulting in mojibake if the wrong one is chosen.

OCR-A is a font issued in 1966 and first implemented in 1968. A special font was needed in the early days of computer optical character recognition, when there was a need for a font that could be recognized not only by the computers of that day, but also by humans. OCR-A uses simple, thick strokes to form recognizable characters. The font is monospaced (fixed-width), with the printer required to place glyphs 0.254 cm apart, and the reader required to accept any spacing between 0.2286 cm and 0.4572 cm.

Extended ASCII is a repertoire of character encodings that include the original 96 ASCII character set, plus up to 128 additional characters. There is no formal definition of "extended ASCII", and even use of the term is sometimes criticized, because it can be mistakenly interpreted to mean that the American National Standards Institute (ANSI) had updated its ANSI X3.4-1986 standard to include more characters, or that the term identifies a single unambiguous encoding, neither of which is the case.
The ISO basic Latin alphabet is an international standard for a Latin-script alphabet that consists of two sets of 26 letters, codified in various national and international standards and used widely in international communication. They are the same letters that comprise the current English alphabet. Since medieval times, they are also the same letters of the modern Latin alphabet. The order is also important for sorting words into alphabetical order.
The ISO 2033:1983 standard defines character sets for use with Optical Character Recognition or Magnetic Ink Character Recognition systems. The Japanese standard JIS X 9010:1984 is closely related.

