Generalizations
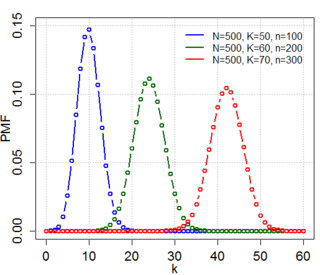
A natural generalization of the problem is to consider n non-necessarily fair dice, with p the probability that each die will select the 6 face when thrown (notice that actually the number of faces of the dice and which face should be selected are irrelevant). If r is the total number of dice selecting the 6 face, then  is the probability of having at least k correct selections when throwing exactly n dice. Then the original Newton–Pepys problem can be generalized as follows:
is the probability of having at least k correct selections when throwing exactly n dice. Then the original Newton–Pepys problem can be generalized as follows:
Let  be natural positive numbers s.t.
be natural positive numbers s.t.  . Is then
. Is then  not smaller than
not smaller than  for all n, p, k?
for all n, p, k?
Notice that, with this notation, the original Newton–Pepys problem reads as: is  ?
?
As noticed in Rubin and Evans (1961), there are no uniform answers to the generalized Newton–Pepys problem since answers depend on k, n and p. There are nonetheless some variations of the previous questions that admit uniform answers:
(from Chaundy and Bullard (1960)): [4]
If  are positive natural numbers, and
are positive natural numbers, and  , then
, then  .
.
If  are positive natural numbers, and
are positive natural numbers, and  , then
, then  .
.
(from Varagnolo, Pillonetto and Schenato (2013)): [5]
If  are positive natural numbers, and
are positive natural numbers, and  then
then  .
.