Classifications
The four initial classifications defined by Flynn are based upon the number of concurrent instruction (or control) streams and data streams available in the architecture. [4] Flynn defined three additional sub-categories of SIMD in 1972. [2]
| Flynn's taxonomy |
|---|
| Single data stream |
| Multiple data streams |
| SIMD subcategories [5] |
| See also |
Single instruction stream, single data stream (SISD)
A sequential computer which exploits no parallelism in either the instruction or data streams. Single control unit (CU) fetches a single instruction stream (IS) from memory. The CU then generates appropriate control signals to direct a single processing element (PE) to operate on a single data stream (DS) i.e., one operation at a time.
Examples of SISD architectures are the traditional uniprocessor machines such as older personal computers (PCs) (by 2010, many PCs had multiple cores) and older mainframe computers.
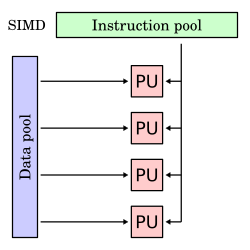
Single instruction stream, multiple data streams (SIMD)
A single instruction is simultaneously applied to multiple different data streams. Instructions can be executed sequentially, such as by pipelining, or in parallel by multiple functional units. Flynn's 1972 paper subdivided SIMD down into three further categories: [2]
- Array processor known today as SIMT – These receive the one (same) instruction but each parallel processing unit (PU) has its own separate and distinct memory and register file. The memory connected to each PU is not shared between other PUs. Early SIMT processors had Scalar PUs (1 bit in SOLOMON, 64 bit in ILLIAC IV) but modern SIMT processors - GPUs - invariably have SWAR ALUs.
- Pipelined processor – These receive the one (same) instruction but then read data from a central resource, each processes fragments of that data (typically termed "elements"), then writes back the results to the same central resource. In Figure 5 of Flynn's 1972 paper that resource is main memory: for modern CPUs that resource is now more typically the register file.
- Associative processor – These receive the one (same) instruction but in addition a register value from the Control Unit is also broadcast to each PU. In each PU an independent decision is made, based on data local to the unit, comparing against the broadcast value, as to whether to perform the broadcast instruction, or whether to skip it.
Array processor

The modern term for an array processor is "single instruction, multiple threads" (SIMT). This is a distinct classification in Flynn's 1972 taxonomy, as a subcategory of SIMD. It is identifiable by the parallel subelements having their own independent register file and memory (cache and data memory). Flynn's original papers cite two historic examples of SIMT processors: SOLOMON and ILLIAC IV.
Each Processing Element also has an independent active/inactive bit that enables/disables the PE:
for each (PE j) // synchronously-concurrent arrayif (active-maskbit j) then broadcast_instruction_to(PE j)
Nvidia commonly uses the term in its marketing materials and technical documents, where it argues for the novelty of its architecture. [6] SOLOMON predates Nvidia by more than 60 years.
Pipelined processor

Flynn's 1972 paper calls Pipelined processors a form of "time-multiplexed" Array processing, where elements are read sequentially from memory, processed in (pipelined) stages, and written out, again sequentially to memory, from the last stage. From this description (page 954) it is likely that Flynn was referring to vector chaining, and to memory-to-memory Vector processors such as the TI ASC designed manufactured and sold between 1966 and 1973, [7] and the CDC STAR-100 which had just been announced at the time of writing of Flynn's paper.
At the time that Flynn wrote his 1972 paper many systems were using main memory as the resource from which pipelines were reading and writing. When the resource that all "pipelines" read and write from is the scalar register file rather than main memory, modern variants of SIMD result. Examples include Altivec, NEON, and AVX.
An alternative name for this type of register-based SIMD is "packed SIMD" [8] and another is SIMD within a register (SWAR).
Associative processor

The modern term for associative processor is analogous to cells of content-addressable memory each having their own processor. Such processors are very rare.
broadcast_value=control_unit.register(n)broadcast_instruction=control_unit.array_instructionforeach(PEj)// of associative arraypossible_match=PE[j].match_registerifbroadcast_value==possible_matchPE[j].execute(broadcast_instruction)The Aspex Microelectronics Associative String Processor (ASP) [9] categorised itself in its marketing material as "massive wide SIMD" but had bit-level ALUs and bit-level predication (Flynn's taxonomy: array processing), and each of the 4096 processors had their own registers and memory including Content-Addressable Memory (Flynn's taxonomy: associative processing). The Linedancer, released in 2010, contained 4096 2-bit predicated SIMD ALUs, each with its own CAM, and was capable of 800 billion instructions per second. [10] Aspex's ASP associative array SIMT processor predates NVIDIA by 20 years. [11] [12] There is some difficulty in classifying this processor according to Flynn's Taxonomy as it had both Associative Processing capability and Array processing, both under explicit programmer control.
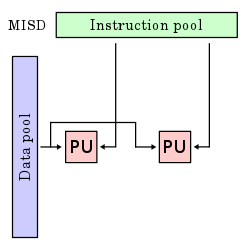
Multiple instruction streams, single data stream (MISD)
Multiple instructions operate on one data stream. This is an uncommon architecture which is generally used for fault tolerance. Heterogeneous systems operate on the same data stream and must agree on the result. Examples include the Space Shuttle flight control computer. [13]
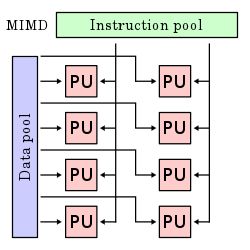
Multiple instruction streams, multiple data streams (MIMD)
Multiple autonomous processors simultaneously execute different instructions on different data. MIMD architectures include multi-core superscalar processors, and distributed systems, using either one shared memory space or a distributed memory space.