Bile (from Latin bilis), also known as gall, is a yellow-green fluid produced by the liver of most vertebrates that aids the digestion of lipids in the small intestine. In humans, bile is primarily composed of water, is produced continuously by the liver, and is stored and concentrated in the gallbladder. After a human eats, this stored bile is discharged into the first section of the small intestine, known as the duodenum through the ampulla of vater in the duodenal wall .[1][2]
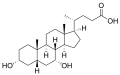
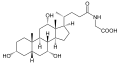
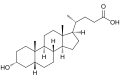
In the human liver, bile is composed of 97–98% water, 0.7% bile salts, 0.2% bilirubin, 0.51% fats (cholesterol, fatty acids, and lecithin), and 200 meq/L inorganic salts.[3][4] The two main pigments of bile are bilirubin, which is orange-yellow, and its oxidised form biliverdin, which is green.[5] About 400 to 800 milliliters (14 to 27 U.S. fluid ounces) of bile is produced per day in adult human beings.[6]
Function
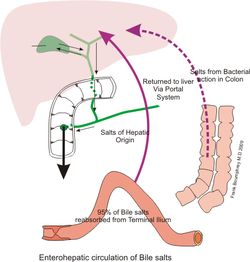
Action of bile salts in digestionRecycling of the bile
Bile or gall acts to some extent as a surfactant, helping to emulsify the lipids in food. Bile salt anions are hydrophilic on one side and hydrophobic on the other side; consequently, they tend to aggregate around droplets of lipids (triglycerides and phospholipids) to form micelles, with the hydrophobic sides towards the fat and hydrophilic sides facing outwards.[7] The hydrophilic sides are negatively charged, and this charge prevents fat droplets coated with bile from re-aggregating into larger fat particles. Ordinarily, the micelles in the duodenum have a diameter around 1–50μm in humans.[8]
The dispersion of food fat into micelles provides a greatly increased surface area for the action of the enzyme pancreatic lipase, which digests the triglycerides, and is able to reach the fatty core through gaps between the bile salts.[9] A triglyceride is broken down into two fatty acids and a monoglyceride, which are absorbed by the villi on the intestine walls. After being transferred across the intestinal membrane, the fatty acids reform into triglycerides (re-esterified), before being absorbed into the lymphatic system through lacteals. Without bile salts, most of the lipids in food would be excreted in feces, undigested.[10]
Since bile increases the absorption of fats, it is an important part of the absorption of the fat-soluble substances,[11] such as the vitaminsA, D, E, and K.[12]
Besides its digestive function, bile serves also as the route of excretion for bilirubin, a byproduct of red blood cells recycled by the liver. Bilirubin derives from hemoglobin by glucuronidation.
Bile tends to be alkaline on average. The pH of common duct bile (7.50 to 8.05) is higher than that of the corresponding gallbladder bile (6.80 to 7.65). Bile in the gallbladder becomes more acidic the longer a person goes without eating, though resting slows this fall in pH.[13] As an alkali, it also has the function of neutralizing excess stomach acid before it enters the duodenum, the first section of the small intestine. Bile salts also act as bactericides, destroying many of the microbes that may be present in the food.[14]
Clinical significance
In the absence of bile, fats become indigestible and are instead excreted in feces, a condition called steatorrhea. Feces lack their characteristic brown color and instead are white or gray, and greasy.[15] Steatorrhea can lead to deficiencies in essential fatty acids and fat-soluble vitamins.[16] In addition, past the small intestine (which is normally responsible for absorbing fat from food) the gastrointestinal tract and gut flora are not adapted to processing fats, leading to problems in the large intestine.[17]
The cholesterol contained in bile will occasionally accrete into lumps in the gallbladder, forming gallstones. Cholesterol gallstones are generally treated through surgical removal of the gallbladder. However, they can sometimes be dissolved by increasing the concentration of certain naturally occurring bile acids, such as chenodeoxycholic acid and ursodeoxycholic acid.[18][19]
On an empty stomach – after repeated vomiting, for example – a person's vomit may be green or dark yellow, and very bitter. The bitter and greenish component may be bile or normal digestive juices originating in the stomach.[20] Bile may be forced into the stomach secondary due to a weakened valve (pylorus), the presence of certain drugs including alcohol, or powerful muscular contractions and duodenal spasms. This is known as biliary reflux.[21]
Obstruction
Biliary obstruction refers to a condition when bile ducts which deliver bile from the gallbladder or liver to the duodenum become obstructed. The blockage of bile might cause a buildup of bilirubin in the bloodstream which can result in jaundice. There are several potential causes for biliary obstruction including gallstones, cancer,[22] trauma, choledochal cysts, or other benign causes of bile duct narrowing.[23] The most common cause of bile duct obstruction is when gallstone(s) are dislodged from the gallbladder into the cystic duct or common bile duct resulting in a blockage. A blockage of the gallbladder or cystic duct may cause cholecystitis. If the blockage is beyond the confluence of the pancreatic duct, this may cause gallstone pancreatitis. In some instances of biliary obstruction, the bile may become infected by bacteria resulting in ascending cholangitis.
Society and culture
A sample of bile for medical testing.
In medical theories prevalent in the West from classical antiquity to the Middle Ages, the body's health depended on the equilibrium of four "humors", or vital fluids, two of which related to bile: blood, phlegm, "yellow bile" (choler), and "black bile". These "humors" are believed to have their roots in the appearance of a blood sedimentation test made in open air, which exhibits a dark clot at the bottom ("black bile"), a layer of unclotted erythrocytes ("blood"), a layer of white blood cells ("phlegm") and a layer of clear yellow serum ("yellow bile").[24]
Excesses of black bile and yellow bile were thought to produce depression and aggression, respectively, and the Greek names for them gave rise to the English words cholera (from Greek χολή kholē, "bile") and melancholia. In the former of those senses, the same theories explain the derivation of the English word bilious from bile, the meaning of gall in English as "exasperation" or "impudence", and the Latin word cholera, derived from the Greek kholé, which was passed along into some Romance languages as words connoting anger, such as colère (French) and cólera (Spanish).[25]
Soap
Soap can be mixed with bile from mammals, such as ox gall. This mixture, called bile soap[26] or gall soap, can be applied to textiles a few hours before washing as a traditional and effective method for removing various kinds of tough stains.[27]
Food
Pinapaitan is a dish in Philippine cuisine that uses bile as flavoring.[28] Other areas where bile is commonly used as a cooking ingredient include Laos and northern parts of Thailand.
During the Boshin War, Satsuma soldiers of the early Imperial Japanese Army reportedly ate human livers boiled in bile.[29] The practice of eating a slain enemy's liver, known as hiemontori (冷え物取り), was a tradition of the Satsuma people.
Bears
In regions of China where bile products are a popular ingredient in traditional medicine, the use of bears in bile-farming has been widespread. This practice has been condemned by activists, and some pharmaceutical companies have developed synthetic (non-ursine) alternatives.[30]
↑Shanbhogue, Alampady Krishna Prasad; Tirumani, Sree Harsha; Prasad, Srinivasa R.; Fasih, Najla; McInnes, Matthew (2011-08-01). "Benign Biliary Strictures: A Current Comprehensive Clinical and Imaging Review". American Journal of Roentgenology. 197 (2): W295–W306. doi:10.2214/AJR.10.6002. ISSN0361-803X. PMID21785056.
↑Johansson, Ingvar; Lynøe, Niels (2008). Medicine & Philosophy: A Twenty-First Century Introduction. Walter de Gruyter. p.27. ISBN9783110321364. Retrieved 2015-04-23. If blood is poured into a glass jar, a process of coagulation and sedimentation starts. It ends with four clearly distinct layers: a red region, a yellowish one, a black one, and a white one (Figure 4, left) ... The lowest part of the same column consists of sediment that is too dense to permit light to pass through. Therefore, this part of the column looks black and might be referred to as the 'black bile'. On the top of the column there is a white layer, which we today classify as fibrin; it might correspond to Galen's 'phlegm'. The remaining part is a rather clear but somewhat yellowish fluid that surrounds the coagulated column in the middle. It might be called 'yellow bile', but today we recognize it as blood serum.
Krejčí, Z; Hanuš L.; Podstatová H.; Reifová E (1983). "A contribution to the problems of the pathogenesis and microbial etiology of cholelithiasis". Acta Universitatis Palackianae Olomucensis Facultatis Medicae. 104: 279–286. PMID6222611.
Maton, Anthea; Jean Hopkins; Charles William McLaughlin; Susan Johnson; Maryanna Quon Warner; David LaHart; Jill D. Wright (1993). Human Biology and Health. Englewood Cliffs, New Jersey: Prentice Hall. ISBN0-13-981176-1.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.