The most commonly used EUC codes are variable-length encodings with a character belonging to an ISO/IEC 646 compliant coded character set (such as ASCII) taking one byte, and a character belonging to a 94×94 coded character set (such as GB 2312) represented in two bytes. The EUC-CN form of GB 2312 and EUC-KR are examples of such two-byte EUC codes. EUC-JP includes characters represented by up to three bytes, including an initial shift code, whereas a single character in EUC-TW can take up to four bytes.
Modern applications are more likely to use UTF-8, which supports all of the glyphs of the EUC codes, and more, and is generally more portable with fewer vendor deviations and errors. EUC is however still very popular, especially EUC-KR for South Korea.
Encoding structure
Relationship between packed EUC and other 8-bit ISO 2022 profiles
The structure of EUC is based on the ISO/IEC 2022 standard, which specifies a system of graphical character sets that can be represented with a sequence of the 94 7-bit bytes 0x21–7E, or alternatively 0xA1–FE if an eighth bit is available. This allows for sets of 94 graphical characters, or 8836 (942) characters, or 830584 (943) characters. Although initially 0x20 and 0x7F were always the space and delete character and 0xA0 and 0xFF were unused, later editions of ISO/IEC 2022 allowed the use of the bytes 0xA0 and 0xFF (or 0x20 and 0x7F) within sets under certain circumstances, allowing the inclusion of 96-character sets. The ranges 0x00–1F and 0x80–9F are used for C0 and C1 control codes.
EUC is a family of 8-bit profiles of ISO/IEC 2022, as opposed to 7-bit profiles such as ISO-2022-JP. As such, only ISO 2022 compliant character sets can have EUC forms. Up to four coded character sets (referred to as G0, G1, G2, and G3 or as code sets 0, 1, 2, and 3) can be represented with the EUC scheme. The G0 set is set to an ISO/IEC 646 compliant coded character set such as ASCII, ISO 646:KR (KS X 1003) or ISO 646:JP (the lower half of JIS X 0201) and invoked over GL (i.e. 0x21–0x7E, with the most significant bit cleared).[1] If ASCII is used, this makes the code an extended ASCII encoding; the most common deviation from ASCII is that 0x5C (backslash in ASCII) is often used to represent a yen sign in EUC-JP (see below) and a won sign in EUC-KR.
The other code sets are invoked over GR (i.e. with the most significant bit set). Hence, to get the EUC form of a character, the most significant bit of each coding byte is set (equivalent to adding 128 to each 7-bit coding byte, or adding 160 to each number in the kuten code); this allows the software to easily distinguish whether a particular byte in a character string belongs to the ISO 646 code or the extended code. Characters in code sets 2 and 3 are prefixed with the control codes SS2 (0x8E) and SS3 (0x8F) respectively, and invoked over GR. Besides the initial shift code, any byte outside of the range 0xA0–0xFF appearing in a character from code sets 1 through 3 is not a valid EUC code.[1]
The EUC code itself does not make use of the announcement and designation sequences from ISO 2022.[1] However, the code specification is equivalent to the following sequence of four ISO 2022 announcement sequences, with meanings breaking down as follows.[1]
Individual sequence
Hexadecimal
Feature of EUC denoted
ESC SP C
1B 20 43
ISO-8 (8-bit, G0 in GL, G1 in GR)
ESC SP Z
1B 20 5A
G2 accessed using SS2
ESC SP [
1B 20 5B
G3 accessed using SS3
ESC SP \
1B 20 5C
Single-shifts invoke over GR
Fixed-length format
Layout of the fixed-length format for Japanese
The ISO-2022-based variable-length encoding described above is sometimes referred to as the EUC packed format, which is the encoding format usually labeled as EUC. However, internal processing of EUC data may make use of a fixed-length transformation format called the EUC complete two-byte format. This represents:[2]
Code set 0 as two bytes in the range 0x21–0x7E (except that the first may be 0x00).
Code set 1 as two bytes in the range 0xA0–0xFF (except that the first may be 0x80).
Code set 2 as a byte in the range 0x21–0x7E (or 0x00) followed by a byte in the range 0xA0–0xFF.
Code set 3 as a byte in the range 0xA0–0xFF (or 0x80) followed by a byte in the range 0x21–0x7E.
Initial bytes of 0x00 and 0x80 are used in cases where the code set uses only one byte. There is also a four-byte fixed-length format.[2] These fixed-length encoding formats are suited to internal processing and are not usually encountered in interchange.
EUC-JP is registered with the IANA in both formats, the packed format as "EUC-JP" or "csEUCPkdFmtJapanese" and the fixed width format as "csEUCFixWidJapanese".[3] Only the packed format is included in the WHATWG Encoding Standard used by HTML5.[4]
EUC-CN[6] is the usual encoded form of the GB 2312 standard for simplified Chinese characters. Unlike the case of Japanese JIS X 0208 and ISO-2022-JP, GB 2312 is not normally used in a 7-bit ISO 2022 code version,[a] although a variant form called HZ (which delimits GB 2312 text with ASCII sequences) was sometimes used on USENET.
An ASCII character is represented in its usual encoding. A character from GB 2312 is represented by two bytes, both from the range 0xA1–0xFE.
748 code
An encoding related to EUC-CN is the "748" code used in the WITS typesetting system developed by Beijing's Founder Technology (now obsoleted by its newer FITS typesetting system). The 748 code contains all of GB 2312, but is not ISO 2022–compliant and therefore not a true EUC code. (It uses an 8-bit lead byte but distinguishes between a second byte with its most significant bit set and one with its most significant bit cleared, and is, therefore, more similar in structure to Big5 and other non–ISO 2022–compliant DBCS encoding systems.) The non-GB2312 portion of the 748 code contains traditional and Hong Kong characters and other glyphs used in newspaper typesetting.
IBM code pages 1380, 1381, 1382 and 1383
IBM code page 1381 (CCSID 1381) comprises the single-byte code page 1115 (CPGID 1115 as CCSID 1115) and the double-byte code page 1380 (CPGID 1380 as CCSID 1380),[7] which encodes GB 2312 the same way as EUC-CN, but deviates from the EUC structure by extending the lead byte range back to 0x8C, adding 31 IBM-selected characters in 0x8CE0 through 0x8CFE and adding 1880 user-defined characters with lead bytes 0x8D through 0xA0.[8]
IBM code page 1383 (CCSID 1383) comprises the single-byte code page 367 and the double-byte code page 1382 (CPGID 1382 as CCSID 1382),[9] which differs by conforming to the EUC structure, adding the 31 IBM-selected characters in 0xFEE0 through 0xFEFE instead, and including only 1360 user-defined characters, interspersed in the positions not used by GB 2312.[10] The alternative CCSID 5479[11] is used for the pure EUC-CN code page: it uses CCSID 9574 as its double-byte set, which uses CPGID 1382 but excludes the IBM-selected and user-defined characters.[12]
GBK is an extension to GB 2312. It defines an extended form of the EUC-CN encoding capable of representing a larger array of CJK characters sourced largely from Unicode 1.1, including traditional Chinese characters and characters used only in Japanese. It is not, however, a true EUC code, because ASCII bytes may appear as trail bytes (and C1 bytes, not limited to the single shifts, may appear as lead or trail bytes), due to a larger encoding space being required.
The Unicode-based GB 18030 character encoding defines an extension of GBK capable of encoding the entirety of Unicode. However, Unicode encoded as GB 18030 is a variable-length encoding which may use up to four bytes per character, due to an even larger encoding space being required. Being an extension of GBK, it is a superset of EUC-CN but is not itself a true EUC code. Being a Unicode encoding, its repertoire is identical to that of other Unicode transformation formats such as UTF-8.
Besides these changes to the lead byte range, the other distinctive feature of the double-byte portion of Mac OS Chinese Simplified is the inclusion of two extensions to the basic GB2312-80 set in rows 6 and 8.[6] These are considered "standard extensions to GB2312", neither of which is proprietary to Apple: the row 8 extension was taken from GB 6345.1,[6] both extensions are included by GB/T 12345 (the traditional Chinese variant of GB2312),[14] and both extensions are included by GB 18030 (the successor to GB2312).[15]
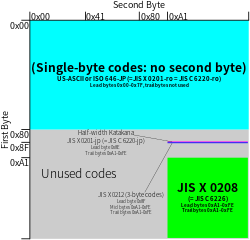
EUC-JP is a variable-length encoding used to represent the elements of three Japanese character set standards, namely JIS X 0208, JIS X 0212, and JIS X 0201. Other names for this encoding include Unixized JIS (or UJIS) and AT&T JIS.[2] Less than 0.1% of all web pages use EUC-JP as of February 2026,[16] while 2.1% of websites written with Japanese use this second-most popular (for Japanese) encoding[17] (which is more than for Shift JIS both are much less used that UTF-8). It is called Code page 954 by IBM.[18][19] Microsoft has two code page numbers for this encoding (51932 and 20932).
This encoding scheme allows the easy mixing of 7-bit ASCII and 8-bit Japanese without the need for the escape characters employed by ISO-2022-JP, which is based on the same character set standards, and without ASCII bytes appearing as trail bytes (unlike Shift JIS).
A related and partially compatible encoding, called EUC-JISx0213 or EUC-JIS-2004, encodes JIS X 0201 and JIS X 0213[20] (similarly to Shift_JISx0213, its Shift_JIS-based counterpart).
Compared to EUC-CN or EUC-KR, EUC-JP did not become as widely adopted on PC and Macintosh systems in Japan, which used Shift JIS or its extensions (Windows code page 932 on Microsoft Windows, and MacJapanese on classic Mac OS), although it became heavily used by Unix or Unix-like operating systems (except for HP-UX). Therefore, whether Japanese websites use EUC-JP or Shift_JIS often depends on what OS the author uses.
A graphical character from ASCII (code set 0) is represented as its usual one-byte representation, in the range 0x21 – 0x7E. While some variants of EUC-JP encode the lower half of JIS X 0201 here, most encode ASCII,[21] including the W3C/WHATWG Encoding standard used by HTML5,[22] and so does EUC-JIS-2004.[20] While this means that 0x5C is typically mapped to Unicode as U+005C REVERSE SOLIDUS (the ASCII backslash), U+005C may be displayed as a Yen sign by certain Japanese-locale fonts, e.g. on Microsoft Windows, for compatibility with the lower half of JIS X 0201.[23][24]
A character from JIS X 0208 (code set 1) is represented by two bytes, both in the range 0xA1 – 0xFE. This differs from the ISO-2022-JP representation by having the high bit set. This code set may also contain vendor extensions in some EUC-JP variants. In EUC-JIS-2004, the first plane of JIS X 0213 is encoded here, which is effectively a superset of standard JIS X 0208.[20]
A character from the upper half of JIS X 0201 (half-width kana, code set 2) is represented by two bytes, the first being 0x8E, the second being the usual JIS X 0201 representation in the range 0xA1 – 0xDF. This set may contain IBM vendor extensions in some variants.
A character from JIS X 0212 (code set 3) is represented in EUC-JP by three bytes, the first being 0x8F, the following two being in the range 0xA1–0xFE, i.e. with the high bit set. In addition to standard JIS X 0212, code set 3 of some EUC-JP variants may also contain extensions in rows 83 and 84 to represent characters from IBM's Shift JIS extensions which lack standard JIS X 0212 mappings, which may be coded in either of two layouts, one defined by IBM themselves and one defined by the OSF.[25][26] In EUC-JIS-2004, the second plane of JIS X 0213 is encoded here,[20] which does not collide with the allocated rows in standard JIS X 0212.[27] Some implementations of EUC-JIS-2004, such as the one used by Python, allow both JIS X 0212 and JIS X 0213 plane 2 characters in this set.[27]
Vendor extensions to EUC-JP (from, for example, the Open Software Foundation, IBM or NEC) were often allocated within the individual code sets,[25][26] as opposed to using invalid EUC sequences (as in popular extensions of EUC-CN and EUC-KR).
However, some vendor-specific encodings are partially compatible with EUC-JP, due to encoding JIS X 0208 over GR, but do not follow the packed EUC structure. Often, these do not include use of the single shifts from EUC-JP, and are thus not straight extensions of EUC-JP, with the exception of Super DEC Kanji.
DEC Kanji
Digital Equipment Corporation defines two variants of EUC-JP only partly conforming to the EUC packed format, but also bearing some resemblance to the complete two-byte format. The overall format of the "DEC Kanji" encoding mostly corresponds to fixed-length (complete two-byte) EUC; however, code set 0 is not required to be left-padded with null bytes (similarly to the packed format).[28] JIS X 0208 is, as usual, used for code set 1; code set 2 (half-width katakana) is absent; code set 3 is encoded like the two-byte fixed width format (i.e. without a shift byte and with only the first high bit set), but used for two-byte user defined characters rather than being specified for JIS X 0212.[28] In the basic "DEC Kanji" encoding, only the first 31 rows of code set 3 are used for user-defined characters: rows 32 through 94 are reserved, similarly to the unused rows in code set 1.[29]
The "Super DEC Kanji" encoding accepts codes both from the "DEC Kanji" encoding and from packed-format EUC, for a total of five code-sets.[28] It also allows the entire user defined code set, and the unused rows at the ends of the JIS X 0208 and JIS X 0212 code sets (rows 85–94 and 78–94 respectively), to be used for user-defined characters.[29]
HP-16
Hewlett-Packard defines an encoding referred to as "HP-16". This accompanies their "HP-15" encoding, which is a variant of Shift JIS. HP-16 encodes JIS X 0208 using the same bytes as in EUC-JP, but does not use the single shift codes (thus omitting code sets 2 and 3), and adds three user-defined regions which do not follow the packed-format EUC structure:[28]
Lead bytes 0xA1–C2, trail bytes 0x21–7E
Lead bytes 0xC3–E3, trail bytes 0x21–3F
Lead bytes 0xC3–E1, trail bytes 0x40–64
IKIS
The IKIS (Interactive Kanji Information System) encoding used by Data General resembles EUC-JP without single shifts, i.e. with only code sets 0 and 1. Half-width katakana are instead included in row 8 of JIS X 0208 (colliding with the box-drawing characters added to the standard in 1983). JIS X 0208 rows 9 through 12 are used for user-defined characters.[28][29]
KEIS (Kanji-processing Extended Information System) is an EBCDIC encoding used by Hitachi,[29] with double-byte characters (a DBCS-Host encoding) included using shifting sequences, making it a stateful encoding. Specifically, the sequence 0x0A 0x41 switches to single-byte mode and the sequence 0x0A 0x42 switches to double-byte mode.[b] However, JIS X 0208 characters are encoded using the same byte sequences used to encode them in EUC-JP. This results in duplicate encodings for the ideographic space—0x4040 per the DBCS-Host code structure, and 0xA1A1 as in EUC-JP. This differs from IBM's DBCS-Host encoding for Japanese, the layout of which builds on versions which predate JIS X 0208 altogether. The lead byte range is extended back to 0x59, out of which the lead bytes 0x81–A0 are designated for user-defined characters,[28] and the remainder are used for corporate-defined characters, including both kanji and non-kanji.[29]
JEF (Japanese-processing Extended Feature)[29] is an EBCDIC encoding used on Fujitsu FACOM mainframes, contrasting with FMR (a variant of ShiftJIS) used on Fujitsu PCs. Like KEIS, JEF is a stateful encoding, switching to a double-byte DBCS-Host mode using shifting sequences (where 0x29 switches to single-byte mode and 0x28 switches to double-byte mode).[30] Also similarly to KEIS, JIS X 0208 codes are represented the same as in EUC-JP.[28] The lead byte range is extended back to 0x41, with 0x80–0xA0 designated for user definition; lead bytes 0x41–0x7F are assigned row numbers 101 through 163 for kuten purposes, although row 162 (lead byte 0x7E) is unused.[28][29] Rows 101 through 148 are used for extended kanji, while rows 149 through 163 are used for extended non-kanji.[29]
EUC-KR
"EUC-KR" redirects here. For the variant so named in HTML standards, see Unified Hangul Code.
EUC-KR is a variable-length encoding to represent Korean text using two coded character sets, KS X 1001 (formerly KS C 5601)[31][32] and either ISO 646:KR (KS X 1003, formerly KS C 5636) or ASCII, depending on variant. KS X 2901 (formerly KS C 5861) stipulates the encoding and RFC1557 dubbed it as EUC-KR.
A character drawn from KS X 1001 (G1, code set 1) is encoded as two bytes in GR (0xA1–0xFE) and a character from KS X 1003 or ASCII (G0, code set 0) takes one byte in GL (0x21–0x7E).
It is usually referred to as Wansung (Korean:완성;RR:Wanseong;lit.precomposed[33]) in the Republic of Korea. IBM refers to the double-byte component as Code page 971,[34] and to EUC-KR with ASCII as Code page 970.[35][36][37] It is implemented as Code page 20949 ("Korean Wansung")[38][39] and Code page 51949 ("EUC Korean") by Microsoft.[38]
As of October2025[update], less than 0.06% of all web pages globally declare using EUC-KR,[40] but 4.0% of South Korean web pages use EUC-KR.[41] Including extensions, it is the most widely used legacy character encoding in Korea on all three major platforms (macOS, other Unix-like OSes, and Windows), but its use has been very slowly shifting to UTF-8 as it gains popularity, especially on Linux and macOS.
As with most other encodings, UTF-8 is now preferred for new use, solving problems with consistency between platforms and vendors.
A common extension of EUC-KR is the Unified Hangul Code (통합형 한글 코드;Tonghabhyeong Hangeul Kodeu,[42] or 통합 완성형;Tonghab Wansunghyung), which is the default Korean codepage on Microsoft Windows. It is given the code page number 949 by Microsoft, and 1261[43] or 1363[44] by IBM. IBM's code page 949 is a different, unrelated, EUC-KR extension.
Unified Hangul Code extends EUC-KR by using codes that do not conform to the EUC structure to incorporate additional syllable blocks, completing the coverage of the composed syllable blocks available in Johab and Unicode. The W3C/WHATWG Encoding Standard used by HTML5 incorporates the Unified Hangul Code extensions into its definition of EUC-KR.[45]
Mac OS Korean (HangulTalk)
Other encodings incorporating EUC-KR as a subset include the Mac OS Korean script (known as Code page 10003 or x-mac-korean),[13] which was used by HangulTalk (MacOS-KH), the Korean localization of the classic Mac OS. It was developed by Elex Computer (일렉스), who were at the time the authorised distributor of Apple Macintosh computers in South Korea.[46][29]
HangulTalk adds extension characters with lead bytes between 0xA1 and 0xAD, both in unused space within the EUC-KR GR plane (trail bytes 0xA1–0xFE), and using non-EUC codes outside of it (trail bytes 0x41–0xA0). Some of these characters are font-style-independent stylized dingbats.[29] Many of these characters do not have exact Unicode mappings, and Apple software maps these cases variously to combining sequences, to approximate mappings with an appended private-use character as a modifier for round-trip purposes, or to private-use characters.[47]
Similarly to KS X 1001, the North Korean KPS 9566 standard is typically used in EUC form; in these contexts, it is sometimes referred to as EUC-KP.[48] More recent editions of the standard extend the EUC representation with characters using non-EUC two-byte codes, in a similar manner to Unified Hangul Code.[49]
EUC-TH
Although certain single-byte encodings such as the ISO/IEC 8859 series technically conform to the EUC structure, they are rarely labeled as EUC. However, eucTH is used on Solaris as a label for TIS-620.[50]
EUC-TW
EUC-TW is a variable-length encoding that supports ASCII and 16 planes of CNS 11643, each of which is 94×94. It is a rarely used encoding for traditional Chinese characters as used in Taiwan. Variants of Big5 are much more common than EUC-TW, although Big5 only encodes the first two planes of CNS11643 hanzi, while UTF-8 is becoming more common.
↑7-bit ISO 2022 code versions supporting GB 2312 include ISO-2022-CN (with shift codes) and ISO-2022-JP-2 (without shift codes), both of which also support other non-ASCII sets.
↑These sequences match the hexadecimal forms shown by DEC[30] and the decimal forms (10 65 and 10 66) listed by Lunde.[28] Lunde lists the hexadecimal forms for both as 0xA0 0x42, seemingly in error.
↑"EUC-JP decoder". Encoding Standard. WHATWG. "If the byte is an ASCII byte, return a code point whose value is a byte."
↑"3.1.1 Details of Problems". Problems and Solutions for Unicode and User/Vendor Defined Characters. The Open Group Japan. Archived from the original on 1999-02-03. Retrieved 2019-08-14.
↑In ucnv_lmb.cpp, a file originating from IBM and included in the International Components for Unicode source tree, the lead byte 0x11 is commented as referring to "Korean: ibm-1261" after the definition of ULMBCS_GRP_KO, and is mapped to the "windows-949" ICU codec in the OptGroupByteToCPName array later in the file.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.