
In probability theory and statistics, the cumulative distribution function (CDF) of a real-valued random variable , or just distribution function of , evaluated at , is the probability that will take a value less than or equal to .
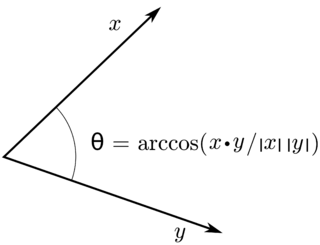
In mathematics, an inner product space is a real vector space or a complex vector space with an operation called an inner product. The inner product of two vectors in the space is a scalar, often denoted with angle brackets such as in . Inner products allow formal definitions of intuitive geometric notions, such as lengths, angles, and orthogonality of vectors. Inner product spaces generalize Euclidean vector spaces, in which the inner product is the dot product or scalar product of Cartesian coordinates. Inner product spaces of infinite dimension are widely used in functional analysis. Inner product spaces over the field of complex numbers are sometimes referred to as unitary spaces. The first usage of the concept of a vector space with an inner product is due to Giuseppe Peano, in 1898.
Probability theory is the branch of mathematics concerned with probability. Although there are several different probability interpretations, probability theory treats the concept in a rigorous mathematical manner by expressing it through a set of axioms. Typically these axioms formalise probability in terms of a probability space, which assigns a measure taking values between 0 and 1, termed the probability measure, to a set of outcomes called the sample space. Any specified subset of the sample space is called an event. Central subjects in probability theory include discrete and continuous random variables, probability distributions, and stochastic processes . Although it is not possible to perfectly predict random events, much can be said about their behavior. Two major results in probability theory describing such behaviour are the law of large numbers and the central limit theorem.
Independence is a fundamental notion in probability theory, as in statistics and the theory of stochastic processes.
In probability theory, the central limit theorem (CLT) establishes that, in many situations, when independent random variables are summed up, their properly normalized sum tends toward a normal distribution even if the original variables themselves are not normally distributed.

In probability theory and statistics, the negative binomial distribution is a discrete probability distribution that models the number of successes in a sequence of independent and identically distributed Bernoulli trials before a specified (non-random) number of failures occurs. For example, we can define rolling a 6 on a dice as a failure, and rolling any other number as a success, and ask how many successful rolls will occur before we see the third failure. In such a case, the probability distribution of the number of non-6s that appear will be a negative binomial distribution. We could similarly use the negative binomial distribution to model the number of days a certain machine works before it breaks down.

In probability theory and statistics, the geometric distribution is either one of two discrete probability distributions:
In probability, and statistics, a multivariate random variable or random vector is a list of mathematical variables each of whose value is unknown, either because the value has not yet occurred or because there is imperfect knowledge of its value. The individual variables in a random vector are grouped together because they are all part of a single mathematical system — often they represent different properties of an individual statistical unit. For example, while a given person has a specific age, height and weight, the representation of these features of an unspecified person from within a group would be a random vector. Normally each element of a random vector is a real number.
In probability and statistics, a Bernoulli process is a finite or infinite sequence of binary random variables, so it is a discrete-time stochastic process that takes only two values, canonically 0 and 1. The component Bernoulli variablesXi are identically distributed and independent. Prosaically, a Bernoulli process is a repeated coin flipping, possibly with an unfair coin. Every variable Xi in the sequence is associated with a Bernoulli trial or experiment. They all have the same Bernoulli distribution. Much of what can be said about the Bernoulli process can also be generalized to more than two outcomes ; this generalization is known as the Bernoulli scheme.
In probability theory and statistics, covariance is a measure of the joint variability of two random variables. If the greater values of one variable mainly correspond with the greater values of the other variable, and the same holds for the lesser values, the covariance is positive. In the opposite case, when the greater values of one variable mainly correspond to the lesser values of the other,, the covariance is negative. The sign of the covariance therefore shows the tendency in the linear relationship between the variables. The magnitude of the covariance is not easy to interpret because it is not normalized and hence depends on the magnitudes of the variables. The normalized version of the covariance, the correlation coefficient, however, shows by its magnitude the strength of the linear relation.
In probability theory, the probability generating function of a discrete random variable is a power series representation of the probability mass function of the random variable. Probability generating functions are often employed for their succinct description of the sequence of probabilities Pr(X = i) in the probability mass function for a random variable X, and to make available the well-developed theory of power series with non-negative coefficients.
In mathematics, the Hessian matrix or Hessian is a square matrix of second-order partial derivatives of a scalar-valued function, or scalar field. It describes the local curvature of a function of many variables. The Hessian matrix was developed in the 19th century by the German mathematician Ludwig Otto Hesse and later named after him. Hesse originally used the term "functional determinants".
In mathematics, a low-discrepancy sequence is a sequence with the property that for all values of N, its subsequence x1, ..., xN has a low discrepancy.

Given two random variables that are defined on the same probability space, the joint probability distribution is the corresponding probability distribution on all possible pairs of outputs. The joint distribution can just as well be considered for any given number of random variables. The joint distribution encodes the marginal distributions, i.e. the distributions of each of the individual random variables. It also encodes the conditional probability distributions, which deal with how the outputs of one random variable are distributed when given information on the outputs of the other random variable(s).
In probability theory, a compound Poisson distribution is the probability distribution of the sum of a number of independent identically-distributed random variables, where the number of terms to be added is itself a Poisson-distributed variable. In the simplest cases, the result can be either a continuous or a discrete distribution.
In mathematics, Muirhead's inequality, named after Robert Franklin Muirhead, also known as the "bunching" method, generalizes the inequality of arithmetic and geometric means.
Renewal theory is the branch of probability theory that generalizes the Poisson process for arbitrary holding times. Instead of exponentially distributed holding times, a renewal process may have any independent and identically distributed (IID) holding times that have finite mean. A renewal-reward process additionally has a random sequence of rewards incurred at each holding time, which are IID but need not be independent of the holding times.
In statistics and probability theory, a point process or point field is a collection of mathematical points randomly located on a mathematical space such as the real line or Euclidean space. Point processes can be used for spatial data analysis, which is of interest in such diverse disciplines as forestry, plant ecology, epidemiology, geography, seismology, materials science, astronomy, telecommunications, computational neuroscience, economics and others.

In probability theory and statistics, the noncentral chi-squared distribution is a noncentral generalization of the chi-squared distribution. It often arises in the power analysis of statistical tests in which the null distribution is a chi-squared distribution; important examples of such tests are the likelihood-ratio tests.

In probability theory and statistics, the generalized chi-squared distribution is the distribution of a quadratic form of a multinormal variable, or a linear combination of different normal variables and squares of normal variables. Equivalently, it is also a linear sum of independent noncentral chi-square variables and a normal variable. There are several other such generalizations for which the same term is sometimes used; some of them are special cases of the family discussed here, for example the gamma distribution.
























