In computer science, a strict Fibonacci heap is a priority queuedata structure with low worst case time bounds. It matches the amortized time bounds of the Fibonacci heap in the worst case. To achieve these time bounds, strict Fibonacci heaps maintain several invariants by performing restoring transformations after every operation. These transformations can be done in constant time by using auxiliary data structures to track invariant violations, and the pigeonhole principle guarantees that these can be fixed. Strict Fibonacci heaps were invented in 2012 by Gerth S. Brodal, George Lagogiannis, and Robert E. Tarjan, with an update in 2025.[1]
Along with Brodal queues, strict Fibonacci heaps belong to a class of asymptotically optimal data structures for priority queues.[2] All operations on strict Fibonacci heaps run in worst case constant time except delete-min, which is necessarily logarithmic. This is optimal, because any priority queue can be used to sort a list of elements by performing insertions and delete-min operations.[3] However, strict Fibonacci heaps are simpler than Brodal queues, which make use of dynamic arrays and redundant counters,[4] whereas the strict Fibonacci heap is pointer based only.
Structure
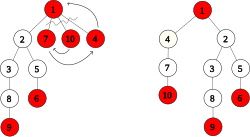
A strict Fibonacci heap with no loss. Nodes 5 and 2 are active roots. Their active subtrees are binomial trees.
A strict Fibonacci heap is a single tree satisfying the minimum-heap property. That is, the key of a node is always smaller than or equal to its children. As a direct consequence, the node with the minimum key always lies at the root.
Like ordinary Fibonacci heaps,[5] strict Fibonacci heaps possess substructures similar to binomial heaps. To identify these structures, we label every node with one of two types. We thus introduce the following definitions and rules:
All nodes are either active (colored white) or passive (colored red).
An active root is an active node with a passive parent.
A passive linkable node is a passive node where all its descendants are passive (a passive node with no children is considered to be linkable).
The rank of an active node is the number of active children it has.
The loss of an active node is the number of active children it has lost.
For any node, the active children lie to the left of the passive children.
An active root always has zero loss.
The root is passive.
The passive linkable children of the root lie to the right of the passive non-linkable children.
Invariants
Invariant 1: Structure
The th rightmost active child of an active node satisfies .
Thus, the loss of an active node can be viewed as a generalisation of Fibonacci heap 'marks'. For example, a subtree consisting of only active nodes with loss zero is a binomial tree.
In addition, several invariants which impose logarithmic bounds on three main quantities: the number of active roots, the total loss, and the degrees of nodes. This is in contrast to the ordinary Fibonacci heap, which is more flexible and allows structural violations to grow on the order of to be cleaned up later, as it is a lazy data structure.
To assist in keeping the degrees of nodes logarithmic, every non-root node also participates in a queue . In the following section, and for rest of this article, we define the real number , where is the number of nodes in the heap, and denotes the binary logarithm.
Invariant 2: Active roots
The total number of active roots is at most .
Invariant 3: Total loss
The total loss in the heap is at most .
Invariant 4: Root degree
The degree of the root is at most .
Invariant 5: Non-root degrees
For an active node with zero loss, the degree is at most , where is its position in (with 1 as the first element). For all other non-root nodes, the degree is at most .
Corollary 1: Maximum degree
The degree of any non-root node is at most .
Proof:
This follows immediately from invariant 5. Letting , we have
Lemma 1: Maximum rank
If invariant 1 holds, the maximum rank or any active node is at most , where is the total loss.[6]
Proof:
We proceed by contradiction. Let be an active node with maximal rank in a heap with nodes and total loss , and assume that , where is the smallest integer such that . Our goal is to show that the subtree rooted at contains nodes, which is a contradiction because there are only nodes in the heap.
Discard all subtrees rooted at passive nodes from , leaving it with only active nodes. Cut off all the grandchildren of whose subtrees contain any node of positive loss, and increase the loss of the children of accordingly, once for each grandchild lost. The quantity is unchanged for the remaining nodes, preserving invariant 1. Furthermore, the total loss is still at most .
The children of now consists of loss-free subtrees and leaf nodes with positive loss. Currently, satisfies for the th rightmost child of . We make this an exact equality by first reducing the loss of each , and pruning any grandchildren if necessary. Afterwards, exactly. All other descendants of are also converted into binomial subtrees by pruning children as necessary.
We now attempt to reconstruct a minimal version of by starting with a binomial tree of degree , containing active nodes. We wish to increase the loss to , but keep the rank of as and the number of nodes as low as possible. For a binomial tree of degree , there is one child of each degree from to . Hence, there are grandchildren of order . If we cut all the grandchildren whose degree , then we have cut grandchildren, which is sufficient to bring the loss up to . All grandchildren with degree survive. Let be the child of with degree and loss 0. By assumption, , and is a complete binomial tree, so it has at least nodes. Since this would mean has at least nodes, we have reached a contradiction, and therefore . Noting that , we obtain .
Corollary 2: Maximum rank
If invariants 1 and 3 both hold, then the maximum rank is .
Proof:
From invariant 3, we have . By substituting this into lemma 1, we calculate as follows:
Transformations
The following transformations restore the above invariants after a priority queue operation has been performed. There are three main quantities we wish to minimize: the number of active roots, the total loss in the heap, and the degree of the root. All transformations can be performed in time, which is possible by maintaining auxiliary data structures to track candidate nodes (described in the section on implementation).[6]
Active root reduction
Let and be active roots with equal rank , and assume . Link as the leftmost child of and increase the rank of by 1. If the rightmost child of is passive, link to the root.
As a result, is no longer an active root, so the number of active roots decreases by 1. However, the degree of the root node may increase by 1,
Since becomes the th rightmost child of , and has rank , invariant 1 is preserved.
Lemma 2: Availability of active root reduction
If invariant 2 is violated, but invariants 1 and 3 hold, then active root reduction is possible.
Proof:
Because invariant 2 is broken, there are more than active roots present. From corollary 2, the maximum rank of a node is . By the pigeonhole principle, there exists a pair of active roots with the same rank.
Loss reduction
One node loss reduction
Let be an active non-root with loss at least 2. Link to the root, thus turning it into an active root, and resetting its loss to 0. Let the original parent of be . must be active, since otherwise would have previously been an active root, and thus could not have had positive loss. The rank of is decreased by 1. If is not an active root, increase its loss by 1.
Overall, the total loss decreases by 1 or 2. As a side effect, the root degree and number of active roots increase by 1, making it less preferable to two node loss reduction, but still a necessary operation.
Two node loss reduction
Let and be active nodes with equal rank and loss equal to 1, and let be the parent of . Without loss of generality, assume that . Detach from , and link to . Increase the rank of by 1 and reset the loss of and from 1 to 0.
must be active, since had positive loss and could not have been an active root. Hence, the rank of is decreased by 1. If is not an active root, increase its loss by 1.
Overall, the total loss decreases by either 1 or 2, with no side effects.
Lemma 3: Availability of loss reduction
If invariant 3 is violated by 1, but invariant 2 holds, then loss reduction is possible.
Proof: We apply the pigeonhole principle again. If invariant 3 is violated by 1, the total loss is . Lemma 1 can be reformulated to also work with . Thus, corollary 2 holds. Since the maximum rank is , either there either exists a pair of active nodes with equal rank and loss 1, or an active node with . Both cases present an opportunity for loss reduction.
Root degree reduction
Root degree reduction
Let , , and be the three rightmost passive linkable children of the root. Detach them all from the root and sort them such that . Change and to be active. Link to , link to , and link as the leftmost child of the root. As a result, becomes an active root with rank 1 and loss 0. The rank and loss of is set to 0.
The net change of this transformation is that the degree of the root node decreases by 2. As a side effect, the number of active roots increases by 1.
Lemma 4: Availability of root degree reduction
If invariant 4 is violated, but invariant 2 holds, then root degree reduction is possible.
Proof:
If invariant 4 is broken, then the degree of the root is at least . The children of the root fall into three categories: active roots, passive non-linkable nodes, and passive linkable nodes. Each passive non-linkable node subsumes an active root, since its subtree contains at least one active node. Because the number of active roots is at most , the rightmost three children of the root must therefore be passive linkable.
Summary
The following table summarises the effect of each transformation on the three important quantities. Individually, each transformation may violate invariants, but we are only interested in certain combinations of transformations which do not increase any of these quantities.
Effect of transformations
Active roots
Total loss
Root degree
Active root reduction
Root degree reduction
One node loss reduction
Two node loss reduction
When deciding which transformations to perform, we consider only the worst case effect of these operations, for simplicity. The two types of loss reduction are also considered to be the same operation. As such, we define 'performing a loss reduction' to mean attempting each type of loss reduction in turn.
Worst case effect of transformations
Active roots
Total loss
Root degree
Active root reduction
Root degree reduction
Loss reduction
Implementation
Linking nodes
To ensure active nodes lie to the left of passive nodes, and preserve invariant 1, the linking operation should place active nodes on the left, and passive nodes on the right. It is necessary for active and passive nodes to coexist in the same list, because the merge operation changes all nodes in the smaller heap to be passive. If they existed in two separate lists, the lists would have to be concatenated, which cannot be done in constant time for all nodes.
For the root, we also pose the requirement that passive linkable children lie to the right of the passive non-linkable children. Since we wish to be able link nodes to the root in constant time, a pointer to the first passive linkable child of the root must be maintained.
Finding candidate nodes
The invariant restoring transformations rely on being able to find candidate nodes in time. This means that we must keep track of active roots with the same rank, nodes with loss 1 of the same rank, and nodes with loss at least 2.
The original paper by Brodal et al. described a fix-list and a rank-list as a way of tracking candidate nodes.[6]
Fix-list
Rank-list and fix-list
The fix-list is divided into four parts:
Active roots ready for active root reduction – active roots with a partner of the same rank. Nodes with the same rank are kept adjacent.
Active roots not yet ready for active reduction – the only active roots for that rank.
Active nodes with loss 1 that are not yet ready for loss reduction – the only active nodes with loss 1 for that rank.
Active nodes that are ready for loss reduction – This includes active nodes with loss 1 that have a partner of the same rank, and active nodes with loss at least 2, which do not need partners to be reduced. Nodes with the same rank are kept adjacent.
To check if active root reduction is possible, we simply check if part 1 is non-empty. If it is non-empty, the first two nodes can be popped off and transformed. Similarly, to check if loss reduction is possible, we check the end of part 4. If it contains a node with loss at least 2, one node loss reduction is performed. Otherwise, if the last two nodes both have loss 1, and are of the same rank, two node loss reduction is performed.
Rank-list
The rank-list is a doubly linked list containing information about each rank, to allow nodes of the same rank to be partnered together in the fix-list.
For each node representing rank in the rank-list, we maintain:
A pointer to the first active root in the fix-list with rank . If such a node does not exist, this is NULL.
A pointer to the first active node in the fix-list with rank and loss 1. If such a node does not exist, this is NULL.
A pointer to the node representing rank and , to facilitate the incrementation and decrementation of ranks.
The fix-list and rank-list require extensive bookkeeping, which must be done whenever a new active node arises, or when the rank or loss of a node is changed.
Shared flag
Using a shared flag to change make all nodes passive in time
The merge operation changes all of the active nodes of the smaller heap into passive nodes. This can be done in time by introducing a level of indirection.[6] Instead of a boolean flag, each active node has a pointer towards an active flag object containing a boolean value. For passive nodes, it does not matter which active flag object they point to, as long as the flag object is set to passive, because it is not required to change many passive nodes into active nodes simultaneously.
Relinking pointers between nodes and boxed keys
Storing keys
The decrease-key operation requires a reference to the node we wish to decrease the key of. However, the decrease-key operation itself sometimes swaps the key of a node and the key root.
Assume that the insert operation returns some opaque reference that we can call decrease-key on, as part of the public API. If these references are internal heap nodes, then by swapping keys we have mutated these references, causing other references to become undefined. To ensure a key is always stays with the same reference, it is necessary to 'box' the key. Each heap node now contains a pointer to a box containing a key, and the box also has a pointer to the heap node. When inserting an item, we create a box to store the key in, link the heap node to the box both ways, and return the box object.[6] To swap the keys between two nodes, we re-link the pointers between the boxes and nodes instead.
Operations
Merge
Let and be strict Fibonacci heaps. If either is empty, return the other. Otherwise, let and be their corresponding sizes. Without loss of generality, assume that . Since the sizes of the fix-list and rank-list of each heap are logarithmic with respect to the heap size, it is not possible to merge these auxiliary structures in constant time. Instead, we throw away the structure of the smaller heap by discarding its fix-list and rank-list, and converting all of its nodes into passive nodes.[6] This can be done in constant time, using a shared flag, as shown above. Link and , letting the root with the smaller key become the parent of the other. Let and be the queues of and respectively. The queue of resulting heap is set to, where is the root with the larger key.
The only possible structural violation is the root degree. This is solved by performing 1 active root reduction, and 1 root degree reduction, if each transformation is possible.
Active roots
Total loss
Root degree
State after merge
Active root reduction
Root degree reduction
Total
Proof of correctness
Invariants 1, 2, and 3 hold automatically, since the structure of the heap is discarded. As calculated above, any violations of invariant 4 are solved by the root degree reduction transformation.
To verify invariant 5, we consider the final positions of nodes in . Each node has its degree bounded by or .
For the smaller heap the positions in are unchanged. However, all nodes in are now passive, which means that their constraint may change from the case to the case. But noting that , the resulting size is at least double . This results in an increase of at least 1 on each constraint, which eliminates the previous concern.
The root with the larger key between and becomes a non-root, and is placed between and at position . By invariant 4, its degree was bounded by either or , depending on which heap it came from. It is easy to see that this is less than in any case.
For the larger heap, the positions increase by . But since the resulting size is , the value actually increases, weakening the constraint.
Insert
Insertion can be considered a special case of the merge operation. To insert a single key, create a new heap containing a single passive node and an empty queue, and merge it with the main heap.
Find-min
Due to the minimum-heap property, the node with the minimum key is always at the root, if it exists.
Delete-min
Delete-min operation
If the root is the only node in the heap, we are done by simply removing it. Otherwise, search the children of the root to find the node with minimum key, and set the new root to . If is active, make it passive, causing all active children of to implicitly become active roots. Link the children of the old root to . Since is now the root, move all of its passive linkable children to the right, and remove from .
The degree of the root approximately doubles, because we have linked all the children of the old root to . We perform the following restorative transformations:
Repeat twice: rotate by moving the head of to the back, and link the two rightmost passive children of to the root.
If a loss reduction is possible, perform it.
Perform active root reductions and root degree reductions until neither is possible.
To see how step 3 is bounded, consider the state after step 3:
Active roots
Total loss
Root degree
State after delete-min
Queue rotation
Loss reduction
Total
Observe that, 3 active root reductions and 2 root reductions decreases the root degree and active roots by 1:
Active roots
Total loss
Root degree
Active root reduction
Root degree reduction
Total
Since , step 3 never executes more than times.
Proof of correctness
Invariant 1 holds trivially, since no active roots are created.
The size of the heap decreases by one, causing decreases by at most one. Thus, invariant 3 is violated by at most 1. By lemma 3, loss reduction is possible, which has been done by step 2.
Invariants 1 and 3 now hold. If invariants 2 and 4 were still violated after step 3, it would be possible to apply active root reduction and root degree reduction, by lemmas 2 and 4. However, active root reduction and root degree reduction have already been exhaustively applied. Therefore, invariants 2 and 4 also hold.
To show that invariant 5 is satisfied, we first note that the heap size has decreased by 1. Because the first 2 nodes in are popped in step 1, the positions of the other elements in decrease by 2. Therefore, the degree constraints and remain constant for these nodes. The two nodes which were popped previously had positions 1 and 2 in , and now have positions and respectively. The effect is that their degree constraints have strengthened by 2, however, we cut off two passive children for each of these nodes, which is sufficient to satisfy the constraint again.
Decrease-key
Decrease-key operation
Let be the node whose key has been decreased. If is the root, we are done. Otherwise, detach the subtree rooted at , and link it to the root. If the key of is smaller than the key of the root, swap their keys.
Up to three structural violations may have occurred. Unless was already a child of the root, the degree of the root increases by 1. When was detached from its original parent , we have the following cases:
If is passive, then there are no extra violations.
If was previously an active root with passive, then moving from being a child of to a child of the root does not create any additional active roots, nor does it increase the loss of any node.
If both and are active, then the loss of increases by 1, and an extra active root is created (by linking to the root).
In the worst case, all three quantities (root degree, total loss, active roots) increase by 1.
After performing 1 loss reduction, the worst case result is still that the root degree and number of active roots have both increased by 2. To fix these violations, we use the fact that 3 active root reductions and 2 root reductions decrease both of these quantities by 1. Hence, applying these transformations 6 and 4 times respectively is sufficient to eliminate all violations.
Active roots
Total loss
Root degree
State after decrease-key
Loss reduction
Active root reduction
Root degree reduction
Total
Proof of correctness
The nodes which were previously the left siblings of move to fill the gap left by , decreasing their index. Since their constraint has weakened, invariant 1 is unaffected. Invariant 5 trivially holds as is unchanged.
Lemmas 2, 3 and 4 guarantee the availability of active root reduction, loss reduction, and root degree reduction. Therefore, invariants 2, 3 and 4 hold.
Performance
Although theoretically optimal, strict Fibonacci heaps are not useful in practical applications. They are extremely complicated to implement, requiring management of more than 10 pointers per node.[6][7] While most operations run in time, the constant factors may be very high, making them up to 20 times slower than their more common counterparts such as binary heaps or pairing heaps.[8] Despite being relatively simpler, experiments show that in practice the strict Fibonacci heap performs slower than the Brodal queue.[9]
Summary of running times
Here are time complexities[10] of various heap data structures. The abbreviation am. indicates that the given complexity is amortized, otherwise it is a worst-case complexity. For the meaning of "O(f)" and "Θ(f)" see Big O notation. Names of operations assume a min-heap.
↑ make-heap is the operation of building a heap from a sequence of n unsorted elements. It can be done in Θ(n) time whenever meld runs in O(logn) time (where both complexities can be amortized).[11][12] Another algorithm achieves Θ(n) for binary heaps.[13]
1 2 3 For persistent heaps (not supporting decrease-key), a generic transformation reduces the cost of meld to that of insert, while the new cost of delete-min is the sum of the old costs of delete-min and meld.[16] Here, it makes meld run in Θ(1) time (amortized, if the cost of insert is) while delete-min still runs in O(logn). Applied to skew binomial heaps, it yields Brodal-Okasaki queues, persistent heaps with optimal worst-case complexities.[15]
1 2 Brodal queues and strict Fibonacci heaps achieve optimal worst-case complexities for heaps. They were first described as imperative data structures. The Brodal-Okasaki queue is a persistent data structure achieving the same optimum, except that decrease-key is not supported.
↑ Brodal, Gerth Stølting (1996-01-28). "Worst-case efficient priority queues". Proceedings of the Seventh Annual ACM-SIAM Symposium on Discrete Algorithms. SODA '96. USA: Society for Industrial and Applied Mathematics: 52–58. ISBN978-0-89871-366-4.
↑ Mrena, Michal; Sedlacek, Peter; Kvassay, Miroslav (June 2019). "Practical Applicability of Advanced Implementations of Priority Queues in Finding Shortest Paths". 2019 International Conference on Information and Digital Technologies (IDT). Zilina, Slovakia: IEEE. pp.335–344. doi:10.1109/DT.2019.8813457. ISBN9781728114019. S2CID201812705.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.