This article includes a list of references, related reading or external links, but its sources remain unclear because it lacks inline citations .(January 2023) |
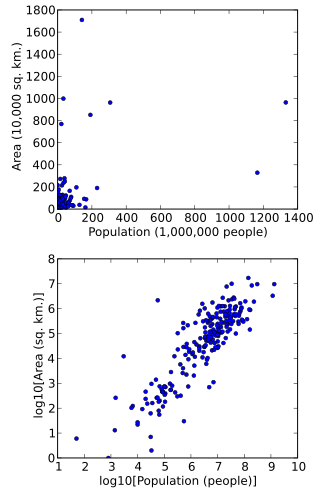
In probability and statistics, the parabolic fractal distribution is a type of discrete probability distribution in which the logarithm of the frequency or size of entities in a population is a quadratic polynomial of the logarithm of the rank (with the largest example having rank 1). This can markedly improve the fit over a simple power-law relationship (see references below).
Contents
In the Laherrère/Deheuvels paper below, examples include galaxy sizes (ordered by luminosity), towns (in the USA, France, and world), spoken languages (by number of speakers) in the world, and oil fields in the world (by size). They also mention utility for this distribution in fitting seismic events (no example). The authors assert the advantage of this distribution is that it can be fitted using the largest known examples of the population being modeled, which are often readily available and complete, then the fitted parameters found can be used to compute the size of the entire population. So, for example, the populations of the hundred largest cities on the planet can be sorted and fitted, and the parameters found used to extrapolate to the smallest villages, to estimate the population of the planet. Another example is estimating total world oil reserves using the largest fields.
In a number of applications, there is a so-called King effect where the top-ranked item(s) have a significantly greater frequency or size than the model predicts on the basis of the other items. The Laherrère/Deheuvels paper shows the example of Paris, when sorting the sizes of towns in France. When the paper was written Paris was the largest city with about ten million inhabitants, but the next largest town had only about 1.5 million. Towns in France excluding Paris closely follow a parabolic distribution, well enough that the 56 largest gave a very good estimate of the population of the country. But that distribution would predict the largest city to have about two million inhabitants, not 10 million. The King Effect is named after the notion that a King must defeat all rivals for the throne and takes their wealth, estates and power, thereby creating a buffer between himself and the next-richest of his subjects. That specific effect (intentionally created) may apply to corporate sizes, where the largest businesses use their wealth to buy up smaller rivals. Absent intent, the King Effect may occur as a result of some persistent growth advantage due to scale, or to some unique advantage. Larger cities are more efficient connectors of people, talent and other resources. Unique advantages might include being a port city, or a Capital city where law is made, or a center of activity where physical proximity increases opportunity and creates a feedback loop. An example is the motion picture industry; where actors, writers and other workers move to where the most studios are, and new studios are founded in the same place because that is where the most talent resides.
To test for the King Effect, the distribution must be fitted excluding the 'k' top-ranked items, but without assigning new rank numbers to the remaining members of the population. For example, in France the ranks are (as of 2010):
- Paris, 12.09M
- Lyon, 2.12M
- Marseille, 1.72M
- Toulouse, 1.20M
- Lille, 1.15M
A fitting algorithm would process pairs {(1,12.09), (2,2.12), (3,1.72), (4,1.20), (5,1.15)} and find the parameters for the best parabolic fit through those points. To test for the King Effect we just exclude the first pair (or first 'k' pairs), and find parabolic parameters that fit the remainder of the points. So for France we would fit the four points {(2,2.12), (3,1.72), (4,1.20), (5,1.15)}. Then we can use those parameters to estimate the size of cities ranked [1,k] and determine if they are King Effect members or normal members.
By comparison, Zipf's law fits a line through the points (also using the log of the rank and log of the value). A parabola (with one more parameter) will fit better, but far from the vertex the parabola is also nearly linear. Thus, although it is a judgment call for the statistician, if the fitted parameters put the vertex far from the points fitted, or if the parabolic curve is not a significantly better fit than a line, those may be symptomatic of overfitting (aka over-parameterization). The line (with two parameters instead of three) is probably the better generalization. More parameters always fit better, but at the cost of adding unexplained parameters or unwarranted assumptions (such as the assumption that a slight parabolic curve is a more appropriate model than a line).
Alternatively, it is possible to force the fitted parabola to have its vertex at the rank 1 position. In that case, it is not certain the parabola will fit better (have less error) than a straight line; and the choice might be made between the two based on which has the least error.