Chymotrypsin (EC 3.4.21.1, chymotrypsins A and B, alpha-chymar ophth, avazyme, chymar, chymotest, enzeon, quimar, quimotrase, alpha-chymar, alpha-chymotrypsin A, alpha-chymotrypsin) is a digestive enzyme component of pancreatic juice acting in the duodenum, where it performs proteolysis, the breakdown of proteins and polypeptides. Chymotrypsin preferentially cleaves peptide amide bonds where the side chain of the amino acid N-terminal to the scissile amide bond (the P1 position) is a large hydrophobic amino acid (tyrosine, tryptophan, and phenylalanine). These amino acids contain an aromatic ring in their side chain that fits into a hydrophobic pocket (the S1 position) of the enzyme. It is activated in the presence of trypsin. The hydrophobic and shape complementarity between the peptide substrate P1 side chain and the enzyme S1 binding cavity accounts for the substrate specificity of this enzyme. Chymotrypsin also hydrolyzes other amide bonds in peptides at slower rates, particularly those containing leucine at the P1 position.
Hydrolysis is any chemical reaction in which a molecule of water breaks one or more chemical bonds. The term is used broadly for substitution, elimination, and solvation reactions in which water is the nucleophile.

Protein primary structure is the linear sequence of amino acids in a peptide or protein. By convention, the primary structure of a protein is reported starting from the amino-terminal (N) end to the carboxyl-terminal (C) end. Protein biosynthesis is most commonly performed by ribosomes in cells. Peptides can also be synthesized in the laboratory. Protein primary structures can be directly sequenced, or inferred from DNA sequences.

Trypsin is an enzyme in the first section of the small intestine that starts the digestion of protein molecules by cutting long chains of amino acids into smaller pieces. It is a serine protease from the PA clan superfamily, found in the digestive system of many vertebrates, where it hydrolyzes proteins. Trypsin is formed in the small intestine when its proenzyme form, the trypsinogen produced by the pancreas, is activated. Trypsin cuts peptide chains mainly at the carboxyl side of the amino acids lysine or arginine. It is used for numerous biotechnological processes. The process is commonly referred to as trypsinogen proteolysis or trypsinization, and proteins that have been digested/treated with trypsin are said to have been trypsinized.

A protease is an enzyme that catalyzes proteolysis, breaking down proteins into smaller polypeptides or single amino acids, and spurring the formation of new protein products. They do this by cleaving the peptide bonds within proteins by hydrolysis, a reaction where water breaks bonds. Proteases are involved in numerous biological pathways, including digestion of ingested proteins, protein catabolism, and cell signaling.

In biology and biochemistry, the active site is the region of an enzyme where substrate molecules bind and undergo a chemical reaction. The active site consists of amino acid residues that form temporary bonds with the substrate, the binding site, and residues that catalyse a reaction of that substrate, the catalytic site. Although the active site occupies only ~10–20% of the volume of an enzyme, it is the most important part as it directly catalyzes the chemical reaction. It usually consists of three to four amino acids, while other amino acids within the protein are required to maintain the tertiary structure of the enzymes.
Serine proteases are enzymes that cleave peptide bonds in proteins. Serine serves as the nucleophilic amino acid at the (enzyme's) active site. They are found ubiquitously in both eukaryotes and prokaryotes. Serine proteases fall into two broad categories based on their structure: chymotrypsin-like (trypsin-like) or subtilisin-like.

A metalloproteinase, or metalloprotease, is any protease enzyme whose catalytic mechanism involves a metal. An example is ADAM12 which plays a significant role in the fusion of muscle cells during embryo development, in a process known as myogenesis.
DD-Transpeptidase is a bacterial enzyme that catalyzes the transfer of the R-L-αα-D-alanyl moiety of R-L-αα-D-alanyl-D-alanine carbonyl donors to the γ-OH of their active-site serine and from this to a final acceptor. It is involved in bacterial cell wall biosynthesis, namely, the transpeptidation that crosslinks the peptide side chains of peptidoglycan strands.
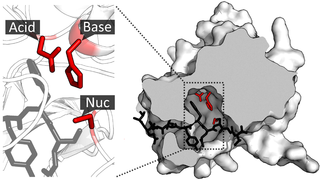
A catalytic triad is a set of three coordinated amino acids that can be found in the active site of some enzymes. Catalytic triads are most commonly found in hydrolase and transferase enzymes. An acid-base-nucleophile triad is a common motif for generating a nucleophilic residue for covalent catalysis. The residues form a charge-relay network to polarise and activate the nucleophile, which attacks the substrate, forming a covalent intermediate which is then hydrolysed to release the product and regenerate free enzyme. The nucleophile is most commonly a serine or cysteine amino acid, but occasionally threonine or even selenocysteine. The 3D structure of the enzyme brings together the triad residues in a precise orientation, even though they may be far apart in the sequence.
A metalloexopeptidase is a type of enzyme that acts as a metalloproteinase exopeptidase. These enzymes have a catalytic mechanism involving a metal, often zinc. They function in molecular biology as agents that cut the terminal peptide bonds ending peptide chains. Analogous to slicing the end off a loaf of bread, the process releases a single amino acid for use.

An isopeptide bond is a type of amide bond formed between a carboxyl group of one amino acid and an amino group of another. An isopeptide bond is the linkage between the side chain amino or carboxyl group of one amino acid to the α-carboxyl, α-amino group, or the side chain of another amino acid. In a typical peptide bond, also known as eupeptide bond, the amide bond always forms between the α-carboxyl group of one amino acid and the α-amino group of the second amino acid. Isopeptide bonds are rarer than regular peptide bonds. Isopeptide bonds lead to branching in the primary sequence of a protein. Proteins formed from normal peptide bonds typically have a linear primary sequence.
Serine hydrolases are one of the largest known enzyme classes comprising approximately ~200 enzymes or 1% of the genes in the human proteome. A defining characteristic of these enzymes is the presence of a particular serine at the active site, which is used for the hydrolysis of substrates. The hydrolysis of the ester or peptide bond proceeds in two steps. First, the acyl part of the substrate is transferred to the serine, making a new ester or amide bond and releasing the other part of the substrate is released. Later, in a slower step, the bond between the serine and the acyl group is hydrolyzed by water or hydroxide ion, regenerating free enzyme. Unlike other, non-catalytic, serines, the reactive serine of these hydrolases is typically activated by a proton relay involving a catalytic triad consisting of the serine, an acidic residue and a basic residue, although variations on this mechanism exist.
Carboxypeptidase A usually refers to the pancreatic exopeptidase that hydrolyzes peptide bonds of C-terminal residues with aromatic or aliphatic side-chains. Most scientists in the field now refer to this enzyme as CPA1, and to a related pancreatic carboxypeptidase as CPA2.
In enzymology, an aminoacylase (EC 3.5.1.14) is an enzyme that catalyzes the chemical reaction

Xaa-Pro dipeptidase, also known as prolidase, is an enzyme that in humans is encoded by the PEPD gene. Prolidase is an enzyme in humans that plays a crucial role in protein metabolism and collagen recycling through the catalysis of the rate-limiting step in these chemical reactions. This enzyme is coded by the gene PEPD, located on chromosome 19. Serum prolidase activity is also currently being explored as a biomarker for diseases.

OmpT is an aspartyl protease found on the outer membrane of Escherichia coli. OmpT is a subtype of the family of omptin proteases, which are found on some gram-negative species of bacteria.
Peptidyl-dipeptidase Dcp (EC 3.4.15.5, dipeptidyl carboxypeptidase (Dcp), dipeptidyl carboxypeptidase) is a metalloenzyme found in the cytoplasm of bacterium E. Coli responsible for the C-terminal cleavage of a variety of dipeptides and unprotected larger peptide chains. The enzyme does not hydrolyze bonds in which P1' is Proline, or both P1 and P1' are Glycine. Dcp consists of 680 amino acid residues that form into a single active monomer which aids in the intracellular degradation of peptides. Dcp coordinates to divalent zinc which sits in the pocket of the active site and is composed of four subsites: S1’, S1, S2, and S3, each subsite attracts certain amino acids at a specific position on the substrate enhancing the selectivity of the enzyme. The four subsites detect and bind different amino acid types on the substrate peptide in the P1 and P2 positions. Some metallic divalent cations such as Ni+2, Cu+2, and Zn+2 inhibit the function of the enzyme around 90%, whereas other cations such as Mn+2, Ca+2, Mg+2, and Co+2 have slight catalyzing properties, and increase the function by around 20%. Basic amino acids such as Arginine bind preferably at the S1 site, the S2 site sits deeper in the enzyme therefore is restricted to bind hydrophobic amino acids with phenylalanine in the P2 position. Dcp is divided into two subdomains (I, and II), which are the two sides of the clam shell-like structure and has a deep inner cavity where a pair of histidine residues bind to the catalytic zinc ion in the active site. Peptidyl-Dipeptidase Dcp is classified like Angiotensin-I converting enzyme (ACE) which is also a carboxypeptidase involved in blood pressure regulation, but due to structural differences and peptidase activity between these two enzymes they had to be examined separately. ACE has endopeptidase activity, whereas Dcp strictly has exopeptidase activity based on its cytoplasmic location and therefore their mechanisms of action are differentiated. Another difference between these enzymes is that the activity of Peptidyl-Dipeptidase Dcp is not enhanced in the presence of chloride anions, whereas chloride enhances ACE activity.
Lysine carboxypeptidase is an enzyme. This enzyme catalyses the following chemical reaction:

Nosiheptide is a thiopeptide antibiotic produced by the bacterium Streptomyces actuosus.
