Related Research Articles

Advanced Micro Devices, Inc. (AMD) is an American multinational corporation and semiconductor company based in Santa Clara, California, that develops computer processors and related technologies for business and consumer markets.

The K6 microprocessor was launched by AMD in 1997. The main advantage of this particular microprocessor is that it was designed to fit into existing desktop designs for Pentium-branded CPUs. It was marketed as a product that could perform as well as its Intel Pentium II equivalent but at a significantly lower price. The K6 had a considerable impact on the PC market and presented Intel with serious competition.
The Pentium is a x86 microprocessor introduced by Intel on March 22, 1993. It is the first CPU using the Pentium brand. Considered the fifth generation in the 8086 compatible line of processors, its implementation and microarchitecture was internally called P5.

x86 is a family of complex instruction set computer (CISC) instruction set architectures initially developed by Intel based on the 8086 microprocessor and its 8088 variant. The 8086 was introduced in 1978 as a fully 16-bit extension of 8-bit Intel's 8080 microprocessor, with memory segmentation as a solution for addressing more memory than can be covered by a plain 16-bit address. The term "x86" came into being because the names of several successors to Intel's 8086 processor end in "86", including the 80186, 80286, 80386 and 80486. Colloquially, their names were "186", "286", "386" and "486".

A graphics card is a computer expansion card that generates a feed of graphics output to a display device such as a monitor. Graphics cards are sometimes called discrete or dedicated graphics cards to emphasize their distinction to an integrated graphics processor on the motherboard or the central processing unit (CPU). A graphics processing unit (GPU) that performs the necessary computations is the main component in a graphics card, but the acronym "GPU" is sometimes also used to erroneously refer to the graphics card as a whole.

x86-64 is a 64-bit version of the x86 instruction set, first announced in 1999. It introduced two new modes of operation, 64-bit mode and compatibility mode, along with a new 4-level paging mode.

A graphics processing unit (GPU) is a specialized electronic circuit initially designed to accelerate computer graphics and image processing. After their initial design, GPUs were found to be useful for non-graphic calculations involving embarrassingly parallel problems due to their parallel structure. Other non-graphical uses include the training of neural networks and cryptocurrency mining.
A processor register is a quickly accessible location available to a computer's processor. Registers usually consist of a small amount of fast storage, although some registers have specific hardware functions, and may be read-only or write-only. In computer architecture, registers are typically addressed by mechanisms other than main memory, but may in some cases be assigned a memory address e.g. DEC PDP-10, ICT 1900.

The K5 is AMD's first x86 processor to be developed entirely in-house. Introduced in March 1996, its primary competition was Intel's Pentium microprocessor. The K5 was an ambitious design, closer to a Pentium Pro than a Pentium regarding technical solutions and internal architecture. However, the final product was closer to the Pentium regarding performance, although faster clock-for-clock compared to the Pentium.
x86 virtualization is the use of hardware-assisted virtualization capabilities on an x86/x86-64 CPU.
The thermal design power (TDP), sometimes called thermal design point, is the maximum amount of heat generated by a computer chip or component that the cooling system in a computer is designed to dissipate under any workload.

The AMD Am29000, commonly shortened to 29k, is a family of 32-bit RISC microprocessors and microcontrollers developed and fabricated by Advanced Micro Devices (AMD). Based on the seminal Berkeley RISC, the 29k added a number of significant improvements. They were, for a time, the most popular RISC chips on the market, widely used in laser printers from a variety of manufacturers.
In the fields of digital electronics and computer hardware, multi-channel memory architecture is a technology that increases the data transfer rate between the DRAM memory and the memory controller by adding more channels of communication between them. Theoretically, this multiplies the data rate by exactly the number of channels present. Dual-channel memory employs two channels. The technique goes back as far as the 1960s having been used in IBM System/360 Model 91 and in CDC 6600.
x87 is a floating-point-related subset of the x86 architecture instruction set. It originated as an extension of the 8086 instruction set in the form of optional floating-point coprocessors that work in tandem with corresponding x86 CPUs. These microchips have names ending in "87". This is also known as the NPX. Like other extensions to the basic instruction set, x87 instructions are not strictly needed to construct working programs, but provide hardware and microcode implementations of common numerical tasks, allowing these tasks to be performed much faster than corresponding machine code routines can. The x87 instruction set includes instructions for basic floating-point operations such as addition, subtraction and comparison, but also for more complex numerical operations, such as the computation of the tangent function and its inverse, for example.
The transistor count is the number of transistors in an electronic device. It is the most common measure of integrated circuit complexity. The rate at which MOS transistor counts have increased generally follows Moore's law, which observes that transistor count doubles approximately every two years. However, being directly proportional to the area of a die, transistor count does not represent how advanced the corresponding manufacturing technology is. A better indication of this is transistor density which is the ratio of a semiconductor's transistor count to its die area.

Dell Precision is a series of computer workstations for computer-aided design/architecture/computer graphics professionals, or as small-scale business servers. They are available in both desktop (tower) and mobile (laptop) form. Dell touts their Precision Mobile Workstations are "optimized for performance, reliability and user experience."
Bit manipulation instructions sets are extensions to the x86 instruction set architecture for microprocessors from Intel and AMD. The purpose of these instruction sets is to improve the speed of bit manipulation. All the instructions in these sets are non-SIMD and operate only on general-purpose registers.
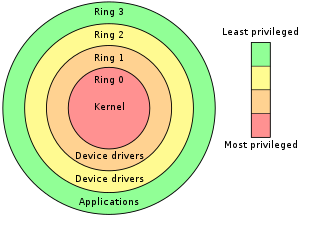
The Intel Management Engine (ME), also known as the Intel Manageability Engine, is an autonomous subsystem that has been incorporated in virtually all of Intel's processor chipsets since 2008. It is located in the Platform Controller Hub of modern Intel motherboards.

Hardware-based encryption is the use of computer hardware to assist software, or sometimes replace software, in the process of data encryption. Typically, this is implemented as part of the processor's instruction set. For example, the AES encryption algorithm can be implemented using the AES instruction set on the ubiquitous x86 architecture. Such instructions also exist on the ARM architecture. However, more unusual systems exist where the cryptography module is separate from the central processor, instead being implemented as a coprocessor, in particular a secure cryptoprocessor or cryptographic accelerator, of which an example is the IBM 4758, or its successor, the IBM 4764. Hardware implementations can be faster and less prone to exploitation than traditional software implementations, and furthermore can be protected against tampering.
References
- ↑ "Products We Design". amd.com. Retrieved 19 January 2014.
- 1 2 "wp-content/uploads/2013/07/AMD-Steamroller-vs-Bulldozer". cdn3.wccftech.com. Archived from the original on 17 October 2013. Retrieved 19 January 2014.
- ↑ "Cyrix 5x86 ("M1sc")". pcguide.com. Retrieved 19 January 2014.
- 1 2 "Computer Science 246: Computer Architecture" (PDF). Harvard University. Archived from the original (PDF) on 24 December 2013. Retrieved 23 December 2013.
P6 pipeline
- ↑ Intel Itanium 2 Processor Hardware Developer's Manual. p. 14. http://www.intel.com/design/itanium2/manuals/25110901.pdf (2002) Retrieved 28 November 2011
- ↑ "Multi Core Processor SPARC64 Series : Fujitsu Global". fujitsu.com. Retrieved 19 January 2014.
{kind=link}
{kind=link}