
The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution, Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.
In statistics, a location parameter of a probability distribution is a scalar- or vector-valued parameter , which determines the "location" or shift of the distribution. In the literature of location parameter estimation, the probability distributions with such parameter are found to be formally defined in one of the following equivalent ways:
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of a probability distribution by maximizing a likelihood function, so that under the assumed statistical model the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the form
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. The terms "distribution" and "family" are often used loosely: properly, an exponential family is a set of distributions, where the specific distribution varies with the parameter; however, a parametric family of distributions is often referred to as "a distribution", and the set of all exponential families is sometimes loosely referred to as "the" exponential family. They are distinct because they posses a variety of desirable properties. Most importantly the existence of a sufficient statistic.

Directional statistics is the subdiscipline of statistics that deals with directions, axes or rotations in Rn. More generally, directional statistics deals with observations on compact Riemannian manifolds.
In probability and statistics, a circular distribution or polar distribution is a probability distribution of a random variable whose values are angles, usually taken to be in the range [0, 2π). A circular distribution is often a continuous probability distribution, and hence has a probability density, but such distributions can also be discrete, in which case they are called circular lattice distributions. Circular distributions can be used even when the variables concerned are not explicitly angles: the main consideration is that there is not usually any real distinction between events occurring at the lower or upper end of the range, and the division of the range could notionally be made at any point.
In Bayesian statistics, a maximum a posteriori probability (MAP) estimate is an estimate of an unknown quantity, that equals the mode of the posterior distribution. The MAP can be used to obtain a point estimate of an unobserved quantity on the basis of empirical data. It is closely related to the method of maximum likelihood (ML) estimation, but employs an augmented optimization objective which incorporates a prior distribution over the quantity one wants to estimate. MAP estimation can therefore be seen as a regularization of maximum likelihood estimation.

In probability theory and directional statistics, the von Mises distribution is a continuous probability distribution on the circle. It is a close approximation to the wrapped normal distribution, which is the circular analogue of the normal distribution. A freely diffusing angle on a circle is a wrapped normally distributed random variable with an unwrapped variance that grows linearly in time. On the other hand, the von Mises distribution is the stationary distribution of a drift and diffusion process on the circle in a harmonic potential, i.e. with a preferred orientation. The von Mises distribution is the maximum entropy distribution for circular data when the real and imaginary parts of the first circular moment are specified. The von Mises distribution is a special case of the von Mises–Fisher distribution on the N-dimensional sphere.

In probability theory, the Rice distribution or Rician distribution is the probability distribution of the magnitude of a circularly-symmetric bivariate normal random variable, possibly with non-zero mean (noncentral). It was named after Stephen O. Rice.
In Bayesian probability, the Jeffreys prior, named after Sir Harold Jeffreys, is a non-informative (objective) prior distribution for a parameter space; its density function is proportional to the square root of the determinant of the Fisher information matrix:

In probability theory and statistics, the characteristic function of any real-valued random variable completely defines its probability distribution. If a random variable admits a probability density function, then the characteristic function is the Fourier transform of the probability density function. Thus it provides an alternative route to analytical results compared with working directly with probability density functions or cumulative distribution functions. There are particularly simple results for the characteristic functions of distributions defined by the weighted sums of random variables.
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function. Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.

The shifted log-logistic distribution is a probability distribution also known as the generalized log-logistic or the three-parameter log-logistic distribution. It has also been called the generalized logistic distribution, but this conflicts with other uses of the term: see generalized logistic distribution.
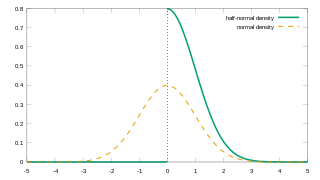
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.

In probability theory and directional statistics, a wrapped normal distribution is a wrapped probability distribution that results from the "wrapping" of the normal distribution around the unit circle. It finds application in the theory of Brownian motion and is a solution to the heat equation for periodic boundary conditions. It is closely approximated by the von Mises distribution, which, due to its mathematical simplicity and tractability, is the most commonly used distribution in directional statistics.
In statistics, identifiability is a property which a model must satisfy in order for precise inference to be possible. A model is identifiable if it is theoretically possible to learn the true values of this model's underlying parameters after obtaining an infinite number of observations from it. Mathematically, this is equivalent to saying that different values of the parameters must generate different probability distributions of the observable variables. Usually the model is identifiable only under certain technical restrictions, in which case the set of these requirements is called the identification conditions.

In probability theory and directional statistics, a wrapped Cauchy distribution is a wrapped probability distribution that results from the "wrapping" of the Cauchy distribution around the unit circle. The Cauchy distribution is sometimes known as a Lorentzian distribution, and the wrapped Cauchy distribution may sometimes be referred to as a wrapped Lorentzian distribution.

In probability theory, a log-Cauchy distribution is a probability distribution of a random variable whose logarithm is distributed in accordance with a Cauchy distribution. If X is a random variable with a Cauchy distribution, then Y = exp(X) has a log-Cauchy distribution; likewise, if Y has a log-Cauchy distribution, then X = log(Y) has a Cauchy distribution.




