The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution, Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.

The Pareto distribution, named after the Italian civil engineer, economist, and sociologist Vilfredo Pareto, is a power-law probability distribution that is used in description of social, quality control, scientific, geophysical, actuarial, and many other types of observable phenomena; the principle originally applied to describing the distribution of wealth in a society, fitting the trend that a large portion of wealth is held by a small fraction of the population. The Pareto principle or "80-20 rule" stating that 80% of outcomes are due to 20% of causes was named in honour of Pareto, but the concepts are distinct, and only Pareto distributions with shape value of log45 ≈ 1.16 precisely reflect it. Empirical observation has shown that this 80-20 distribution fits a wide range of cases, including natural phenomena and human activities.

In probability theory and statistics, the chi-squared distribution with degrees of freedom is the distribution of a sum of the squares of independent standard normal random variables.

In probability theory and statistics, the Rayleigh distribution is a continuous probability distribution for nonnegative-valued random variables. Up to rescaling, it coincides with the chi distribution with two degrees of freedom. The distribution is named after Lord Rayleigh.
In statistics, the Wishart distribution is a generalization of the gamma distribution to multiple dimensions. It is named in honor of John Wishart, who first formulated the distribution in 1928. Other names include Wishart ensemble, or Wishart–Laguerre ensemble, or LOE, LUE, LSE.
In physics, the Hamilton–Jacobi equation, named after William Rowan Hamilton and Carl Gustav Jacob Jacobi, is an alternative formulation of classical mechanics, equivalent to other formulations such as Newton's laws of motion, Lagrangian mechanics and Hamiltonian mechanics.

In probability theory, the Rice distribution or Rician distribution is the probability distribution of the magnitude of a circularly-symmetric bivariate normal random variable, possibly with non-zero mean (noncentral). It was named after Stephen O. Rice (1907–1986).

In probability theory and statistics, the chi distribution is a continuous probability distribution over the non-negative real line. It is the distribution of the positive square root of a sum of squared independent Gaussian random variables. Equivalently, it is the distribution of the Euclidean distance between a multivariate Gaussian random variable and the origin. It is thus related to the chi-squared distribution by describing the distribution of the positive square roots of a variable obeying a chi-squared distribution.

The folded normal distribution is a probability distribution related to the normal distribution. Given a normally distributed random variable X with mean μ and variance σ2, the random variable Y = |X| has a folded normal distribution. Such a case may be encountered if only the magnitude of some variable is recorded, but not its sign. The distribution is called "folded" because probability mass to the left of x = 0 is folded over by taking the absolute value. In the physics of heat conduction, the folded normal distribution is a fundamental solution of the heat equation on the half space; it corresponds to having a perfect insulator on a hyperplane through the origin.
Bayesian linear regression is a type of conditional modeling in which the mean of one variable is described by a linear combination of other variables, with the goal of obtaining the posterior probability of the regression coefficients and ultimately allowing the out-of-sample prediction of the regressandconditional on observed values of the regressors. The simplest and most widely used version of this model is the normal linear model, in which given is distributed Gaussian. In this model, and under a particular choice of prior probabilities for the parameters—so-called conjugate priors—the posterior can be found analytically. With more arbitrarily chosen priors, the posteriors generally have to be approximated.
In statistics, the multivariate t-distribution is a multivariate probability distribution. It is a generalization to random vectors of the Student's t-distribution, which is a distribution applicable to univariate random variables. While the case of a random matrix could be treated within this structure, the matrix t-distribution is distinct and makes particular use of the matrix structure.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
The Birnbaum–Saunders distribution, also known as the fatigue life distribution, is a probability distribution used extensively in reliability applications to model failure times. There are several alternative formulations of this distribution in the literature. It is named after Z. W. Birnbaum and S. C. Saunders.
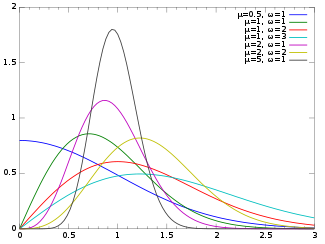
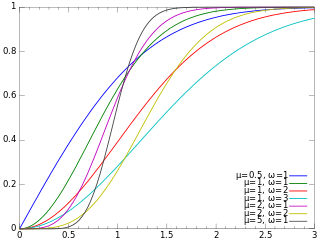
The term generalized logistic distribution is used as the name for several different families of probability distributions. For example, Johnson et al. list four forms, which are listed below.
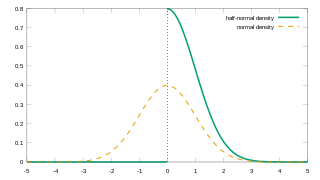
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.

In probability theory and statistics, the skew normal distribution is a continuous probability distribution that generalises the normal distribution to allow for non-zero skewness.

In probability theory and statistics, the generalized chi-squared distribution is the distribution of a quadratic form of a multinormal variable, or a linear combination of different normal variables and squares of normal variables. Equivalently, it is also a linear sum of independent noncentral chi-square variables and a normal variable. There are several other such generalizations for which the same term is sometimes used; some of them are special cases of the family discussed here, for example the gamma distribution.
In statistics and probability theory, the nonparametric skew is a statistic occasionally used with random variables that take real values. It is a measure of the skewness of a random variable's distribution—that is, the distribution's tendency to "lean" to one side or the other of the mean. Its calculation does not require any knowledge of the form of the underlying distribution—hence the name nonparametric. It has some desirable properties: it is zero for any symmetric distribution; it is unaffected by a scale shift; and it reveals either left- or right-skewness equally well. In some statistical samples it has been shown to be less powerful than the usual measures of skewness in detecting departures of the population from normality.
In statistics, the matrix t-distribution is the generalization of the multivariate t-distribution from vectors to matrices. The matrix t-distribution shares the same relationship with the multivariate t-distribution that the matrix normal distribution shares with the multivariate normal distribution. For example, the matrix t-distribution is the compound distribution that results from sampling from a matrix normal distribution having sampled the covariance matrix of the matrix normal from an inverse Wishart distribution.

In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data.