↑Not in the strictest sense of the term, as ASCII bytes can appear as trail bytes.
GBK is an extension of the GB 2312character set for Simplified Chinese characters, used in the People's Republic of China. It includes all unified CJK characters found in GB 13000.1-93, i.e. ISO/IEC 10646:1993, or Unicode 1.1. Since its initial release in 1993, GBK has been extended by Microsoft in Code page 936/1386, which was then extended into GBK 1.0. GBK is also the IANA-registered internet name for the Microsoft mapping,[1] which differs from other implementations primarily by the single-byte euro sign at 0x80.
GB abbreviates Guójiā Biāozhǔn, which means national standard in Chinese, while K stands for Extension (扩展 kuòzhǎn). GBK not only extended the old standard GB 2312 with Traditional Chinese characters, but also with Chinese characters that were simplified after the establishment of GB 2312 in 1981. With the arrival of GBK, certain names with characters formerly unrepresentable, like the 镕 (róng) character in former Chinese Premier Zhu Rongji's name, are now representable.[2]
As of December2025[update], GBK is the third-most declared encoding served from China and territories (after UTF-8 and the subset GB 2312), with 1.3% of web servers serving a page that declares GBK.[3] However, all major web browsers decode GB2312-marked documents as if they were marked GBK, i.e. not as a subset (meaning in effect GBK is the second-most popular encoding) except for Safari and Edge on the label GB_2312 (they do however decode GB_2312-80 and GB2312 as the superset GBK).[4] Together, GBK and GB 2312 encodings have a combined 3.5% presence in China and territories.[3] Globally, GBK accounts for less than 0.02% of all web pages and GBK+GB2312 for less than 0.07%.[5]
History
In 1993, the Unicode 1.1 standard was released, including 20,902 characters used in mainland China, Taiwan, Japan and Korea. Following this, China released GB 13000.1-93, the Guobiao standard equivalent of Unicode 1.1.
The GBK character set was defined in 1993 as an extension of GB 2312-80, while also including the characters of GB 13000.1-93 through the unused codepoints available in GB 2312. Hence GBK is backward compatible with GB 2312. GBK was defined in a normative annex to GB 13000.1-93.[6]
Microsoft implemented GBK in Windows 95 and Windows NT 3.51 as Code Page 936. While GBK was never an official standard, widespread usage of Windows 95 led to GBK becoming the de facto standard. While GBK included all the Chinese characters defined in Unicode 1.1 and GB 13000.1-93, these standards used different code tables. The primary reason for its existence was simply to bridge the gap between GB 2312-80 and GB 13000.1-93.
In 1995, China National Information Technology Standardization Technical Committee set down the Chinese Internal Code Extension Specification (Chinese:汉字内码扩展规范 (GBK); pinyin:Hànzì Nèimǎ Kuòzhǎn Guīfàn (GBK)), Version 1.0, known as GBK1.0, which is a slight extension of Codepage 936. The newly added 95 characters were not found in GB13000.1-1993, and were provisionally assigned Unicode PUA code points.[7]:534
Microsoft later added the euro sign to Code page 936 and assigned the code 0x80 to it. This is not a valid code point in GBK1.0.
In 2000, the GB 18030-2000 standard was released, superseding yet maintaining compatibility with GBK1.0. It increased the number of definitions of Chinese characters and extended the number of possible characters through the implementation of four-byte character spaces. The subset of GB18030 consisting of one-byte and two-byte characters is sometimes also referred to as GBK. Mapping to Unicode has been slightly changed, though, as some characters are now defined in Unicode. In the most up-to-date form of the standard, GB18030-2005, only 24[8] characters are still mapped to Unicode PUA (see GB 18030#PUA.)
In 2002, GBK was registered as an IANA charset; the registration uses code page 936 mapping as well as CP936/MS936 aliases, but refers to GBK1.0 specification.[1]W3C's technical recommendation published in 2015[9] defines a GBKencoder as a GB18030 encoder with a single-byte euro sign and without four-byte sequences (while W3C's GBKdecoder specification has no such limitation, decodes as GB 18030, i.e. with same range of letters as all of Unicode).
Encoding
A character is encoded as 1 or 2 bytes. A byte in the range 00–7F is a single byte that means the same thing as it does in ASCII. Strictly speaking, there are 95 characters and 33 control codes in this range.
A byte with the high bit set indicates that it is the first of 2 bytes. Loosely speaking, the first byte is in the range 81–FE (that is, never 80 or FF), and the second byte is 40–A0 except 7F for some areas and A1–FE for others.
More specifically, the following ranges of bytes are defined:
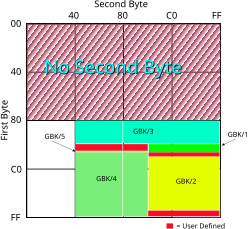
In graphical form, the following figure shows the space of all 64K possible 2-byte codes. Green and yellow areas are assigned GBK codepoints, red are for user-defined characters. The uncolored areas are invalid byte combinations.
Relationship to other encodings
The areas indicated in the previous section as GBK/1 and GBK/2, taken by themselves, is simply GB 2312-80 in its usual encoding, GBK/1 being the non-hanzi region and GBK/2 the hanzi region. GB 2312, or more properly the EUC-CN encoding thereof, takes a pair of bytes from the range A1–FE, like any 94² ISO-2022 character set loaded into GR. This corresponds to the lower-right quarter of the illustration above. However, GB 2312 does not assign any code points to the rows located at AA–B0 and F8–FE, even though it had staked out the territory. GBK added extensions to these rows. You can see that the two gaps were filled in with user-defined areas.
More significantly, GBK extended the range of the bytes. Having two-byte characters in the ISO-2022 GR range gives a limit of 94²=8,836 possibilities. Abandoning the ISO-2022 model of strict regions for graphics and control characters, but retaining the feature of low bytes being 1-byte characters and pairs of high bytes denoting a character, you could potentially have 128²=16,384 positions. GBK takes part of that, extending the range from A1–FE (94 choices for each byte) to 81–FE (126 choices) for the first byte and 40–FE (191 choices) for the second byte, for a total of 24,066 positions.
Microsoft's Code Page 936 is generally thought of as being GBK.[1] However, the 95 PUA characters added in GBK 1.0 are not included in Code Page 936. Code Page 936 also has a single-byte euro sign at 0x80 which GBK 1.0 doesn't have.[10]
GBK's successor, GB 18030-2000, uses the remaining range available to the second byte (30–39) to further expand the number of possibilities while retaining GBK as a subset.
↑"18.2: Ideographic Description Characters"(PDF). The Unicode Standard. Version 15.0.0. 2022. p.763. The Ideographic Description characters are found in GBK—an extension to GB 2312-80 that added all 20,902 Unicode Version 1.1 ideographs not already in GB 2312-80. GBK is defined as a normative annex of GB 13000.1-93.
Mapping of GBK to Unicode N.B.: this is Microsoft code page 936, which contains entries for 21791 double-byte code points, 96 single-byte graphic characters, and 33 control characters. This is not exactly the same as GBK which has 21886 characters.
GBK Code Table N.B. This gbk-encoded page shows the available coding space totally populated except for 2 places, for a total of 32256 glyphs (32352 with the implied single-byte ASCII codes not illustrated), which is more than 23940 or 21886. Actual rendering of this table depends on your browser's GBK decoder.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.