
In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

The Pareto distribution, named after the Italian civil engineer, economist, and sociologist Vilfredo Pareto, is a power-law probability distribution that is used in description of social, quality control, scientific, geophysical, actuarial, and many other types of observable phenomena; the principle originally applied to describing the distribution of wealth in a society, fitting the trend that a large portion of wealth is held by a small fraction of the population. The Pareto principle or "80-20 rule" stating that 80% of outcomes are due to 20% of causes was named in honour of Pareto, but the concepts are distinct, and only Pareto distributions with shape value of log45 ≈ 1.16 precisely reflect it. Empirical observation has shown that this 80-20 distribution fits a wide range of cases, including natural phenomena and human activities.
In mathematical physics, n-dimensional de Sitter space is a maximally symmetric Lorentzian manifold with constant positive scalar curvature. It is the Lorentzian analogue of an n-sphere.
In mathematics and its applications, a Sturm–Liouville problem is a second-order linear ordinary differential equation of the form for given functions , and , together with some boundary conditions at extreme values of . The goals of a given Sturm–Liouville problem are:

In probability theory and statistics, the Laplace distribution is a continuous probability distribution named after Pierre-Simon Laplace. It is also sometimes called the double exponential distribution, because it can be thought of as two exponential distributions spliced together along the abscissa, although the term is also sometimes used to refer to the Gumbel distribution. The difference between two independent identically distributed exponential random variables is governed by a Laplace distribution, as is a Brownian motion evaluated at an exponentially distributed random time. Increments of Laplace motion or a variance gamma process evaluated over the time scale also have a Laplace distribution.

In probability theory, a distribution is said to be stable if a linear combination of two independent random variables with this distribution has the same distribution, up to location and scale parameters. A random variable is said to be stable if its distribution is stable. The stable distribution family is also sometimes referred to as the Lévy alpha-stable distribution, after Paul Lévy, the first mathematician to have studied it.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.

The Pearson distribution is a family of continuous probability distributions. It was first published by Karl Pearson in 1895 and subsequently extended by him in 1901 and 1916 in a series of articles on biostatistics.
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.
In mathematics, a logarithm of a matrix is another matrix such that the matrix exponential of the latter matrix equals the original matrix. It is thus a generalization of the scalar logarithm and in some sense an inverse function of the matrix exponential. Not all matrices have a logarithm and those matrices that do have a logarithm may have more than one logarithm. The study of logarithms of matrices leads to Lie theory since when a matrix has a logarithm then it is in an element of a Lie group and the logarithm is the corresponding element of the vector space of the Lie algebra.
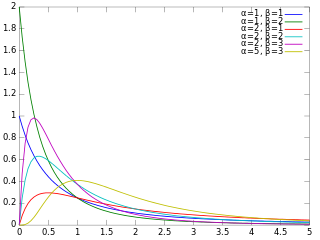
In probability theory and statistics, the beta prime distribution is an absolutely continuous probability distribution. If has a beta distribution, then the odds has a beta prime distribution.
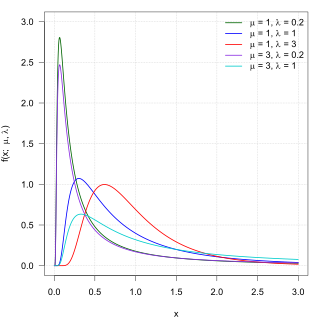
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.

In probability theory, statistics and econometrics, the Burr Type XII distribution or simply the Burr distribution is a continuous probability distribution for a non-negative random variable. It is also known as the Singh–Maddala distribution and is one of a number of different distributions sometimes called the "generalized log-logistic distribution".

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate and independently of the time since the last event. It can also be used for the number of events in other types of intervals than time, and in dimension greater than 1.
A geometric stable distribution or geo-stable distribution is a type of leptokurtic probability distribution. Geometric stable distributions were introduced in Klebanov, L. B., Maniya, G. M., and Melamed, I. A. (1985). A problem of Zolotarev and analogs of infinitely divisible and stable distributions in a scheme for summing a random number of random variables. These distributions are analogues for stable distributions for the case when the number of summands is random, independent of the distribution of summand, and having geometric distribution. The geometric stable distribution may be symmetric or asymmetric. A symmetric geometric stable distribution is also referred to as a Linnik distribution. The Laplace distribution and asymmetric Laplace distribution are special cases of the geometric stable distribution. The Mittag-Leffler distribution is also a special case of a geometric stable distribution.

The Lomax distribution, conditionally also called the Pareto Type II distribution, is a heavy-tail probability distribution used in business, economics, actuarial science, queueing theory and Internet traffic modeling. It is named after K. S. Lomax. It is essentially a Pareto distribution that has been shifted so that its support begins at zero.
In probability theory and statistics, the noncentral beta distribution is a continuous probability distribution that is a noncentral generalization of the (central) beta distribution.

The Kaniadakis Logistic distribution is a generalized version of the Logistic distribution associated with the Kaniadakis statistics. It is one example of a Kaniadakis distribution. The κ-Logistic probability distribution describes the population kinetics behavior of bosonic or fermionic character.










