Sensitivity analysis is the study of how the uncertainty in the output of a mathematical model or system (numerical or otherwise) can be divided and allocated to different sources of uncertainty in its inputs.[1][2] This involves estimating sensitivity indices that quantify the influence of an input or group of inputs on the output. A related practice is uncertainty analysis, which has a greater focus on uncertainty quantification and propagation of uncertainty; ideally, uncertainty and sensitivity analysis should be run in tandem.
A mathematical model (for example in biology, climate change, economics, renewable energy, agronomy...) can be highly complex, and as a result, its relationships between inputs and outputs may be faultily understood. In such cases, the model can be viewed as a black box, i.e. the output is an "opaque" function of its inputs. Quite often, some or all of the model inputs are subject to sources of uncertainty, including errors of measurement, errors in input data, parameter estimation and approximation procedure, absence of information and poor or partial understanding of the driving forces and mechanisms, choice of underlying hypothesis of model, and so on. This uncertainty limits our confidence in the reliability of the model's response or output. Further, models may have to cope with the natural intrinsic variability of the system (aleatory), such as the occurrence of stochastic events.[3]
In models involving many input variables, sensitivity analysis is an essential ingredient of model building and quality assurance and can be useful to determine the impact of a uncertain variable for a range of purposes,[4] including:
Testing the robustness of the results of a model or system in the presence of uncertainty.
Increased understanding of the relationships between input and output variables in a system or model.
Uncertainty reduction, through the identification of model input that cause significant uncertainty in the output and should therefore be the focus of attention in order to increase robustness.
Searching for errors in the model (by encountering unexpected relationships between inputs and outputs).
Model simplification – fixing model input that has no effect on the output, or identifying and removing redundant parts of the model structure.
Enhancing communication from modelers to decision makers (e.g. by making recommendations more credible, understandable, compelling or persuasive).
Finding regions in the space of input factors for which the model output is either maximum or minimum or meets some optimum criterion (see optimization and Monte Carlo filtering).
For calibration of models with large number of parameters, by focusing on the sensitive parameters.[5]
To identify important connections between observations, model inputs, and predictions or forecasts, leading to the development of better models.[6][7]
Mathematical formulation and vocabulary
Figure 1. Schematic representation of uncertainty analysis and sensitivity analysis. In mathematical modeling, uncertainty arises from a variety of sources - errors in input data, parameter estimation and approximation procedure, underlying hypothesis, choice of model, alternative model structures and so on. They propagate through the model and have an impact on the output. The uncertainty on the output is described via uncertainty analysis (represented pdf on the output) and their relative importance is quantified via sensitivity analysis (represented by pie charts showing the proportion that each source of uncertainty contributes to the total uncertainty of the output).
The object of study for sensitivity analysis is a function , (called "mathematical model" or "programming code"), viewed as a black box, with the -dimensional input vector and the output, presented as following:
The variability in input parameters have an impact on the output . While uncertainty analysis aims to describe the distribution of the output (providing its statistics, moments, pdf, cdf,...), sensitivity analysis aims to measure and quantify the impact of each input or a group of inputs on the variability of the output (by calculating the corresponding sensitivity indices). Figure 1 provides a schematic representation of this statement.
Challenges, settings and related issues
Taking into account uncertainty arising from different sources, whether in the context of uncertainty analysis or sensitivity analysis (for calculating sensitivity indices), requires multiple samples of the uncertain parameters and, consequently, running the model (evaluating the -function) multiple times. Depending on the complexity of the model there are many challenges that may be encountered during model evaluation. Therefore, the choice of method of sensitivity analysis is typically dictated by a number of problem constraints, settings or challenges. Some of the most common are:
Computational expense: Sensitivity analysis is almost always performed by running the model a (possibly large) number of times, i.e. a sampling-based approach.[8] This can be a significant problem when:
Time-consuming models are very often encountered when complex models are involved. A single run of the model takes a significant amount of time (minutes, hours or longer). The use of statistical model (meta-model, data-driven model) including HDMR to approximate the -function is one way of reducing the computation costs.
The model has a large number of uncertain inputs. Sensitivity analysis is essentially the exploration of the multidimensional input space, which grows exponentially in size with the number of inputs. Therefore, screening methods can be useful for dimension reduction. Another way to tackle the curse of dimensionality is to use sampling based on low discrepancy sequences.[9]
Correlated inputs: Most common sensitivity analysis methods assume independence between model inputs, but sometimes inputs can be strongly correlated. Correlations between inputs must then be taken into account in the analysis.[10]
Nonlinearity: Some sensitivity analysis approaches, such as those based on linear regression, can inaccurately measure sensitivity when the model response is nonlinear with respect to its inputs. In such cases, variance-based measures are more appropriate.
Multiple or functional outputs: Generally introduced for single-output codes, sensitivity analysis extends to cases where the output is a vector or function.[11] When outputs are correlated, it does not preclude the possibility of performing different sensitivity analyses for each output of interest. However, for models in which the outputs are correlated, the sensitivity measures can be hard to interpret.
Stochastic code: A code is said to be stochastic when, for several evaluations of the code with the same inputs, different outputs are obtained (as opposed to a deterministic code when, for several evaluations of the code with the same inputs, the same output is always obtained). In this case, it is necessary to separate the variability of the output due to the variability of the inputs from that due to stochasticity.[12]
Data-driven approach: Sometimes it is not possible to evaluate the code at all desired points, either because the code is confidential or because the experiment is not reproducible. The code output is only available for a given set of points, and it can be difficult to perform a sensitivity analysis on a limited set of data. We then build a statistical model (meta-model, data-driven model) from the available data (that we use for training) to approximate the code (the -function).[13]
To address the various constraints and challenges, a number of methods for sensitivity analysis have been proposed in the literature, which we will examine in the next section.
Sensitivity analysis methods
There are a large number of approaches to performing a sensitivity analysis, many of which have been developed to address one or more of the constraints discussed above. They are also distinguished by the type of sensitivity measure, be it based on (for example) variance decompositions, partial derivatives or elementary effects. In general, however, most procedures adhere to the following outline:
Quantify the uncertainty in each input (e.g. ranges, probability distributions). Note that this can be difficult and many methods exist to elicit uncertainty distributions from subjective data.[14]
Identify the model output to be analysed (the target of interest should ideally have a direct relation to the problem tackled by the model).
Run the model a number of times using some design of experiments,[15] dictated by the method of choice and the input uncertainty.
Using the resulting model outputs, calculate the sensitivity measures of interest.
In some cases this procedure will be repeated, for example in high-dimensional problems where the user has to screen out unimportant variables before performing a full sensitivity analysis.
The various types of "core methods" (discussed below) are distinguished by the various sensitivity measures which are calculated. These categories can somehow overlap. Alternative ways of obtaining these measures, under the constraints of the problem, can be given. In addition, an engineering view of the methods that takes into account the four important sensitivity analysis parameters has also been proposed.[16]
Visual analysis
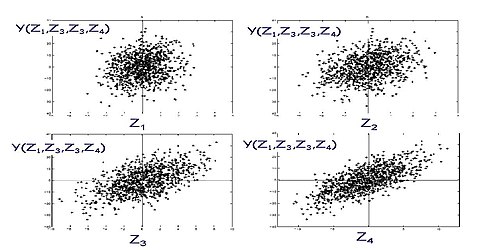
Figure 2. Sampling-based sensitivity analysis by scatterplots. Y (vertical axis) is a function of four factors. The points in the four scatterplots are always the same though sorted differently, i.e. by Z1, Z2, Z3, Z4 in turn. Note that the abscissa is different for each plot: (−5,+5) for Z1, (−8,+8) for Z2, (−10,+10) for Z3 and Z4. Z4 is most important in influencing Y as it imparts more 'shape' on Y.
The first intuitive approach (especially useful in less complex cases) is to analyze the relationship between each input and the output using scatter plots, and observe the behavior of these pairs. The diagrams give an initial idea of the correlation and which input has an impact on the output. Figure 2 shows an example where two inputs, and are highly correlated with the output.
One of the simplest and most common approaches is that of changing one-factor-at-a-time (OAT), to see what effect this produces on the output.[17][18][19] OAT customarily involves
moving one input variable, keeping others at their baseline (nominal) values, then,
returning the variable to its nominal value, then repeating for each of the other inputs in the same way.
Sensitivity may then be measured by monitoring changes in the output, e.g. by partial derivatives or linear regression. This appears a logical approach as any change observed in the output will unambiguously be due to the single variable changed. Furthermore, by changing one variable at a time, one can keep all other variables fixed to their central or baseline values. This increases the comparability of the results (all 'effects' are computed with reference to the same central point in space) and minimizes the chances of computer program crashes, more likely when several input factors are changed simultaneously. OAT is frequently preferred by modelers because of practical reasons. In case of model failure under OAT analysis the modeler immediately knows which is the input factor responsible for the failure.
Despite its simplicity however, this approach does not fully explore the input space, since it does not take into account the simultaneous variation of input variables. This means that the OAT approach cannot detect the presence of interactions between input variables and is unsuitable for nonlinear models.[20]
The proportion of input space which remains unexplored with an OAT approach grows superexponentially with the number of inputs. For example, a 3-variable parameter space which is explored one-at-a-time is equivalent to taking points along the x, y, and z axes of a cube centered at the origin. The convex hull bounding all these points is an octahedron which has a volume only 1/6th of the total parameter space. More generally, the convex hull of the axes of a hyperrectangle forms a hyperoctahedron which has a volume fraction of . With 5 inputs, the explored space already drops to less than 1% of the total parameter space. And even this is an overestimate, since the off-axis volume is not actually being sampled at all. Compare this to random sampling of the space, where the convex hull approaches the entire volume as more points are added.[21] While the sparsity of OAT is theoretically not a concern for linear models, true linearity is rare in nature.
Named after the statistician Max D. Morris, this method is suitable for screening systems with many parameters. This is also known as method of elementary effects because it combines repeated steps along the various parametric axes.[22]
Derivative-based local methods
Local derivative-based methods involve taking the partial derivative of the output with respect to an input factor :
where the subscript x0 indicates that the derivative is taken at some fixed point in the space of the input (hence the 'local' in the name of the class). Adjoint modelling[23][24] and Automated Differentiation[25] are methods which allow to compute all partial derivatives at a cost at most 4-6 times of that for evaluating the original function. Similar to OAT, local methods do not attempt to fully explore the input space, since they examine small perturbations, typically one variable at a time. It is possible to select similar samples from derivative-based sensitivity through Neural Networks and perform uncertainty quantification.
One advantage of the local methods is that it is possible to make a matrix to represent all the sensitivities in a system, thus providing an overview that cannot be achieved with global methods if there is a large number of input and output variables.[26]
Regression analysis
Regression analysis, in the context of sensitivity analysis, involves fitting a linear regression to the model response and using standardized regression coefficients as direct measures of sensitivity. The regression is required to be linear with respect to the data (i.e. a hyperplane, hence with no quadratic terms, etc., as regressors) because otherwise it is difficult to interpret the standardised coefficients. This method is therefore most suitable when the model response is in fact linear; linearity can be confirmed, for instance, if the coefficient of determination is large. The advantages of regression analysis are that it is simple and has a low computational cost.
Variance-based methods[27] are a class of probabilistic approaches which quantify the input and output uncertainties as random variables, represented via their probability distributions, and decompose the output variance into parts attributable to input variables and combinations of variables. The sensitivity of the output to an input variable is therefore measured by the amount of variance in the output caused by that input.
This amount is quantified and calculated using Sobol indices: they represent the proportion of variance explained by an input or group of inputs. This expression essentially measures the contribution of alone to the uncertainty (variance) in (averaged over variations in other variables), and is known as the first-order sensitivity index or main effect index or main Sobol index or Sobol main index.
For an input , Sobol index is defined as following:
where and denote the variance and expected value operators respectively.
Importantly, first-order sensitivity index of does not measure the uncertainty caused by interactions has with other variables. A further measure, known as the total effect index, gives the total variance in caused by and its interactions with any of the other input variables. The total effect index is given as following: where denotes the set of all input variables except .
Variance-based methods allow full exploration of the input space, accounting for interactions, and nonlinear responses. For these reasons they are widely used when it is feasible to calculate them. Typically this calculation involves the use of Monte Carlo methods, but since this can involve many thousands of model runs, other methods (such as metamodels) can be used to reduce computational expense when necessary.
Moment-independent methods
Moment-independent methods extend variance-based techniques by considering the probability density or cumulative distribution function of the model output . Thus, they do not refer to any particular moment of , whence the name.
The moment-independent sensitivity measures of , here denoted by , can be defined through an equation similar to variance-based indices replacing the conditional expectation with a distance, as , where is a statistical distance [metric or divergence] between probability measures, and are the marginal and conditional probability measures of .[28]
If is a distance, the moment-independent global sensitivity measure satisfies zero-independence. This is a relevant statistical property also known as Renyi's postulate D.[29]
The class of moment-independent sensitivity measures includes indicators such as the -importance measure,[30] the new correlation coefficient of Chatterjee,[31] the Wasserstein correlation of Wiesel [32] and the kernel-based sensitivity measures of Barr and Rabitz.[33]
Another measure for global sensitivity analysis, in the category of moment-independent approaches, is the PAWN index.[34]It relies on Cumulative Distribution Functions (CDFs) to characterize the maximum distance between the unconditional output distribution and conditional output distribution (obtained by varying all input parameters and by setting the -th input, consequentially). The difference between the unconditional and conditional output distribution is usually calculated using the Kolmogorov–Smirnov test (KS). The PAWN index for a given input parameter is then obtained by calculating the summary statistics over all KS values.[citation needed]
Variogram analysis of response surfaces (VARS)
One of the major shortcomings of the previous sensitivity analysis methods is that none of them considers the spatially ordered structure of the response surface/output of the model in the parameter space. By utilizing the concepts of directional variograms and covariograms, variogram analysis of response surfaces (VARS) addresses this weakness through recognizing a spatially continuous correlation structure to the values of , and hence also to the values of .[35][36]
Basically, the higher the variability the more heterogeneous is the response surface along a particular direction/parameter, at a specific perturbation scale. Accordingly, in the VARS framework, the values of directional variograms for a given perturbation scale can be considered as a comprehensive illustration of sensitivity information, through linking variogram analysis to both direction and perturbation scale concepts. As a result, the VARS framework accounts for the fact that sensitivity is a scale-dependent concept, and thus overcomes the scale issue of traditional sensitivity analysis methods.[37] More importantly, VARS is able to provide relatively stable and statistically robust estimates of parameter sensitivity with much lower computational cost than other strategies (about two orders of magnitude more efficient).[38] Noteworthy, it has been shown that there is a theoretical link between the VARS framework and the variance-based and derivative-based approaches.
The Fourier amplitude sensitivity test (FAST) uses the Fourier series to represent a multivariate function (the model) in the frequency domain, using a single frequency variable. Therefore, the integrals required to calculate sensitivity indices become univariate, resulting in computational savings.
Shapley effects
Shapley effects rely on Shapley values and represent the average marginal contribution of a given factors across all possible combinations of factors. These value are related to Sobol’s indices as their value falls between the first order Sobol’ effect and the total order effect.[39]
Chaos polynomials
The principle is to project the function of interest onto a basis of orthogonal polynomials. The Sobol indices are then expressed analytically in terms of the coefficients of this decomposition.[40]
Complementary research approaches for time-consuming simulations
A number of methods have been developed to overcome some of the constraints discussed above, which would otherwise make the estimation of sensitivity measures infeasible (most often due to computational expense). Generally, these methods focus on efficiently (by creating a metamodel of the costly function to be evaluated and/or by “ wisely ” sampling the factor space) calculating variance-based measures of sensitivity.
Metamodels
Metamodels (also known as emulators, surrogate models or response surfaces) are data-modeling/machine learning approaches that involve building a relatively simple mathematical function, known as an metamodels, that approximates the input/output behavior of the model itself.[41] In other words, it is the concept of "modeling a model" (hence the name "metamodel"). The idea is that, although computer models may be a very complex series of equations that can take a long time to solve, they can always be regarded as a function of their inputs . By running the model at a number of points in the input space, it may be possible to fit a much simpler metamodels , such that to within an acceptable margin of error.[42] Then, sensitivity measures can be calculated from the metamodel (either with Monte Carlo or analytically), which will have a negligible additional computational cost. Importantly, the number of model runs required to fit the metamodel can be orders of magnitude less than the number of runs required to directly estimate the sensitivity measures from the model.[43]
Clearly, the crux of an metamodel approach is to find an (metamodel) that is a sufficiently close approximation to the model . This requires the following steps,
Sampling (running) the model at a number of points in its input space. This requires a sample design.
Selecting a type of emulator (mathematical function) to use.
"Training" the metamodel using the sample data from the model – this generally involves adjusting the metamodel parameters until the metamodel mimics the true model as well as possible.
Sampling the model can often be done with low-discrepancy sequences, such as the Sobol sequence – due to mathematician Ilya M. Sobol or Latin hypercube sampling, although random designs can also be used, at the loss of some efficiency. The selection of the metamodel type and the training are intrinsically linked since the training method will be dependent on the class of metamodel. Some types of metamodels that have been used successfully for sensitivity analysis include:
Discrete Bayesian networks,[48] in conjunction with canonical models such as noisy models. Noisy models exploit information on the conditional independence between variables to significantly reduce dimensionality.
The use of an emulator introduces a machine learning problem, which can be difficult if the response of the model is highly nonlinear. In all cases, it is useful to check the accuracy of the emulator, for example using cross-validation.
High-dimensional model representations (HDMR)
A high-dimensional model representation (HDMR)[49][50] (the term is due to H. Rabitz[51]) is essentially an emulator approach, which involves decomposing the function output into a linear combination of input terms and interactions of increasing dimensionality. The HDMR approach exploits the fact that the model can usually be well-approximated by neglecting higher-order interactions (second or third-order and above). The terms in the truncated series can then each be approximated by e.g. polynomials or splines (REFS) and the response expressed as the sum of the main effects and interactions up to the truncation order. From this perspective, HDMRs can be seen as emulators which neglect high-order interactions; the advantage is that they are able to emulate models with higher dimensionality than full-order emulators.
Monte Carlo filtering
Sensitivity analysis via Monte Carlo filtering[52] is also a sampling-based approach, whose objective is to identify regions in the space of the input factors corresponding to particular values (e.g., high or low) of the output.
Related concepts
Sensitivity analysis is closely related with uncertainty analysis; while the latter studies the overall uncertainty in the conclusions of the study, sensitivity analysis tries to identify what source of uncertainty weighs more on the study's conclusions.
The problem setting in sensitivity analysis also has strong similarities with the field of design of experiments.[53] In a design of experiments, one studies the effect of some process or intervention (the 'treatment') on some objects (the 'experimental units'). In sensitivity analysis one looks at the effect of varying the inputs of a mathematical model on the output of the model itself. In both disciplines one strives to obtain information from the system with a minimum of physical or numerical experiments.
It may happen that a sensitivity analysis of a model-based study is meant to underpin an inference, and to certify its robustness, in a context where the inference feeds into a policy or decision-making process. In these cases the framing of the analysis itself, its institutional context, and the motivations of its author may become a matter of great importance, and a pure sensitivity analysis – with its emphasis on parametric uncertainty – may be seen as insufficient. The emphasis on the framing may derive inter-alia from the relevance of the policy study to different constituencies that are characterized by different norms and values, and hence by a different story about 'what the problem is' and foremost about 'who is telling the story'. Most often the framing includes more or less implicit assumptions, which could be political (e.g. which group needs to be protected) all the way to technical (e.g. which variable can be treated as a constant).
In order to take these concerns into due consideration the instruments of SA have been extended to provide an assessment of the entire knowledge and model generating process. This approach has been called 'sensitivity auditing'. It takes inspiration from NUSAP,[54] a method used to qualify the worth of quantitative information with the generation of `Pedigrees' of numbers. Sensitivity auditing has been especially designed for an adversarial context, where not only the nature of the evidence, but also the degree of certainty and uncertainty associated to the evidence, will be the subject of partisan interests.[55] Sensitivity auditing is recommended in the European Commission guidelines for impact assessment,[56] as well as in the report Science Advice for Policy by European Academies.[57]
Pitfalls and difficulties
Some common difficulties in sensitivity analysis include:
Assumptions vs. inferences: In uncertainty and sensitivity analysis there is a crucial trade off between how scrupulous an analyst is in exploring the input assumptions and how wide the resulting inference may be. The point is well illustrated by the econometrician Edward E. Leamer:[58][59]
" I have proposed a form of organized sensitivity analysis that I call 'global sensitivity analysis' in which a neighborhood of alternative assumptions is selected and the corresponding interval of inferences is identified. Conclusions are judged to be sturdy only if the neighborhood of assumptions is wide enough to be credible and the corresponding interval of inferences is narrow enough to be useful."
Note Leamer's emphasis is on the need for 'credibility' in the selection of assumptions. The easiest way to invalidate a model is to demonstrate that it is fragile with respect to the uncertainty in the assumptions or to show that its assumptions have not been taken 'wide enough'. The same concept is expressed by Jerome R. Ravetz, for whom bad modeling is when uncertainties in inputs must be suppressed lest outputs become indeterminate.[60]
Not enough information to build probability distributions for the inputs: Probability distributions can be constructed from expert elicitation, although even then it may be hard to build distributions with great confidence. The subjectivity of the probability distributions or ranges will strongly affect the sensitivity analysis.
Unclear purpose of the analysis: Different statistical tests and measures are applied to the problem and different factors rankings are obtained. The test should instead be tailored to the purpose of the analysis, e.g. one uses Monte Carlo filtering if one is interested in which factors are most responsible for generating high/low values of the output.
Too many model outputs are considered: This may be acceptable for the quality assurance of sub-models but should be avoided when presenting the results of the overall analysis.
Piecewise sensitivity: This is when one performs sensitivity analysis on one sub-model at a time. This approach is non conservative as it might overlook interactions among factors in different sub-models (Type II error).
↑ Saltelli, A.; Tarantola, S.; Campolongo, F.; Ratto, M. (2004). Sensitivity analysis in practice: a guide to assessing scientific models. Vol.1. doi:10.1002/0470870958. ISBN978-0-470-87093-8.
↑ Der Kiureghian, A.; Ditlevsen, O. (2009). "Aleatory or epistemic? Does it matter?". Structural Safety. 31 (2): 105–112. doi:10.1016/j.strusafe.2008.06.020.
↑ Hill, M.; Tiedeman, C. (2007). Effective Groundwater Model Calibration, with Analysis of Data, Sensitivities, Predictions, and Uncertainty. John Wiley & Sons.
↑ Sobol', I (1990). "Sensitivity estimates for nonlinear mathematical models". Matematicheskoe Modelirovanie (in Russian). 2: 112–118.; translated in English in Sobol', I (1993). "Sensitivity analysis for non-linear mathematical models". Mathematical Modeling & Computational Experiment. 1: 407–414.
↑ Borgonovo E, Tarantola S, Plischke E, Morris MD (2014). "Transformations and invariance in the sensitivity analysis of computer experiments". Journal of the Royal Statistical Society. Series B (Statistical Methodology). 76 (5): 925–947. doi:10.1111/rssb.12052. ISSN1369-7412.
↑ Rényi, A (1 September 1959). "On measures of dependence". Acta Mathematica Academiae Scientiarum Hungaricae. 10 (3): 441–451. doi:10.1007/BF02024507. ISSN1588-2632.
↑ Barr J, Rabitz H (31 March 2022). "A Generalized Kernel Method for Global Sensitivity Analysis". SIAM/ASA Journal on Uncertainty Quantification. 10 (1). Society for Industrial and Applied Mathematics: 27–54. doi:10.1137/20M1354829.
↑ Haghnegahdar, Amin; Razavi, Saman (September 2017). "Insights into sensitivity analysis of Earth and environmental systems models: On the impact of parameter perturbation scale". Environmental Modelling & Software. 95: 115–131. Bibcode:2017EnvMS..95..115H. doi:10.1016/j.envsoft.2017.03.031.
↑ Owen AB (1 January 2014). "Sobol' Indices and Shapley Value". SIAM/ASA Journal on Uncertainty Quantification. 2 (1). Society for Industrial and Applied Mathematics: 245–251. doi:10.1137/130936233.
↑ Sudret, B. (2008). "Global sensitivity analysis using polynomial chaos expansions". Reliability Engineering & System Safety. 93 (7): 964–979. doi:10.1016/j.ress.2007.04.002.
↑ Ratto, M.; Pagano, A. (2010). "Using recursive algorithms for the efficient identification of smoothing spline ANOVA models". AStA Advances in Statistical Analysis. 94 (4): 367–388. doi:10.1007/s10182-010-0148-8. S2CID7678955.
↑ Cardenas, IC (2019). "On the use of Bayesian networks as a meta-modeling approach to analyse uncertainties in slope stability analysis". Georisk: Assessment and Management of Risk for Engineered Systems and Geohazards. 13 (1): 53–65. Bibcode:2019GAMRE..13...53C. doi:10.1080/17499518.2018.1498524. S2CID216590427.
↑ Li, G.; Hu, J.; Wang, S.-W.; Georgopoulos, P.; Schoendorf, J.; Rabitz, H. (2006). "Random Sampling-High Dimensional Model Representation (RS-HDMR) and orthogonality of its different order component functions". Journal of Physical Chemistry A. 110 (7): 2474–2485. Bibcode:2006JPCA..110.2474L. doi:10.1021/jp054148m. PMID16480307.
↑ Lo Piano, S; Robinson, M (2019). "Nutrition and public health economic evaluations under the lenses of post normal science". Futures. 112 102436. doi:10.1016/j.futures.2019.06.008. S2CID198636712.
Borgonovo, E. (2017). Sensitivity Analysis: An Introduction for the Management Scientist. International Series in Management Science and Operations Research, Springer New York.
Pilkey, O. H. and L. Pilkey-Jarvis (2007), Useless Arithmetic. Why Environmental Scientists Can't Predict the Future. New York: Columbia University Press.
Santner, T. J.; Williams, B. J.; Notz, W.I. (2003) Design and Analysis of Computer Experiments; Springer-Verlag.
Haug, Edward J.; Choi, Kyung K.; Komkov, Vadim (1986) Design sensitivity analysis of structural systems. Mathematics in Science and Engineering, 177. Academic Press, Inc., Orlando, FL.
Hall, C. A. S. and Day, J. W. (1977). Ecosystem Modeling in Theory and Practice: An Introduction with Case Histories. John Wiley & Sons, New York, NY. ISBN978-0-471-34165-9
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.