
The Cyrillic script, Slavonic script or simply Slavic script is a writing system used for various languages across Eurasia. It is the designated national script in various Slavic, Turkic, Mongolic, Uralic, Caucasian and Iranic-speaking countries in Southeastern Europe, Eastern Europe, the Caucasus, Central Asia, North Asia, and East Asia, and used by many other minority languages.
Transliteration is a type of conversion of a text from one script to another that involves swapping letters in predictable ways, such as Greek ⟨α⟩ → ⟨a⟩, Cyrillic ⟨д⟩ → ⟨d⟩, Greek ⟨χ⟩ → the digraph ⟨ch⟩, Armenian ⟨ն⟩ → ⟨n⟩ or Latin ⟨æ⟩ → ⟨ae⟩.

In linguistics, romanization or romanisation is the conversion of text from a different writing system to the Roman (Latin) script, or a system for doing so. Methods of romanization include transliteration, for representing written text, and transcription, for representing the spoken word, and combinations of both. Transcription methods can be subdivided into phonemic transcription, which records the phonemes or units of semantic meaning in speech, and more strict phonetic transcription, which records speech sounds with precision.

Mojibake is the garbled or gibberish text that is the result of text being decoded using an unintended character encoding. The result is a systematic replacement of symbols with completely unrelated ones, often from a different writing system.

The romanization of the Russian language, aside from its primary use for including Russian names and words in text written in a Latin alphabet, is also essential for computer users to input Russian text who either do not have a keyboard or word processor set up for inputting Cyrillic, or else are not capable of typing rapidly using a native Russian keyboard layout (JCUKEN). In the latter case, they would type using a system of transliteration fitted for their keyboard layout, such as for English QWERTY keyboards, and then use an automated tool to convert the text into Cyrillic.
The romanization of Ukrainian, or Latinization of Ukrainian, is the representation of the Ukrainian language in Latin letters. Ukrainian is natively written in its own Ukrainian alphabet, which is based on the Cyrillic script. Romanization may be employed to represent Ukrainian text or pronunciation for non-Ukrainian readers, on computer systems that cannot reproduce Cyrillic characters, or for typists who are not familiar with the Ukrainian keyboard layout. Methods of romanization include transliteration and transcription.

The Ukrainian alphabet is the set of letters used to write Ukrainian, which is the official language of Ukraine. It is one of several national variations of the Cyrillic script. It comes from the Cyrillic script, which was devised in the 9th century for the first Slavic literary language, called Old Slavonic. In the 10th century, it became used in Kievan Rus' to write Old East Slavic, from which the Belarusian, Russian, Rusyn, and Ukrainian alphabets later evolved. The modern Ukrainian alphabet has 33 letters in total: 21 consonants, 1 semivowel, 10 vowels and 1 palatalization sign. Sometimes the apostrophe (') is also included, which has a phonetic meaning and is a mandatory sign in writing, but is not considered as a letter and is not included in the alphabet.

Faux Cyrillic, pseudo-Cyrillic, pseudo-Russian or faux Russian typography is the use of Cyrillic letters in Latin text, usually to evoke the Soviet Union or Russia, though it may be used in other contexts as well. It is a common Western trope used in book covers, film titles, comic book lettering, artwork for computer games, or product packaging which are set in or wish to evoke Eastern Europe, the Soviet Union, or Russia. A typeface designed to emulate Cyrillic is classed as a mimicry typeface.

Romanization of Bulgarian is the practice of transliteration of text in Bulgarian from its conventional Cyrillic orthography into the Latin alphabet. Romanization can be used for various purposes, such as rendering of proper names and place names in foreign-language contexts, or for informal writing of Bulgarian in environments where Cyrillic is not easily available. Official use of romanization by Bulgarian authorities is found, for instance, in identity documents and in road signage. Several different standards of transliteration exist, one of which was chosen and made mandatory for common use by the Bulgarian authorities in a law of 2009.
The Arabic chat alphabet, Arabizi, Arabeezi, Arabish or Franco-Arabic refer to the romanized alphabets for informal Arabic dialects in which Arabic script is transcribed or encoded into a combination of Latin script and Arabic numerals. These informal chat alphabets were originally used primarily by youth in the Arab world in very informal settings—especially for communicating over the Internet or for sending messages via cellular phones—though use is not necessarily restricted by age anymore and these chat alphabets have been used in other media such as advertising.

Three alphabets are used to write Kazakh: the Cyrillic, Latin and Arabic scripts. The Cyrillic script is used in Kazakhstan and Mongolia. An October 2017 Presidential Decree in Kazakhstan ordered that the transition from Cyrillic to a Latin script be completed by 2031. The Arabic script is used in Saudi Arabia, Iran, Afghanistan, and parts of China.
Scientific transliteration, variously called academic, linguistic, international, or scholarly transliteration, is an international system for transliteration of text from the Cyrillic script to the Latin script (romanization). This system is most often seen in linguistics publications on Slavic languages.
YUSCII is an informal name for several JUS standards for 7-bit character encoding. These include:

The Tajik language has been written in three alphabets over the course of its history: an adaptation of the Perso-Arabic script, an adaptation of the Latin script and an adaptation of the Cyrillic script. Any script used specifically for Tajik may be referred to as the Tajik alphabet, which is written as алифбои тоҷикӣ in Cyrillic characters, الفبای تاجیکی with Perso-Arabic script and alifboji toçikī in Latin script.
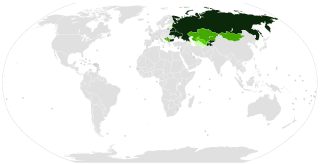
Numerous Cyrillic alphabets are based on the Cyrillic script. The early Cyrillic alphabet was developed in the 9th century AD and replaced the earlier Glagolitic script developed by the Bulgarian theologians Cyril and Methodius. It is the basis of alphabets used in various languages, past and present, Slavic origin, and non-Slavic languages influenced by Russian. As of 2011, around 252 million people in Eurasia use it as the official alphabet for their national languages. About half of them are in Russia. Cyrillic is one of the most-used writing systems in the world. The creator is Saint Clement of Ohrid from the Preslav literary school in the First Bulgarian Empire.

The romanization or Latinization of Serbian is the representation of the Serbian language using Latin letters. Serbian is written in two alphabets, Serbian Cyrillic, a variation of the Cyrillic alphabet, and Gaj's Latin, or latinica, a variation of the Latin alphabet. The Serbian language is an example of digraphia.
In mobile telephony GSM 03.38 or 3GPP 23.038 is a character encoding used in GSM networks for SMS, CB and USSD. The 3GPP TS 23.038 standard defines GSM 7-bit default alphabet which is mandatory for GSM handsets and network elements, but the character set is suitable only for English and a number of Western-European languages. Languages such as Chinese, Korean or Japanese must be transferred using the 16-bit UCS-2 character encoding. A limited number of languages, like Portuguese, Spanish, Turkish and a number of languages used in India written with a Brahmic scripts may use 7-bit encoding with national language shift table defined in 3GPP 23.038. For binary messages, 8-bit encoding is used.
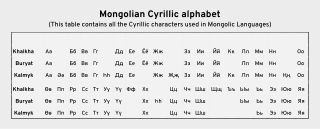
The Mongolian Cyrillic alphabet is the writing system used for the standard dialect of the Mongolian language in the modern state of Mongolia. It has a largely phonemic orthography, meaning that there is a fair degree of consistency in the representation of individual sounds. Cyrillic has not been adopted as the writing system in the Inner Mongolia region of China, which continues to use the traditional Mongolian script.
Data Coding Scheme is a one-octet field in Short Messages (SM) and Cell Broadcast Messages (CB) which carries a basic information how the recipient handset should process the received message. The information includes:
The Komi language, a Uralic language spoken in the north-eastern part of European Russia, has been written in several different alphabets. Currently, Komi writing uses letters from the Cyrillic script. There have been five distinct stages in the history of Komi writing: