Collation is the assembly of written information into a standard order. Many systems of collation are based on numerical order or alphabetical order, or extensions and combinations thereof. Collation is a fundamental element of most office filing systems, library catalogs, and reference books.

The Latin alphabet, also known as the Roman alphabet, is the collection of letters originally used by the ancient Romans to write the Latin language. Largely unaltered with the exception of a couple splits, additions, and extensions, it forms the Latin script that is used to write most languages of modern Europe, Africa, America and Oceania. Its basic modern repertoire is standardised as the ISO basic Latin alphabet.

Mojibake is the garbled or gibberish text that is the result of text being decoded using an unintended character encoding. The result is a systematic replacement of symbols with completely unrelated ones, often from a different writing system.
In computing, a locale is a set of parameters that defines the user's language, region and any special variant preferences that the user wants to see in their user interface. Usually a locale identifier consists of at least a language code and a country/region code. Locale is an important aspect of i18n.

Letter case is the distinction between the letters that are in larger uppercase or capitals and smaller lowercase in the written representation of certain languages. The writing systems that distinguish between the upper- and lowercase have two parallel sets of letters: each in the majuscule set has a counterpart in the minuscule set. Some counterpart letters have the same shape, and differ only in size, but for others the shapes are different. The two case variants are alternative representations of the same letter: they have the same name and pronunciation and are typically treated identically when sorting in alphabetical order.
The romanization of Ukrainian, or Latinization of Ukrainian, is the representation of the Ukrainian language in Latin letters. Ukrainian is natively written in its own Ukrainian alphabet, which is based on the Cyrillic script. Romanization may be employed to represent Ukrainian text or pronunciation for non-Ukrainian readers, on computer systems that cannot reproduce Cyrillic characters, or for typists who are not familiar with the Ukrainian keyboard layout. Methods of romanization include transliteration and transcription.
The Common Locale Data Repository (CLDR) is a project of the Unicode Consortium to provide locale data in XML format for use in computer applications. CLDR contains locale-specific information that an operating system will typically provide to applications. CLDR is written in the Locale Data Markup Language (LDML).

The Latin script, also known as the Roman script, is a writing system based on the letters of the classical Latin alphabet, derived from a form of the Greek alphabet which was in use in the ancient Greek city of Cumae in Magna Graecia. The Greek alphabet was altered by the Etruscans, and subsequently their alphabet was altered by the Ancient Romans. Several Latin-script alphabets exist, which differ in graphemes, collation and phonetic values from the classical Latin alphabet.

The Latin script is the most widely used alphabetic writing system in the world. It is the standard script of the English language and is often referred to simply as "the alphabet" in English. It is a true alphabet which originated in the 7th century BC in Italy and has changed continually over the last 2,500 years. It has roots in the Semitic alphabet and its offshoot alphabets, the Phoenician, Greek, and Etruscan. The phonetic values of some letters changed, some letters were lost and gained, and several writing styles ("hands") developed. Two such styles, the minuscule and majuscule hands, were combined into one script with alternate forms for the lower and upper case letters. Modern uppercase letters differ only slightly from their classical counterparts, and there are few regional variants.
The Klingon scripts are fictional alphabetic scripts used in the Star Trek movies and television shows to write the Klingon language.

Romanization or Latinization of Persian is the representation of the Persian language with the Latin script. Several different romanization schemes exist, each with its own set of rules driven by its own set of ideological goals.
The ISO basic Latin alphabet is an international standard for a Latin-script alphabet that consists of two sets of 26 letters, codified in various national and international standards and used widely in international communication. They are the same letters that comprise the current English alphabet. Since medieval times, they are also the same letters of the modern Latin alphabet. The order is also important for sorting words into alphabetical order.
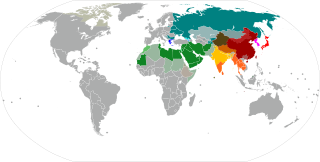
A writing system comprises a particular set of symbols, called a script, as well as the rules by which the script represents a particular language. Writing systems can generally be classified according to how symbols function according to these rules, with the most common types being alphabets, syllabaries, and logographies. Alphabets use symbols called letters that correspond to spoken phonemes. Abjads generally only have letters for consonants, while pure alphabets have letters for both consonants and vowels. Abugidas use characters that correspond to consonant–vowel pairs. Syllabaries use symbols called syllabograms to represent syllables or moras. Logographies use characters that represent semantic units, such as words or morphemes.
The goal of braille uniformity is to unify the braille alphabets of the world as much as possible, so that literacy in one braille alphabet readily transfers to another. Unification was first achieved by a convention of the International Congress on Work for the Blind in 1878, where it was decided to replace the mutually incompatible national conventions of the time with the French values of the basic Latin alphabet, both for languages that use Latin-based alphabets and, through their Latin equivalents, for languages that use other scripts. However, the unification did not address letters beyond these 26, leaving French and German Braille partially incompatible and as braille spread to new languages with new needs, national conventions again became disparate. A second round of unification was undertaken under the auspices of UNESCO in 1951, setting the foundation for international braille usage today.