
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is linear with respect to the height of the tree.
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.
In computer science, a red–black tree is a specialised binary search tree data structure noted for fast storage and retrieval of ordered information, and a guarantee that operations will complete within a known time. Compared to other self-balancing binary search trees, the nodes in a red-black tree hold an extra bit called "color" representing "red" and "black" which is used when re-organising the tree to ensure that it is always approximately balanced.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.

A quadtree is a tree data structure in which each internal node has exactly four children. Quadtrees are the two-dimensional analog of octrees and are most often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions. The data associated with a leaf cell varies by application, but the leaf cell represents a "unit of interesting spatial information".

R-trees are tree data structures used for spatial access methods, i.e., for indexing multi-dimensional information such as geographical coordinates, rectangles or polygons. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both theoretical and applied contexts. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries such as "Find all museums within 2 km of my current location", "retrieve all road segments within 2 km of my location" or "find the nearest gas station". The R-tree can also accelerate nearest neighbor search for various distance metrics, including great-circle distance.
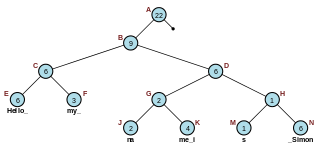
In computer programming, a rope, or cord, is a data structure composed of smaller strings that is used to efficiently store and manipulate a very long string. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done efficiently.
In computer science, an interval tree is a tree data structure to hold intervals. Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene. A similar data structure is the segment tree.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. K-dimensional is that which concerns exactly k orthogonal axes or a space of any number of dimensions. k-d trees are a useful data structure for several applications, such as:
Nearest neighbor search (NNS), as a form of proximity search, is the optimization problem of finding the point in a given set that is closest to a given point. Closeness is typically expressed in terms of a dissimilarity function: the less similar the objects, the larger the function values.
Hilbert R-tree, an R-tree variant, is an index for multidimensional objects such as lines, regions, 3-D objects, or high-dimensional feature-based parametric objects. It can be thought of as an extension to B+-tree for multidimensional objects.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.
In computer science, the Bx tree is a query that is used to update efficient B+ tree-based index structures for moving objects.
In computer science, M-trees are tree data structures that are similar to R-trees and B-trees. It is constructed using a metric and relies on the triangle inequality for efficient range and k-nearest neighbor (k-NN) queries. While M-trees can perform well in many conditions, the tree can also have large overlap and there is no clear strategy on how to best avoid overlap. In addition, it can only be used for distance functions that satisfy the triangle inequality, while many advanced dissimilarity functions used in information retrieval do not satisfy this.

A top tree is a data structure based on a binary tree for unrooted dynamic trees that is used mainly for various path-related operations. It allows simple divide-and-conquer algorithms. It has since been augmented to maintain dynamically various properties of a tree such as diameter, center and median.
In computer science, a fractal tree index is a tree data structure that keeps data sorted and allows searches and sequential access in the same time as a B-tree but with insertions and deletions that are asymptotically faster than a B-tree. Like a B-tree, a fractal tree index is a generalization of a binary search tree in that a node can have more than two children. Furthermore, unlike a B-tree, a fractal tree index has buffers at each node, which allow insertions, deletions and other changes to be stored in intermediate locations. The goal of the buffers is to schedule disk writes so that each write performs a large amount of useful work, thereby avoiding the worst-case performance of B-trees, in which each disk write may change a small amount of data on disk. Like a B-tree, fractal tree indexes are optimized for systems that read and write large blocks of data. The fractal tree index has been commercialized in databases by Tokutek. Originally, it was implemented as a cache-oblivious lookahead array, but the current implementation is an extension of the Bε tree. The Bε is related to the Buffered Repository Tree. The Buffered Repository Tree has degree 2, whereas the Bε tree has degree Bε. The fractal tree index has also been used in a prototype filesystem. An open source implementation of the fractal tree index is available, which demonstrates the implementation details outlined below.
In computer science, a K-D-B-tree (k-dimensional B-tree) is a tree data structure for subdividing a k-dimensional search space. The aim of the K-D-B-tree is to provide the search efficiency of a balanced k-d tree, while providing the block-oriented storage of a B-tree for optimizing external memory accesses.
The PH-tree is a tree data structure used for spatial indexing of multi-dimensional data (keys) such as geographical coordinates, points, feature vectors, rectangles or bounding boxes. The PH-tree is space partitioning index with a structure similar to that of a quadtree or octree. However, unlike quadtrees, it uses a splitting policy based on tries and similar to Crit bit trees that is based on the bit-representation of the keys. The bit-based splitting policy, when combined with the use of different internal representations for nodes, provides scalability with high-dimensional data. The bit-representation splitting policy also imposes a maximum depth, thus avoiding degenerated trees and the need for rebalancing.
The compressed cover tree is a type of data structure in computer science that is specifically designed to facilitate the speed-up of a k-nearest neighbors algorithm in finite metric spaces. Compressed cover tree is a simplified version of explicit representation of cover tree that was motivated by past issues in proofs of time complexity results of cover tree. The compressed cover tree was specifically designed to achieve claimed time complexities of cover tree in a mathematically rigorous way.
 R-Tree with Guttman quadratic split. [2]
R-Tree with Guttman quadratic split. [2] R-Tree with Ang-Tan linear split. [3]
R-Tree with Ang-Tan linear split. [3]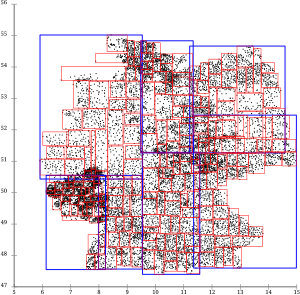 R*-tree topological split. [1]
R*-tree topological split. [1]







