Related Research Articles

The Cyrillic script, Slavonic script or simply Slavic script is a writing system used for various languages across Eurasia. It is the designated national script in various Slavic, Turkic, Mongolic, Uralic, Caucasian and Iranic-speaking countries in Southeastern Europe, Eastern Europe, the Caucasus, Central Asia, North Asia, and East Asia, and used by many other minority languages.

Mojibake is the garbled or gibberish text that is the result of text being decoded using an unintended character encoding. The result is a systematic replacement of symbols with completely unrelated ones, often from a different writing system.
ISO/IEC 646 is a set of ISO/IEC standards, described as Information technology — ISO 7-bit coded character set for information interchange and developed in cooperation with ASCII at least since 1964. Since its first edition in 1967 it has specified a 7-bit character code from which several national standards are derived.
ISO/IEC 8859-5:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 5: Latin/Cyrillic alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1988. It is informally referred to as Latin/Cyrillic.
GB/T 2312-1980 is a key official character set of the People's Republic of China, used for Simplified Chinese characters. GB2312 is the registered internet name for EUC-CN, which is its usual encoded form. GB refers to the Guobiao standards (国家标准), whereas the T suffix denotes a non-mandatory standard.
KOI8-R is an 8-bit character encoding, derived from the KOI-8 encoding by the programmer Andrei Chernov in 1993 and designed to cover Russian, which uses a Cyrillic alphabet. KOI8-R was based on Russian Morse code, which was created from a phonetic version of Latin Morse code. As a result, Russian Cyrillic letters are in pseudo-Roman order rather than the normal Cyrillic alphabetical order. Although this may seem unnatural, if the 8th bit is stripped, the text is partially readable in ASCII and may convert to syntactically correct KOI-7. For example, "Код Обмена Информацией" in KOI8-R becomes kOD oBMENA iNFORMACIEJ.
KOI8-U is an 8-bit character encoding, designed to cover Ukrainian, which uses a Cyrillic alphabet. It is based on KOI8-R, which covers Russian and Bulgarian, but replaces eight box drawing characters with four Ukrainian letters Ґ, Є, І, and Ї in both upper case and lower case.
KOI (КОИ) is a family of several code pages for the Cyrillic script. The name stands for Kod obmena informatsiey which means "Code for Information Interchange".
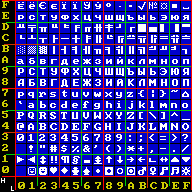
Code page 866 is a code page used under DOS and OS/2 in Russia to write Cyrillic script. It is based on the "alternative code page" developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR. The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 and maintains alphabetic order of Cyrillic letters. Initially this encoding was only available in the Russian version of MS-DOS 4.01 (1990), but with MS-DOS 6.22 it became available in any language version.
KOI-7 (КОИ-7) is a 7-bit character encoding, designed to cover Russian, which uses the Cyrillic alphabet.
The currency sign¤ is a character used to denote an unspecified currency. It can be described as a circle the size of a lowercase character with four short radiating arms at 45° (NE), 135° (SE), 225° (SW) and 315° (NW). It is raised slightly above the baseline. The character is sometimes called scarab.
YUSCII is an informal name for several JUS standards for 7-bit character encoding. These include:
GOST 10859 (1964) is a standard of the Soviet Union which defined how to encode data on punched cards. This standard allowed a variable word size, depending on the type of data being encoded, but only uppercase characters.

Extended ASCII is a repertoire of character encodings that include the original 96 ASCII character set, plus up to 128 additional characters. There is no formal definition of "extended ASCII", and even use of the term is sometimes criticized, because it can be mistakenly interpreted to mean that the American National Standards Institute (ANSI) had updated its ANSI X3.4-1986 standard to include more characters, or that the term identifies a single unambiguous encoding, neither of which is the case.
KOI8-RU is an 8-bit character encoding, designed to cover Russian, Ukrainian, and Belarusian which use a Cyrillic alphabet. It is closely related to KOI8-R, which covers Russian and Bulgarian, but replaces ten box drawing characters with five Ukrainian and Belarusian letters Ґ, Є, І, Ї, and Ў in both upper case and lower case. It is even more closely related to KOI8-U, which does not include Ў but otherwise makes the same letter replacements. The additional letter allocations are matched by KOI8-E, except for Ґ which is added to KOI8-F.
ISO-IR-153 is an 8-bit character set that covers the Russian and Bulgarian alphabets. Unlike the KOI encodings, this encoding lists the Cyrillic letters in their correct traditional order. This has become the basis for ISO/IEC 8859-5 and the Cyrillic Unicode block.
KOI8-F or KOI8 Unified is an 8-bit character set. It was designed by Peter Cassetta of Fingertip Software as an attempt to support all the encoded letters from both KOI8-E (ISO-IR-111) and KOI8-RU, along with some of the pseudographics from KOI8-R, with some additional punctuation in the remaining space, sourced partly from Windows-1251. This encoding was only used in the software of that company. FreeDOS calls it code page 60270.
ISO-IR-111 or KOI8-E is an 8-bit character set. It is a multinational extension of KOI-8 for Belarusian, Macedonian, Serbian, and Ukrainian. The name "ISO-IR-111" refers to its registration number in the ISO-IR registry, and denotes it as a set usable with ISO/IEC 2022.
DKOI is an EBCDIC encoding for Russian Cyrillic. It is a Telegraphy-based encoding used in ES EVM mainframes. It has been defined by several standards: GOST 19768-74 / ST SEV 358-76, ST SEV 358-88 / GOST 19768-93, CSN 36 9103.
References
- ↑ (in Russian) ГОСТ 19768-74 (СТ СЭВ 358-76). Машины вычислительные и система обработки данных. Коды 8-битные для обмена и обработки информации.
- ↑ (in Russian) Маркелова Л. Н. Эксплуатация программоуправляемой вычислительной машины «Искра 226». — М.: Машиностроение, 1987. — С. 41—42.
- ↑ "Locale::RecodeData::KOI_8 - search.cpan.org". search.cpan.org.
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |