Big-5 or Big5 is a Chinese character encoding method used in Taiwan, Hong Kong, and Macau for traditional Chinese characters.
In computing, Chinese character encodings can be used to represent text written in the CJK languages—Chinese, Japanese, Korean—and (rarely) obsolete Vietnamese, all of which use Chinese characters. Several general-purpose character encodings accommodate Chinese characters, and some of them were developed specifically for Chinese.
ISO/IEC 8859-7:2003, Information technology — 8-bit single-byte coded graphic character sets — Part 7: Latin/Greek alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as Latin/Greek. It was designed to cover the modern Greek language. The original 1987 version of the standard had the same character assignments as the Greek national standard ELOT 928, published in 1986. The table in this article shows the updated 2003 version which adds three characters. Microsoft has assigned code page 28597 a.k.a. Windows-28597 to ISO-8859-7 in Windows. IBM has assigned code page 813 to ISO 8859-7. (IBM CCSID 813 is the original encoding. CCSID 4909 adds the euro sign. CCSID 9005 further adds the drachma sign and ypogegrammeni.)
Extended Unix Code (EUC) is a multibyte character encoding system used primarily for Japanese, Korean, and simplified Chinese (characters).
GB/T 2312-1980 is a key official character set of the People's Republic of China, used for Simplified Chinese characters. GB2312 is the registered internet name for EUC-CN, which is its usual encoded form. GB refers to the Guobiao standards (国家标准), whereas the T suffix denotes a non-mandatory standard.
Windows-1257 is an 8-bit, single-byte extended ASCII code page used to support the Estonian, Latvian and Lithuanian languages under Microsoft Windows. In Lithuania, it is standardised as LST 1590-3, alongside a modified variant named LST 1590-4.
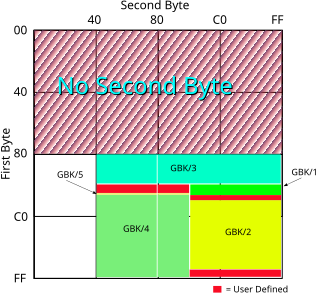
GBK is an extension of the GB 2312 character set for Simplified Chinese characters, used in the People's Republic of China. It includes all unified CJK characters found in GB 13000.1-93, i.e. ISO/IEC 10646:1993, or Unicode 1.1. Since its initial release in 1993, GBK has been extended by Microsoft in Code page 936/1386, which was then extended into GBK 1.0. GBK is also the IANA-registered internet name for the Microsoft mapping, which differs from other implementations primarily by the single-byte euro sign at 0x80.
Windows code page 936, is Microsoft's legacy (pre-Unicode) character encoding for representing simplified Chinese text on computers. It is one of the four Windows DBCSs for East Asian languages, accompanying code pages 932 (Japanese), 949 (Korean) and 950. It is a variant of the Mainland Chinese Guójiā Biāozhǔn Kuòzhǎn (GBK) encoding, and roughly corresponds to IBM code page 1386.

Code page 950 is the code page used on Microsoft Windows for Traditional Chinese. It is Microsoft's implementation of the de facto standard Big5 character encoding. The code page is not registered with IANA, and hence, it is not a standard to communicate information over the internet, although it is usually labelled simply as big5, including by Microsoft library functions.
IBM code page 932 is one of IBM's extensions of Shift JIS. The coded character sets are JIS X 0201:1976, JIS X 0208:1983, IBM extensions and IBM extensions for IBM 1880 UDC. It is the combination of the single-byte Code page 897 and the double-byte Code page 301. Code page 301 is designed to encode the same repertoire as IBM Japanese DBCS-Host.

Unified Hangul Code (UHC), or Extended Wansung, also known under Microsoft Windows as Code Page 949, is the Microsoft Windows code page for the Korean language. It is an extension of Wansung Code to include all 11172 non-partial Hangul syllables present in Johab. This corresponds to the pre-composed syllables available in Unicode 2.0 and later.

JIS X 0201, a Japanese Industrial Standard developed in 1969, was the first Japanese electronic character set to become widely used. The character set was initially known as JIS C 6220 before the JIS category reform. Its two forms were a 7-bit encoding or an 8-bit encoding, although the 8-bit form was dominant until Unicode replaced it. The full name of this standard is 7-bit and 8-bit coded character sets for information interchange (7ビット及び8ビットの情報交換用符号化文字集合).
JIS X 0212 is a Japanese Industrial Standard defining a coded character set for encoding supplementary characters for use in Japanese. This standard is intended to supplement JIS X 0208. It is numbered 953 or 5049 as an IBM code page.
In mathematics, the radical symbol, radical sign, root symbol, radix, or surd is a symbol for the square root or higher-order root of a number. The square root of a number x is written as
The CCITT Chinese Primary Set is a multi-byte graphic character set for Chinese communications created for the Consultative Committee on International Telephone and Telegraph (CCITT) in 1992. It is defined in ITU T.101, annex C, which codifies Data Syntax 2 Videotex. It is registered with the ISO-IR registry for use with ISO/IEC 2022 as ISO-IR-165, and encodable in the ISO-2022-CN-EXT code version.
Microsoft Windows code page 932, also called Windows-31J amongst other names, is the Microsoft Windows code page for the Japanese language, which is an extended variant of the Shift JIS Japanese character encoding. It contains standard 7-bit ASCII codes, and Japanese characters are indicated by the high bit of the first byte being set to 1. Some code points in this page require a second byte, so characters use either 8 or 16 bits for encoding.
Code page 942 is one of IBM's extensions of Shift JIS. The coded character sets are JIS X 0201, JIS X 0208, IBM extensions for IBM 1880 UDC and IBM extensions. It is the combination of the single-byte Code page 1041 and the double-byte Code page 301.

IBM code page 949 (IBM-949) is a character encoding which has been used by IBM to represent Korean language text on computers. It is a variable-width encoding which represents the characters from the Wansung code defined by the South Korean standard KS X 1001 in a format compatible with EUC-KR, but adds IBM extensions for additional hanja, additional precomposed Hangul syllables, and user-defined characters.
Code page 903 is encoded for use as the single byte component of certain simplified Chinese character encodings. It is used in China. Despite this, it follows ISO 646-JP / the Roman half of JIS X 0201, in that it replaces the ASCII backslash 0x5C with the yen/yuan sign. It also uses the same C0 replacement graphics as code page 897. When combined with the double-byte Code page 928, it forms the two code-sets of IBM code page 936.
Several mutually incompatible versions of the Extended Binary Coded Decimal Interchange Code (EBCDIC) have been used to represent the Japanese language on computers, including variants defined by Hitachi, Fujitsu, IBM and others. Some are variable-width encodings, employing locking shift codes to switch between single-byte and double-byte modes. Unlike other EBCDIC locales, the lowercase basic Latin letters are often not preserved in their usual locations.
