
In the theory of dynamical systems, the exponential map can be used as the evolution function of the discrete nonlinear dynamical system. [1]
In the theory of dynamical systems, the exponential map can be used as the evolution function of the discrete nonlinear dynamical system. [1]
The family of exponential functions is called the exponential family.
There are many forms of these maps, [2] many of which are equivalent under a coordinate transformation. For example two of the most common ones are:
The second one can be mapped to the first using the fact that , so is the same under the transformation . The only difference is that, due to multi-valued properties of exponentiation, there may be a few select cases that can only be found in one version. Similar arguments can be made for many other formulas.
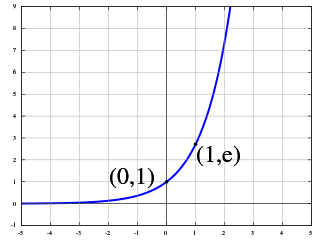
The exponential function is a mathematical function denoted by or . Unless otherwise specified, the term generally refers to the positive-valued function of a real variable, although it can be extended to the complex numbers or generalized to other mathematical objects like matrices or Lie algebras. The exponential function originated from the operation of taking powers of a number, but various modern definitions allow it to be rigorously extended to all real arguments , including irrational numbers. Its ubiquitous occurrence in pure and applied mathematics led mathematician Walter Rudin to consider the exponential function to be "the most important function in mathematics".

In physics, the Lorentz transformations are a six-parameter family of linear transformations from a coordinate frame in spacetime to another frame that moves at a constant velocity relative to the former. The respective inverse transformation is then parameterized by the negative of this velocity. The transformations are named after the Dutch physicist Hendrik Lorentz.

In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

In mathematics, the Lyapunov exponent or Lyapunov characteristic exponent of a dynamical system is a quantity that characterizes the rate of separation of infinitesimally close trajectories. Quantitatively, two trajectories in phase space with initial separation vector diverge at a rate given by
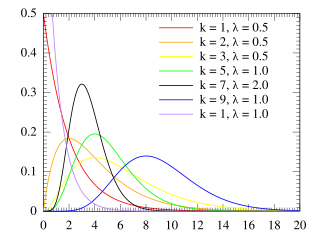
The Erlang distribution is a two-parameter family of continuous probability distributions with support . The two parameters are:

In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.

A quantity is subject to exponential decay if it decreases at a rate proportional to its current value. Symbolically, this process can be expressed by the following differential equation, where N is the quantity and λ (lambda) is a positive rate called the exponential decay constant, disintegration constant, rate constant, or transformation constant:
In physics, mathematics and statistics, scale invariance is a feature of objects or laws that do not change if scales of length, energy, or other variables, are multiplied by a common factor, and thus represent a universality.

In probability theory and statistics, the Laplace distribution is a continuous probability distribution named after Pierre-Simon Laplace. It is also sometimes called the double exponential distribution, because it can be thought of as two exponential distributions spliced together along the abscissa, although the term is also sometimes used to refer to the Gumbel distribution. The difference between two independent identically distributed exponential random variables is governed by a Laplace distribution, as is a Brownian motion evaluated at an exponentially distributed random time. Increments of Laplace motion or a variance gamma process evaluated over the time scale also have a Laplace distribution.
Variational Bayesian methods are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They are typically used in complex statistical models consisting of observed variables as well as unknown parameters and latent variables, with various sorts of relationships among the three types of random variables, as might be described by a graphical model. As typical in Bayesian inference, the parameters and latent variables are grouped together as "unobserved variables". Variational Bayesian methods are primarily used for two purposes:
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.
In mathematics, a logarithm of a matrix is another matrix such that the matrix exponential of the latter matrix equals the original matrix. It is thus a generalization of the scalar logarithm and in some sense an inverse function of the matrix exponential. Not all matrices have a logarithm and those matrices that do have a logarithm may have more than one logarithm. The study of logarithms of matrices leads to Lie theory since when a matrix has a logarithm then it is in an element of a Lie group and the logarithm is the corresponding element of the vector space of the Lie algebra.
In the mathematical discipline of matrix theory, a Jordan matrix, named after Camille Jordan, is a block diagonal matrix over a ring R, where each block along the diagonal, called a Jordan block, has the following form:

Rapidity is a measure for relativistic velocity. For one-dimensional motion, rapidities are additive. However, velocities must be combined by Einstein's velocity-addition formula. For low speeds, rapidity and velocity are almost exactly proportional but, for higher velocities, rapidity takes a larger value, with the rapidity of light being infinite.
In statistics, a power transform is a family of functions applied to create a monotonic transformation of data using power functions. It is a data transformation technique used to stabilize variance, make the data more normal distribution-like, improve the validity of measures of association, and for other data stabilization procedures.
A complex quadratic polynomial is a quadratic polynomial whose coefficients and variable are complex numbers.
In probability and statistics, the Tweedie distributions are a family of probability distributions which include the purely continuous normal, gamma and inverse Gaussian distributions, the purely discrete scaled Poisson distribution, and the class of compound Poisson–gamma distributions which have positive mass at zero, but are otherwise continuous. Tweedie distributions are a special case of exponential dispersion models and are often used as distributions for generalized linear models.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate and independently of the time since the last event. It can also be used for the number of events in other types of intervals than time, and in dimension greater than 1.
In mathematics, and particularly complex dynamics, the escaping set of an entire function ƒ consists of all points that tend to infinity under the repeated application of ƒ. That is, a complex number belongs to the escaping set if and only if the sequence defined by converges to infinity as gets large. The escaping set of is denoted by .

The q-exponential distribution is a probability distribution arising from the maximization of the Tsallis entropy under appropriate constraints, including constraining the domain to be positive. It is one example of a Tsallis distribution. The q-exponential is a generalization of the exponential distribution in the same way that Tsallis entropy is a generalization of standard Boltzmann–Gibbs entropy or Shannon entropy. The exponential distribution is recovered as
| | This fractal–related article is a stub. You can help Wikipedia by expanding it. |






