Related Research Articles
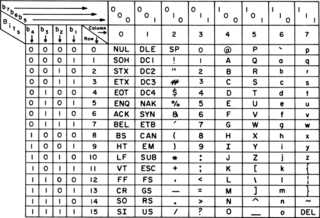
ASCII, abbreviated from American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text in computers, telecommunications equipment, and other devices. Most modern character-encoding schemes are based on ASCII, although they support many additional characters.

ISO/IEC 8859-1:1998, Information technology — 8-bit single-byte coded graphic character sets — Part 1: Latin alphabet No. 1, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. ISO 8859-1 encodes what it refers to as "Latin alphabet no. 1", consisting of 191 characters from the Latin script. This character-encoding scheme is used throughout the Americas, Western Europe, Oceania, and much of Africa. It is the basis for some popular 8-bit character sets and the first two blocks of characters in Unicode.
ISO/IEC 8859 is a joint ISO and IEC series of standards for 8-bit character encodings. The series of standards consists of numbered parts, such as ISO/IEC 8859-1, ISO/IEC 8859-2, etc. There are 15 parts, excluding the abandoned ISO/IEC 8859-12. The ISO working group maintaining this series of standards has been disbanded.
ISO/IEC 646 is the name of a set of ISO standards, described as Information technology — ISO 7-bit coded character set for information interchange and developed in cooperation with ASCII at least since 1964. Since its first edition in 1967 it has specified a 7-bit character code from which several national standards are derived.
ISO/IEC 8859-8, Information technology — 8-bit single-byte coded graphic character sets — Part 8: Latin/Hebrew alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings. ISO/IEC 8859-8:1999 from 1999 represents its second and current revision, preceded by the first edition ISO/IEC 8859-8:1988 in 1988. It is informally referred to as Latin/Hebrew. ISO/IEC 8859-8 covers all the Hebrew letters, but no Hebrew vowel signs. IBM assigned code page 916 to it. This character set was also adopted by Israeli Standard SI1311:2002, with some extensions.
ISO/IEC 8859-6:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 6: Latin/Arabic alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as Latin/Arabic. It was designed to cover Arabic. Only nominal letters are encoded, no preshaped forms of the letters, so shaping processing is required for display. It does not include the extra letters needed to write most Arabic-script languages other than Arabic itself.
ISO/IEC 2022Information technology—Character code structure and extension techniques, is an ISO standard specifying:
KOI (КОИ) is a family of several code pages for the Cyrillic script. The name stands for Kod obmena informatsiey which means "Code for Information Interchange".
KOI-7 (КОИ-7) is a 7-bit character encoding, designed to cover Russian, which uses the Cyrillic alphabet.
The currency sign¤ is a character used to denote an unspecified currency. It can be described as a circle the size of a lowercase character with four short radiating arms at 45° (NE), 135° (SE), 225° (SW) and 315° (NW). It is raised slightly above the baseline. The character is sometimes called scarab.
The C0 and C1 control code or control character sets define control codes for use in text by computer systems that use ASCII and derivatives of ASCII. The codes represent additional information about the text, such as the position of a cursor, an instruction to start a new line, or a message that the text has been received.
T.51 / ISO/IEC 6937:2001, Information technology — Coded graphic character set for text communication — Latin alphabet, is a multibyte extension of ASCII, or rather of ISO/IEC 646-IRV. It was developed in common with ITU-T for telematic services under the name of T.51, and first became an ISO standard in 1983. Certain byte codes are used as lead bytes for letters with diacritics (accents). The value of the lead byte often indicates which diacritic that the letter has, and the follow byte then has the ASCII-value for the letter that the diacritic is on.
The National Replacement Character Set (NRCS) was a feature supported by later models of Digital's (DEC) computer terminal systems, starting with the VT200 series in 1983. NRCS allowed individual characters from one character set to be replaced by one from another set, allowing the construction of different character sets on the fly. It was used to customize the character set to different local languages, without having to change the terminal's ROM for different countries, or alternately, include many different sets in a larger ROM. Many 3rd party terminals and terminal emulators supporting VT200 codes also supported NRCS.
The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in various national and international standards and used widely in international communication. They are the same letters that comprise the English alphabet.
The German standard DIN 66003, also known as Code page 1011 by IBM, Code page 20106 by Microsoft and D7DEC by Oracle, is a modification of 7-bit ASCII with adaptations for the German language, replacing certain symbol characters with umlauts and the eszett. It is the German national version of ISO/IEC 646, and also a localised option in DEC's National Replacement Character Set (NRCS) for their VT220 terminals.
The DEC Hebrew character set is an 8-bit character set developed by Digital Equipment Corporation (DEC) to support the Hebrew alphabet. It was derived from DEC's Multinational Character Set (MCS) by removing the existing definitions from code points 192 to 223 and 224 to 250 and replacing code points 251 to 256 by the Hebrew letters. This range corresponds to the Hebrew range of its 7-bit counterpart, but with the high bit set.
Macintosh Latin is a character encoding which is used by Kermit to represent text on the Apple Macintosh. It is a modification of Mac OS Icelandic to include all characters in ISO/IEC 8859-1, DEC MCS, the PostScript Standard Encoding, and a Dutch ISO 646 variant. Although Macintosh Latin is designed to be compatible with the standard Macintosh Mac OS Roman encoding for the shared subset of characters, the two should not be confused.
ELOT 927 is 7-bit character set standardized by ELOT, the Hellenic Organization for Standardization (HOS). It is also known as ISO-IR-88, CSISO88GREEK7 or 7-bit DEC Greek. The standard was withdrawn in November 1986. Support for it was implemented in various dot matrix printers and line printers as well as in computer terminals. Support for it can still be found in various applications, languages and protocols today, for example in Perl and Kermit.
INIS-8 is an 8-bit character encoding developed by the International Nuclear Information System (INIS). It is an 8-bit extension of the 7-bit INIS character set, adding a G1 set, and has MIB 52. It is also known as iso-ir-50 and csISO50INIS8.
References
- ↑ Hartman Kennelly, Cynthia (1991). Unch, Jacqueline (ed.). Digital Guide To Developing International Software (1 ed.). Digital Equipment Corporation. ISBN 1-55558-063-7. EY-F577E-DP.
- ↑ "Character sets". Kermit . Columbia University. 2000-01-01. Archived from the original on 2017-02-18. Retrieved 2017-02-18.
- ↑ "Hebrew Character Sets in Kermit 95". Kermit 95 Manual. Columbia University. Archived from the original on 2017-02-18. Retrieved 2017-02-18.
- ↑ "Hebrew 7-Bit Character Set". Kermit . Columbia University . Retrieved 2020-06-24.