A binary symmetric channel is a common communications channel model used in coding theory and information theory. In this model, a transmitter wishes to send a bit, and the receiver will receive a bit. The bit will be "flipped" with a "crossover probability" of p, and otherwise is received correctly. This model can be applied to varied communication channels such as telephone lines or disk drive storage.
In Vapnik–Chervonenkis theory, the Vapnik–Chervonenkis (VC) dimension is a measure of the size of a class of sets. The notion can be extended to classes of binary functions. It is defined as the cardinality of the largest set of points that the algorithm can shatter, which means the algorithm can always learn a perfect classifier for any labeling of at least one configuration of those data points. It was originally defined by Vladimir Vapnik and Alexey Chervonenkis.
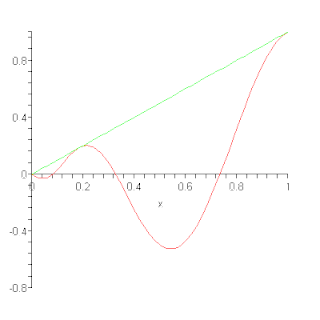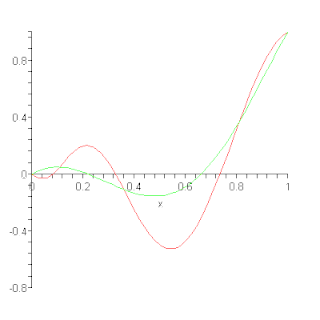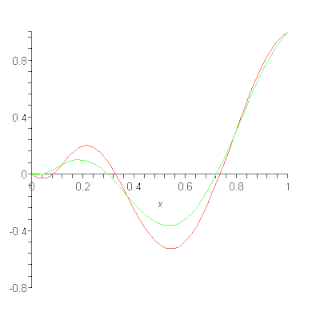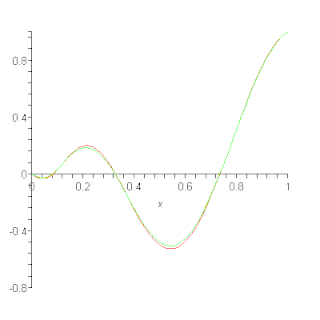
In the mathematical field of numerical analysis, a Bernstein polynomial is a polynomial expressed as a linear combination of Bernstein basis polynomials. The idea is named after mathematician Sergei Natanovich Bernstein.
In computer science, computational learning theory is a subfield of artificial intelligence devoted to studying the design and analysis of machine learning algorithms.
A prior probability distribution of an uncertain quantity, often simply called the prior, is its assumed probability distribution before some evidence is taken into account. For example, the prior could be the probability distribution representing the relative proportions of voters who will vote for a particular politician in a future election. The unknown quantity may be a parameter of the model or a latent variable rather than an observable variable.
In mathematics, nonstandard calculus is the modern application of infinitesimals, in the sense of nonstandard analysis, to infinitesimal calculus. It provides a rigorous justification for some arguments in calculus that were previously considered merely heuristic.
In probability theory, a Chernoff bound is an exponentially decreasing upper bound on the tail of a random variable based on its moment generating function. The minimum of all such exponential bounds forms the Chernoff or Chernoff-Cramér bound, which may decay faster than exponential. It is especially useful for sums of independent random variables, such as sums of Bernoulli random variables.
For supervised learning applications in machine learning and statistical learning theory, generalization error is a measure of how accurately an algorithm is able to predict outcome values for previously unseen data. Because learning algorithms are evaluated on finite samples, the evaluation of a learning algorithm may be sensitive to sampling error. As a result, measurements of prediction error on the current data may not provide much information about predictive ability on new data. Generalization error can be minimized by avoiding overfitting in the learning algorithm. The performance of a machine learning algorithm is visualized by plots that show values of estimates of the generalization error through the learning process, which are called learning curves.
The term evolvability is used for a recent framework of computational learning introduced by Leslie Valiant in his paper of the same name and described below. The aim of this theory is to model biological evolution and categorize which types of mechanisms are evolvable. Evolution is an extension of PAC learning and learning from statistical queries.
In game theory, an epsilon-equilibrium, or near-Nash equilibrium, is a strategy profile that approximately satisfies the condition of Nash equilibrium. In a Nash equilibrium, no player has an incentive to change his behavior. In an approximate Nash equilibrium, this requirement is weakened to allow the possibility that a player may have a small incentive to do something different. This may still be considered an adequate solution concept, assuming for example status quo bias. This solution concept may be preferred to Nash equilibrium due to being easier to compute, or alternatively due to the possibility that in games of more than 2 players, the probabilities involved in an exact Nash equilibrium need not be rational numbers.
In theoretical computer science, a small-bias sample space is a probability distribution that fools parity functions. In other words, no parity function can distinguish between a small-bias sample space and the uniform distribution with high probability, and hence, small-bias sample spaces naturally give rise to pseudorandom generators for parity functions.
A randomness extractor, often simply called an "extractor", is a function, which being applied to output from a weak entropy source, together with a short, uniformly random seed, generates a highly random output that appears independent from the source and uniformly distributed. Examples of weakly random sources include radioactive decay or thermal noise; the only restriction on possible sources is that there is no way they can be fully controlled, calculated or predicted, and that a lower bound on their entropy rate can be established. For a given source, a randomness extractor can even be considered to be a true random number generator (TRNG); but there is no single extractor that has been proven to produce truly random output from any type of weakly random source.
A locally testable code is a type of error-correcting code for which it can be determined if a string is a word in that code by looking at a small number of bits of the string. In some situations, it is useful to know if the data is corrupted without decoding all of it so that appropriate action can be taken in response. For example, in communication, if the receiver encounters a corrupted code, it can request the data be re-sent, which could increase the accuracy of said data. Similarly, in data storage, these codes can allow for damaged data to be recovered and rewritten properly.
The exponential mechanism is a technique for designing differentially private algorithms. It was developed by Frank McSherry and Kunal Talwar in 2007. Their work was recognized as a co-winner of the 2009 PET Award for Outstanding Research in Privacy Enhancing Technologies.
A locally decodable code (LDC) is an error-correcting code that allows a single bit of the original message to be decoded with high probability by only examining a small number of bits of a possibly corrupted codeword. This property could be useful, say, in a context where information is being transmitted over a noisy channel, and only a small subset of the data is required at a particular time and there is no need to decode the entire message at once. Note that locally decodable codes are not a subset of locally testable codes, though there is some overlap between the two.
The sample complexity of a machine learning algorithm represents the number of training-samples that it needs in order to successfully learn a target function.
In computational learning theory, Occam learning is a model of algorithmic learning where the objective of the learner is to output a succinct representation of received training data. This is closely related to probably approximately correct (PAC) learning, where the learner is evaluated on its predictive power of a test set.
The distributional learning theory or learning of probability distribution is a framework in computational learning theory. It has been proposed from Michael Kearns, Yishay Mansour, Dana Ron, Ronitt Rubinfeld, Robert Schapire and Linda Sellie in 1994 and it was inspired from the PAC-framework introduced by Leslie Valiant.
In PAC learning, error tolerance refers to the ability of an algorithm to learn when the examples received have been corrupted in some way. In fact, this is a very common and important issue since in many applications it is not possible to access noise-free data. Noise can interfere with the learning process at different levels: the algorithm may receive data that have been occasionally mislabeled, or the inputs may have some false information, or the classification of the examples may have been maliciously adulterated.
The multiplicative weights update method is an algorithmic technique most commonly used for decision making and prediction, and also widely deployed in game theory and algorithm design. The simplest use case is the problem of prediction from expert advice, in which a decision maker needs to iteratively decide on an expert whose advice to follow. The method assigns initial weights to the experts, and updates these weights multiplicatively and iteratively according to the feedback of how well an expert performed: reducing it in case of poor performance, and increasing it otherwise. It was discovered repeatedly in very diverse fields such as machine learning, optimization, theoretical computer science, and game theory.



















