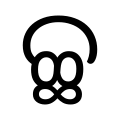
Ca is the sixth consonant of Indic abugidas. In modern Indic scripts, ca is derived from the early "Ashoka" Brahmi letter , which is probably derived from the North Semitic letter tsade (reflected in the Aramaic , "ts"), with an inversion seen in several other derivatives,[1] after having gone through the Gupta letter .
Aryabhata used Devanagari letters for numbers, very similar to the Greek numerals, even after the invention of Indian numerals. The values of the different forms of च are:[2]
There are three different general early historic scripts - Brahmi and its variants, Kharoṣṭhī, and Tocharian, the so-called slanting Brahmi. Ca as found in standard Brahmi, was a simple geometric shape, with variations toward more flowing forms by the Gupta . The Tocharian Ca did not have an alternate Fremdzeichen form. The third form of ca, in Kharoshthi () was probably derived from Aramaic separately from the Brahmi letter.
Brahmi Ca
The Brahmi letter , Ca, is probably derived from the Aramaic Tsade, and is thus related to the Greek San. Several identifiable styles of writing the Brahmi Ca can be found, most associated with a specific set of inscriptions from an artifact or diverse records from an historic period.[3] As the earliest and most geometric style of Brahmi, the letters found on the Edicts of Ashoka and other records from around that time are normally the reference form for Brahmi letters, with vowel marks not attested until later forms of Brahmi back-formed to match the geometric writing style.
Ca (च) is the sixth consonant of the Devanagariabugida. It ultimately arose from the Brahmi letter , after having gone through the Gupta letter . In Marathi, च is sometimes pronounced as [t͡sə] or [t͡s] in addition to [t͡ʃə] or [t͡ʃ], while in Nepali, the [t͡s] pronunciation is standard, and deviates with regard to dialect. Letters that derive from it are the Gujarati letter ચ and the Modi letter 𑘓.
Devanagari-using Languages
Like all Indic scripts, Devanagari uses vowel marks attached to the base consonant to override the inherent /ə/ vowel:
Devanagari च with vowel marks
Ca
Cā
Ci
Cī
Cu
Cū
Cr
Cr̄
Cl
Cl̄
Ce
Cai
Co
Cau
C
च
चा
चि
ची
चु
चू
चृ
चॄ
चॢ
चॣ
चे
चै
चो
चौ
च्
Conjuncts with च
Half form of Ca.
Devanagari exhibits conjunct ligatures, as is common in Indic scripts. In modern Devanagari texts, most conjuncts are formed by reducing the letter shape to fit tightly to the following letter, usually by dropping a character's vertical stem, sometimes referred to as a "half form". Some conjunct clusters are always represented by a true ligature, instead of a shape that can be broken into constituent independent letters. Vertically stacked conjuncts are ubiquitous in older texts, while only a few are still used routinely in modern Devanagari texts. The use of ligatures and vertical conjuncts may vary across languages using the Devanagari script, with Marathi in particular preferring the use of half forms where texts in other languages would show ligatures and vertical stacks.[4]
Ligature conjuncts of च
True ligatures are quite rare in Indic scripts. The most common ligated conjuncts in Devanagari are in the form of a slight mutation to fit in context or as a consistent variant form appended to the adjacent characters. Those variants include Na and the Repha and Rakar forms of Ra. Nepali and Marathi texts use the "eyelash" Ra half form for an initial "R" instead of repha.
Repha र্ (r) + च (ca) gives the ligature rca: note
Eyelash र্ (r) + च (ca) gives the ligature rca:
च্ (c) + rakar र (ra) gives the ligature cra:
च্ (c) + न (na) gives the ligature cna:
Stacked conjuncts of च
Vertically stacked ligatures are the most common conjunct forms found in Devanagari text. Although the constituent characters may need to be stretched and moved slightly in order to stack neatly, stacked conjuncts can be broken down into recognizable base letters, or a letter and an otherwise standard ligature.
ब্ (b) + च (ca) gives the ligature bca:
भ্ (bʰ) + च (ca) gives the ligature bʰca:
च্ (c) + ब (ba) gives the ligature cba:
च্ (c) + च (ca) gives the ligature cca:
च্ (c) + ड (ḍa) gives the ligature cḍa:
छ্ (cʰ) + च (ca) gives the ligature cʰca:
च্ (c) + ज (ja) gives the ligature cja:
च্ (c) + ज্ (j) + ञ (ña) gives the ligature cjña:
च্ (c) + क (ka) gives the ligature cka:
च্ (c) + ल (la) gives the ligature cla:
च্ (c) + ङ (ŋa) gives the ligature cŋa:
च্ (c) + ञ (ña) gives the ligature cña:
च্ (c) + व (va) gives the ligature cva:
द্ (d) + च (ca) gives the ligature dca:
ड্ (ḍ) + च (ca) gives the ligature ḍca:
ढ্ (ḍʱ) + च (ca) gives the ligature ḍʱca:
ध্ (dʱ) + च (ca) gives the ligature dʱca:
घ্ (ɡʱ) + च (ca) gives the ligature ɡʱca:
ह্ (h) + च (ca) gives the ligature hca:
ज্ (j) + च (ca) gives the ligature jca:
झ্ (jʰ) + च (ca) gives the ligature jʰca:
क্ (k) + च (ca) gives the ligature kca:
ख্ (kʰ) + च (ca) gives the ligature kʰca:
ल্ (l) + च (ca) gives the ligature lca:
ळ্ (ḷ) + च (ca) gives the ligature ḷca:
म্ (m) + च (ca) gives the ligature mca:
न্ (n) + च (ca) gives the ligature nca:
ङ্ (ŋ) + च (ca) gives the ligature ŋca:
ञ্ (ñ) + च (ca) gives the ligature ñca:
प্ (p) + च (ca) gives the ligature pca:
फ্ (pʰ) + च (ca) gives the ligature pʰca:
स্ (s) + च (ca) gives the ligature sca:
श্ (ʃ) + च (ca) gives the ligature ʃca:
ष্ (ṣ) + च (ca) gives the ligature ṣca:
त্ (t) + च (ca) gives the ligature tca:
थ্ (tʰ) + च (ca) gives the ligature tʰca:
ट্ (ṭ) + च (ca) gives the ligature ṭca:
ठ্ (ṭʰ) + च (ca) gives the ligature ṭʰca:
व্ (v) + च (ca) gives the ligature vca:
य্ (y) + च (ca) gives the ligature yca:
Bengali script
The Bengali script চ is derived from the Siddhaṃ, and is marked by a similar horizontal head line, but less geometric shape, than its Devanagari counterpart, च. The inherent vowel of Bengali consonant letters is /ɔ/, so the bare letter চ will sometimes be transliterated as "co" instead of "ca". Adding okar, the "o" vowel mark, gives a reading of /t͡ʃo/. Like all Indic consonants, চ can be modified by marks to indicate another (or no) vowel than its inherent "a".
Bengali চ with vowel marks
ca
cā
ci
cī
cu
cū
cr
cr̄
ce
cai
co
cau
c
চ
চা
চি
চী
চু
চূ
চৃ
চৄ
চে
চৈ
চো
চৌ
চ্
চ in Bengali-using languages
চ is used as a basic consonant character in all of the major Bengali script orthographies, including Bengali and Assamese.
Conjuncts with চ
Bengali চ exhibits conjunct ligatures, as is common in Indic scripts. Unlike other Bengali letters, Ca does not tend towards stacked ligatures.[5]
চ্ (c) + চ (ca) gives the ligature cca:
চ্ (c) + ছ (cʰa) gives the ligature ccʰa:
চ্ (c) + ছ্ (cʰ) + র (ra) gives the ligature ccʰra, with the ra phala suffix:
চ্ (c) + ছ্ (cʰ) + র (ra) gives the ligature ccʰra, with the ra phala suffix:
চ্ (c) + ঞ (ña) gives the ligature cña:
চ্ (c) + ব (va) gives the ligature cva, with the va phala suffix:
চ্ (c) + য (ya) gives the ligature cya, with the ya phala suffix:
ঞ (ñ) + চ (ca) gives the ligature ñca:
র্ (r) + চ (ca) gives the ligature rca, with the repha prefix:
র্ (r) + চ্ (c) + য (ya) gives the ligature ṛcya, with the repha prefix and ya phala suffix:
শ্ (ʃ) + চ (ca) gives the ligature ʃca:
Gurmukhi script
Chachaa[t͡ʃət͡ʃːɑ] (ਚ) is the eleventh letter of the Gurmukhi alphabet. Its name is [t͡ʃət͡ʃːɑ] and is pronounced as /t͡ʃ/ when used in words. It is derived from the Laṇḍā letter ca, and ultimately from the Brahmi ca. Gurmukhi chachaa does not have a special pairin or addha (reduced) form for making conjuncts, and in modern Punjabi texts do not take a half form or halant to indicate the bare consonant /t͡ʃ/, although Gurmukhi Sanskrit texts may use an explicit halant.
Gujarati Ca
Gujarati Ca.
Ca (ચ) is the sixth consonant of the Gujaratiabugida. It is derived from the 16th century Devanagari Ca with the top bar (shiro rekha) removed, and ultimately from the Brahmi letter . The Gujarati letter Ca (ચ) should not be confused with the Gujarati vowel A (અ), and care should be taken when reading Gujarati script texts not to confuse the two.
Gujarati-using Languages
The Gujarati script is used to write the Gujarati and Kutchi languages. In both languages, ચ is pronounced as [cə] or [c] when appropriate. Like all Indic scripts, Gujarati uses vowel marks attached to the base consonant to override the inherent /ə/ vowel:
Ca
Cā
Ci
Cī
Cu
Cū
Cr
Cl
Cr̄
Cl̄
Cĕ
Ce
Cai
Cŏ
Co
Cau
C
Gujarati Ca syllables, with vowel marks in red.
Conjuncts with ચ
Half form of Ca.
Gujarati ચ exhibits conjunct ligatures, much like its parent Devanagari Script. Most Gujarati conjuncts can only be formed by reducing the letter shape to fit tightly to the following letter, usually by dropping a character's vertical stem, sometimes referred to as a "half form". A few conjunct clusters can be represented by a true ligature, instead of a shape that can be broken into constituent independent letters, and vertically stacked conjuncts can also be found in Gujarati, although much less commonly than in Devanagari. True ligatures are quite rare in Indic scripts. The most common ligated conjuncts in Gujarati are in the form of a slight mutation to fit in context or as a consistent variant form appended to the adjacent characters. Those variants include Na and the Repha and Rakar forms of Ra.
ર્ (r) + ચ (ca) gives the ligature RCa:
ચ્ (c) + ર (ra) gives the ligature CRa:
ચ્ (c) + ન (na) gives the ligature CNa:
શ્ (ʃ) + ચ (ca) gives the ligature ŚCa:
Thai script
Cho chan (จ) is the eighth letter of the Thai script. It falls under the middle class of Thai consonants. In IPA, cho chan is pronounced as [tɕ] at the beginning of a syllable and is pronounced as [t̚] at the end of a syllable. There are three other letters whose names contain cho in RTGS (and hence in the Unicode names), but their sounds at the beginning of syllable are [tɕʰ]. The ninth letter of the alphabet, cho ching (ฉ), is also named cho and falls under the high class of Thai consonants. The tenth and twelfth letters of the alphabet, cho chang (ช) and cho choe (ฌ), are also named cho, however, they all fall under the low class of Thai consonants. Unlike many Indic scripts, Thai consonants do not form conjunct ligatures, and use the pinthu—an explicit virama with a dot shape—to indicate bare consonants. In the acrophony of the Thai script, chan (จาน) means ‘plate’. Cho chan corresponds to the Sanskrit character ‘च’.
Ca (చ) is a consonant of the Teluguabugida. It ultimately arose from the Brahmi letter . It is closely related to the Kannada letter ಚ. Most Telugu consonants contain a v-shaped headstroke that is related to the horizontal headline found in other Indic scripts, although headstrokes do not connect adjacent letters in Telugu. The headstroke is normally lost when adding vowel matras. Telugu conjuncts are created by reducing trailing letters to a subjoined form that appears below the initial consonant of the conjunct. Many subjoined forms are created by dropping their headline, with many extending the end of the stroke of the main letter body to form an extended tail reaching up to the right of the preceding consonant. This subjoining of trailing letters to create conjuncts is in contrast to the leading half forms of Devanagari and Bengali letters. Ligature conjuncts are not a feature in Telugu, with the only non-standard construction being an alternate subjoined form of Ṣa (borrowed from Kannada) in the KṢa conjunct.
Malayalam Ca
Malayalam letter Ca
Ca (ച) is a consonant of the Malayalamabugida. It ultimately arose from the Brahmi letter , via the Grantha letter Ca. Like in other Indic scripts, Malayalam consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Malayalam Ca matras: Ca, Cā, Ci, Cī, Cu, Cū, Cr̥, Cr̥̄, Cl̥, Cl̥̄, Ce, Cē, Cai, Co, Cō, Cau, and C.
Conjuncts of ച
As is common in Indic scripts, Malayalam joins letters together to form conjunct consonant clusters. There are several ways in which conjuncts are formed in Malayalam texts: using a post-base form of a trailing consonant placed under the initial consonant of a conjunct, a combined ligature of two or more consonants joined together, a conjoining form that appears as a combining mark on the rest of the conjunct, the use of an explicit candrakkala mark to suppress the inherent "a" vowel, or a special consonant form called a "chillu" letter, representing a bare consonant without the inherent "a" vowel. Texts written with the modern reformed Malayalam orthography, put̪iya lipi, may favor more regular conjunct forms than older texts in paḻaya lipi, due to changes undertaken in the 1970s by the Government of Kerala.
ച് (c) + ച (ca) gives the ligature cca:
ഞ് (ñ) + ച (ca) gives the ligature ñca:
Odia Ca
Odia independent and subjoined letter Ca.
Ca (ଚ) is a consonant of the Odiaabugida. It ultimately arose from the Brahmi letter , via the Siddhaṃ letter Ca. Like in other Indic scripts, Odia consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Odia Ca with vowel matras
Ca
Cā
Ci
Cī
Cu
Cū
Cr̥
Cr̥̄
Cl̥
Cl̥̄
Ce
Cai
Co
Cau
C
ଚ
ଚା
ଚି
ଚୀ
ଚୁ
ଚୂ
ଚୃ
ଚୄ
ଚୢ
ଚୣ
ଚେ
ଚୈ
ଚୋ
ଚୌ
ଚ୍
Conjuncts of ଚ
As is common in Indic scripts, Odia joins letters together to form conjunct consonant clusters. The most common conjunct formation is achieved by using a small subjoined form of trailing consonants. Most consonants' subjoined forms are identical to the full form, just reduced in size, although a few drop the curved headline or have a subjoined form not directly related to the full form of the consonant. The second type of conjunct formation is through pure ligatures, where the constituent consonants are written together in a single graphic form. This ligature may be recognizable as being a combination of two characters or it can have a conjunct ligature unrelated to its constituent characters.
ଚ୍ (c) + ଚ (ca) gives the ligature cca:
ଚ୍ (c) + ଛ (cʰa) gives the ligature ccʰa:
ଞ୍ (ñ) + ଚ (ca) gives the ligature ñca:
Kaithi Ca
Kaithi consonant and half-form Ca.
Ca (𑂒) is a consonant of the Kaithiabugida. It ultimately arose from the Brahmi letter , via the Siddhaṃ letter Ca. Like in other Indic scripts, Kaithi consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Kaithi Ca with vowel matras
Ca
Cā
Ci
Cī
Cu
Cū
Ce
Cai
Co
Cau
C
𑂒
𑂒𑂰
𑂒𑂱
𑂒𑂲
𑂒𑂳
𑂒𑂴
𑂒𑂵
𑂒𑂶
𑂒𑂷
𑂒𑂸
𑂒𑂹
Conjuncts of 𑂒
As is common in Indic scripts, Kaithi joins letters together to form conjunct consonant clusters. The most common conjunct formation is achieved by using a half form of preceding consonants, although several consonants use an explicit virama. Most half forms are derived from the full form by removing the vertical stem. As is common in most Indic scripts, conjuncts of ra are indicated with a repha or rakar mark attached to the rest of the consonant cluster. In addition, there are a few vertical conjuncts that can be found in Kaithi writing, but true ligatures are not used in the modern Kaithi script.
𑂒୍ (c) + 𑂩 (ra) gives the ligature cra:
𑂩୍ (r) + 𑂒 (ca) gives the ligature rca:
Tirhuta Ca
Tirhuta consonant Ca
Ca (𑒔) is a consonant of the Tirhutaabugida. It ultimately arose from the Brahmi letter , via the Siddhaṃ letter Ca. Like in other Indic scripts, Tirhuta consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent sylables with another vowel or no vowel at all.
Tirhuta Ca with vowel matras
Ca
Cā
Ci
Cī
Cu
Cū
Cṛ
Cṝ
Cḷ
Cḹ
Cē
Ce
Cai
Cō
Co
Cau
C
𑒔
𑒔𑒰
𑒔𑒱
𑒔𑒲
𑒔𑒳
𑒔𑒴
𑒔𑒵
𑒔𑒶
𑒔𑒷
𑒔𑒸
𑒔𑒹
𑒔𑒺
𑒔𑒻
𑒔𑒼
𑒔𑒽
𑒔𑒾
𑒔𑓂
Conjuncts of 𑒔
As is common in Indic scripts, Tirhuta joins letters together to form conjunct consonant clusters. The most common conjunct formation is achieved by using an explicit virama. As is common in most Indic scripts, conjuncts of ra are indicated with a repha or rakar mark attached to the rest of the consonant cluster. In addition, other consonants take unique combining forms when in conjunct with other letters, and there are several vertical conjuncts and true ligatures that can be found in Tirhuta writing.
𑒔୍ (c) + 𑒔 (ca) gives the ligature cca:
𑒔୍ (c) + 𑒕 (cʰa) gives the ligature ccʰa:
𑒔୍ (c) + 𑒩 (ra) gives the ligature cra:
𑒔୍ (c) + 𑒫 (va) gives the ligature cva:
𑒘୍ (ñ) + 𑒔 (ca) gives the ligature ñca:
𑒩୍ (r) + 𑒔 (ca) gives the ligature rca:
𑒬୍ (ʃ) + 𑒔 (ca) gives the ligature ʃca:
𑒞୍ (t) + 𑒔 (ca) gives the ligature tca:
Comparison of Ca
The various Indic scripts are generally related to each other through adaptation and borrowing, and as such the glyphs for cognate letters, including Ca, are related as well.
↑The middle "Kushana" form of Brahmi is a later style that emerged as Brahmi scripts were beginning to proliferate. Gupta Brahmi was definitely a stylistic descendant from Kushana, but other Brahmi-derived scripts may have descended from earlier forms.
↑Tocharian is probably derived from the middle period "Kushana" form of Brahmi, although artifacts from that time are not plentiful enough to establish a definite succession.
↑Pyu and Old Mon are probably the precursors of the Burmese script, and may be derived from either the Pallava or Kadamba script
↑May also be derived from Devangari (see bottom left of table)
↑The Origin of Hangul from 'Phags-pa is one of limited influence, inspiring at most a few basic letter shapes. Hangul does not function as an Indic abugida.
↑Although the basic letter forms of the Canadian Aboriginal Syllabics were derived from handwritten Devanagari letters, this abugida indicates vowel sounds by rotations of the letter form, rather than the use of vowel diacritics as is standard in Indic abugidas.
↑Masaram Gondi acts as an Indic abugida, but its letterforms were not derived from any single precursor script.
Character encodings of Ca
Most Indic scripts are encoded in the Unicode Standard, and as such the letter Ca in those scripts can be represented in plain text with unique codepoint. Ca from several modern-use scripts can also be found in legacy encodings, such as ISCII.
↑Ifrah, Georges (2000). The Universal History of Numbers. From Prehistory to the Invention of the Computer. New York: John Wiley & Sons. pp.447–450. ISBN0-471-39340-1.
^note Conjuncts are identified by IAST transliteration, except aspirated consonants are indicated with a superscript "h" to distinguish from an unaspirated cononant + Ha, and the use of the IPA "ŋ" and "ʃ" instead of the less dinstinctive "ṅ" and "ś".
Further reading
Kurt Elfering: Die Mathematik des Aryabhata I. Text, Übersetzung aus dem Sanskrit und Kommentar. Wilhelm Fink Verlag, München, 1975, ISBN3-7705-1326-6
Georges Ifrah: The Universal History of Numbers. From Prehistory to the Invention of the Computer. John Wiley & Sons, New York, 2000, ISBN0-471-39340-1.
B. L. van der Waerden: Erwachende Wissenschaft. Ägyptische, babylonische und griechische Mathematik. Birkhäuser-Verlag, Basel Stuttgart, 1966, ISBN3-7643-0399-9
Fleet, J. F. (1911). "Aryabhata's System of Expressing Numbers". The Journal of the Royal Asiatic Society of Great Britain and Ireland. 43. Royal Asiatic Society of Great Britain and Ireland: 109–126. doi:10.1017/S0035869X00040995. JSTOR25189823.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.