Related Research Articles
Big-5 or Big5 is a Chinese character encoding method used in Taiwan, Hong Kong, and Macau for traditional Chinese characters.
ISO/IEC 8859-11:2001, Information technology — 8-bit single-byte coded graphic character sets — Part 11: Latin/Thai alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 2001. It is informally referred to as Latin/Thai. It is nearly identical to the national Thai standard TIS-620 (1990). The sole difference is that ISO/IEC 8859-11 allocates non-breaking space to code 0xA0, while TIS-620 leaves it undefined.
ISO/IEC 8859-7:2003, Information technology — 8-bit single-byte coded graphic character sets — Part 7: Latin/Greek alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as Latin/Greek. It was designed to cover the modern Greek language. The original 1987 version of the standard had the same character assignments as the Greek national standard ELOT 928, published in 1986. The table in this article shows the updated 2003 version which adds three characters. Microsoft has assigned code page 28597 a.k.a. Windows-28597 to ISO-8859-7 in Windows. IBM has assigned code page 813 to ISO 8859-7. (IBM CCSID 813 is the original encoding. CCSID 4909 adds the euro sign. CCSID 9005 further adds the drachma sign and ypogegrammeni.)
Extended Unix Code (EUC) is a multibyte character encoding system used primarily for Japanese, Korean, and simplified Chinese (characters).
The Hong Kong Supplementary Character Set is a set of Chinese characters – 4,702 in total in the initial release—used in Cantonese, as well as when writing the names of some places in Hong Kong.

Code page 855 is a code page used under DOS to write Cyrillic script.
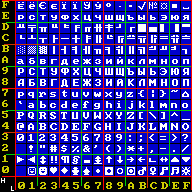
Code page 866 is a code page used under DOS and OS/2 in Russia to write Cyrillic script. It is based on the "alternative code page" developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR. The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 and maintains alphabetic order of Cyrillic letters. Initially this encoding was only available in the Russian version of MS-DOS 4.01 (1990), but with MS-DOS 6.22 it became available in any language version.

Code page 950 is the code page used on Microsoft Windows for Traditional Chinese. It is Microsoft's implementation of the de facto standard Big5 character encoding. The code page is not registered with IANA, and hence, it is not a standard to communicate information over the internet, although it is usually labelled simply as big5, including by Microsoft library functions.
Code page 856, is a code page used under DOS for Hebrew in Israel.

IBM code page 949 (IBM-949) is a character encoding which has been used by IBM to represent Korean language text on computers. It is a variable-width encoding which represents the characters from the Wansung code defined by the South Korean standard KS X 1001 in a format compatible with EUC-KR, but adds IBM extensions for additional hanja, additional precomposed Hangul syllables, and user-defined characters.
IBM code page 936 is a character encoding for Simplified Chinese including 1880 user-defined characters (UDC), which was superseded in 1993. It is a combination of the single-byte Code page 903 and the double-byte Code page 928. Code page 946 uses the same double-byte component, but an extended single-byte component.
Code page 951 is a code page number used for different purposes by IBM and Microsoft.
Code page 897 is IBM's implementation of the 8-bit form of JIS X 0201. It includes several additional graphical characters in the C0 control characters area, and the code points in question may be used as control characters or graphical characters depending on the context, similarly in concept to OEM-US, but with different graphical characters. The C0 rows are shown below.
Code page 896, called Japan 7-Bit Katakana Extended, is IBM's code page for code-set G2 of EUC-JP, a 7-bit code page representing the Kana set of JIS X 0201 and accompanying Code page 895 which corresponds to the lower half of that standard. It encodes half-width katakana.
Code page 903 is encoded for use as the single byte component of certain simplified Chinese character encodings. It is used in China. Despite this, it follows ISO 646-JP / the Roman half of JIS X 0201, in that it replaces the ASCII backslash 0x5C with the yen/yuan sign. It also uses the same C0 replacement graphics as code page 897. When combined with the double-byte Code page 928, it forms the two code-sets of IBM code page 936.
Code page 904 is encoded for use as the single byte component of certain traditional Chinese character encodings. It is used in Taiwan. When combined with the double-byte Code page 927, it forms the two code-sets of Code page 938.
Code page 1040, also known as Korean PC Data Extended, is a single byte character set (SBCS) used by IBM in its PC DOS operating system for Hangul. It is an extended version of the 8-bit form of the N-byte Hangul Code first specified by the 1974 edition of KS C 5601.
Code page 1043, also known as Traditional Chinese PC Data Extended, is a single byte character set (SBCS) used by IBM in its PC DOS operating system. This code page is intended for use with code page 927. It is an extension of Code page 904.
Code page 1115, also known as Simplified Chinese PC Data, is a single byte character set (SBCS) used by IBM in its PC DOS operating system in China.
Several mutually incompatible versions of the Extended Binary Coded Decimal Interchange Code (EBCDIC) have been used to represent the Japanese language on computers, including variants defined by Hitachi, Fujitsu, IBM and others. Some are variable-width encodings, employing locking shift codes to switch between single-byte and double-byte modes. Unlike other EBCDIC locales, the lowercase basic Latin letters are often not preserved in their usual locations.
References
- 1 2 3 4 "Code page 1042 information document". Archived from the original on 2017-01-16.
- ↑ "CCSID 1042 information document". Archived from the original on 2016-03-27.
- ↑ "Code page 928 information document". Archived from the original on 2016-03-17.
- ↑ "CCSID 928 information document". Archived from the original on 2016-03-26.
- ↑ Code Page CPGID 01042 (pdf) (PDF), IBM
- ↑ Code Page CPGID 01042 (txt), IBM
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |