In statistics, the Gauss–Markov theorem states that the ordinary least squares (OLS) estimator has the lowest sampling variance within the class of linear unbiased estimators, if the errors in the linear regression model are uncorrelated, have equal variances and expectation value of zero. The errors do not need to be normal, nor do they need to be independent and identically distributed. The requirement that the estimator be unbiased cannot be dropped, since biased estimators exist with lower variance. See, for example, the James–Stein estimator, ridge regression, or simply any degenerate estimator.

In statistics, the logistic model is a statistical model that models the probability of an event taking place by having the log-odds for the event be a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.
In econometrics, the autoregressive conditional heteroskedasticity (ARCH) model is a statistical model for time series data that describes the variance of the current error term or innovation as a function of the actual sizes of the previous time periods' error terms; often the variance is related to the squares of the previous innovations. The ARCH model is appropriate when the error variance in a time series follows an autoregressive (AR) model; if an autoregressive moving average (ARMA) model is assumed for the error variance, the model is a generalized autoregressive conditional heteroskedasticity (GARCH) model.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.
In statistics, a probit model is a type of regression where the dependent variable can take only two values, for example married or not married. The word is a portmanteau, coming from probability + unit. The purpose of the model is to estimate the probability that an observation with particular characteristics will fall into a specific one of the categories; moreover, classifying observations based on their predicted probabilities is a type of binary classification model.
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable.
In statistics and econometrics, the multivariate probit model is a generalization of the probit model used to estimate several correlated binary outcomes jointly. For example, if it is believed that the decisions of sending at least one child to public school and that of voting in favor of a school budget are correlated, then the multivariate probit model would be appropriate for jointly predicting these two choices on an individual-specific basis. J.R. Ashford and R.R. Sowden initially proposed an approach for multivariate probit analysis. Siddhartha Chib and Edward Greenberg extended this idea and also proposed simulation-based inference methods for the multivariate probit model which simplified and generalized parameter estimation.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.

In probability and statistics, the truncated normal distribution is the probability distribution derived from that of a normally distributed random variable by bounding the random variable from either below or above. The truncated normal distribution has wide applications in statistics and econometrics.
The topic of heteroskedasticity-consistent (HC) standard errors arises in statistics and econometrics in the context of linear regression and time series analysis. These are also known as heteroskedasticity-robust standard errors, Eicker–Huber–White standard errors, to recognize the contributions of Friedhelm Eicker, Peter J. Huber, and Halbert White.
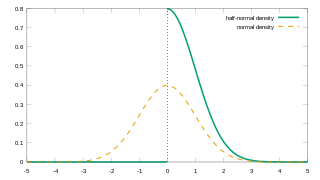
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.
The Heckman correction is a statistical technique to correct bias from non-randomly selected samples or otherwise incidentally truncated dependent variables, a pervasive issue in quantitative social sciences when using observational data. Conceptually, this is achieved by explicitly modelling the individual sampling probability of each observation together with the conditional expectation of the dependent variable. The resulting likelihood function is mathematically similar to the tobit model for censored dependent variables, a connection first drawn by James Heckman in 1974. Heckman also developed a two-step control function approach to estimate this model, which avoids the computational burden of having to estimate both equations jointly, albeit at the cost of inefficiency. Heckman received the Nobel Memorial Prize in Economic Sciences in 2000 for his work in this field.

In statistics, errors-in-variables models or measurement error models are regression models that account for measurement errors in the independent variables. In contrast, standard regression models assume that those regressors have been measured exactly, or observed without error; as such, those models account only for errors in the dependent variables, or responses.
In probability theory, the Mills ratio of a continuous random variable is the function
In statistics, ordinal regression, also called ordinal classification, is a type of regression analysis used for predicting an ordinal variable, i.e. a variable whose value exists on an arbitrary scale where only the relative ordering between different values is significant. It can be considered an intermediate problem between regression and classification. Examples of ordinal regression are ordered logit and ordered probit. Ordinal regression turns up often in the social sciences, for example in the modeling of human levels of preference, as well as in information retrieval. In machine learning, ordinal regression may also be called ranking learning.
In statistics, the variance function is a smooth function which depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.
The generalized functional linear model (GFLM) is an extension of the generalized linear model (GLM) that allows one to regress univariate responses of various types on functional predictors, which are mostly random trajectories generated by a square-integrable stochastic processes. Similarly to GLM, a link function relates the expected value of the response variable to a linear predictor, which in case of GFLM is obtained by forming the scalar product of the random predictor function with a smooth parameter function . Functional Linear Regression, Functional Poisson Regression and Functional Binomial Regression, with the important Functional Logistic Regression included, are special cases of GFLM. Applications of GFLM include classification and discrimination of stochastic processes and functional data.
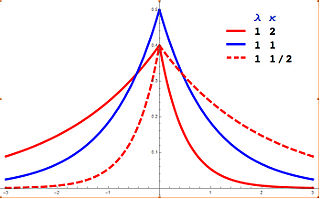
In probability theory and statistics, the asymmetric Laplace distribution (ALD) is a continuous probability distribution which is a generalization of the Laplace distribution. Just as the Laplace distribution consists of two exponential distributions of equal scale back-to-back about x = m, the asymmetric Laplace consists of two exponential distributions of unequal scale back to back about x = m, adjusted to assure continuity and normalization. The difference of two variates exponentially distributed with different means and rate parameters will be distributed according to the ALD. When the two rate parameters are equal, the difference will be distributed according to the Laplace distribution.
In probability theory and statistics, the discrete Weibull distribution is the discrete variant of the Weibull distribution. It was first described by Nakagawa and Osaki in 1975.
In econometrics, the truncated normal hurdle model is a variant of the Tobit model and was first proposed by Cragg in 1971.


























