Bengkalis Regency is a regency of Indonesia in Riau Province. The regency was originally established in 1956 and then included most of the northern part of the province, but on 4 October 1999 it was divided up, with most of the territory being split off to form the new Rokan Hilir Regency, Siak Regency and the city of Dumai. On 19 December 2008 a further five districts were removed to create the new Meranti Islands Regency, leaving eight districts in the Bengkalis Regency. These eight districts has increased since 2010 to eleven by the splitting of existing districts on the Sumatran mainland.

Wonosobo Regency is a regency in Central Java province in Indonesia. The administrative centre of the regency is located in the town of Wonosobo, located at 7.3684940°S 109.8983841°E, about 120 km from Semarang on the Dieng Plateau. The regency's area is 984.68 km2 and its population was 754,883 at the 2010 census and 879,124 at the 2020 census; the official estimate as at mid 2023 was 909,664.

Karo Regency is a landlocked regency of North Sumatra Province of Indonesia, situated in the Barisan Mountains. The regency, which was established on 7 November 1956, covers an area of 2,127.25 square kilometres (821.34 sq mi) and according to the 2010 census it had a population of 350,479, increasing to 404,998 at the 2020 Census; the official estimate as at mid-2023 was 420,799, comprising 208,600 males and 212,200 females. 60.99% of the regency is forested. Its regency seat is the town of Kabanjahe. The Batak Karo language is spoken in the regency, as well as the Indonesian language. It borders Southeast Aceh Regency in Aceh to the west, Deli Serdang Regency and Langkat Regency to the north, Dairi Regency and Toba Samosir Regency to the south, and Deli Serdang Regency and Simalungun Regency to the east.

Lamongan Regency is a regency of the East Java Province of Indonesia. It has a total land area of approximately 1,812.8 km2 (699.9 sq mi) or + 3.78% of the area of East Java Province. With a length of 47 km (29 mi) along the coastline, the sea area of Lamongan Regency is about 902.4 km2 (348.4 sq mi), if calculated to a distance of 12 miles (19 km) across the ocean surface. At the 2010 census it had a population of 1,179,059; the 2020 Census produced a total of 1,379,628 and the official estimate as at mid-2023 was 1,385,835. The regency seat is the town of Lamongan, situated on the Solo River which passes from west to east through the regency, effectively dividing it in two.

Nganjuk Regency is a regency (kabupaten) of East Java Province, Indonesia. It borders Bojonegoro Regency in the north, Jombang Regency in the east, Kediri Regency in the south and Madiun Regency in the west. It covers an area of 1,224.33 sq. km, and had a population of 1,017,030 at the 2010 Census and 1,103,902 at the 2020 Census; the official estimate as of mid-2023 was 1,144,508. The administrative centre of the regency is the town of Nganjuk. The current regent is Dr. Drs. H. Marhaen Djumadi, S.E., S.H., M.M., M.B.A.

Pamekasan Regency is a regency (kabupaten) of the province of East Java, Indonesia. It is located on Madura Island approximately 120 kilometres (75 mi) east of Surabaya, the provincial capital. The regency covers an area of 792.30 square kilometres (305.91 sq mi), and at the 2010 census it had a population of 795,918 ; at the 2020 census the total was 850,057 and the official estimate as of mid-2023 was 882,837 – comprising 431,891 males and 450,946 females. The administrative capital is the town of Pamekasan.

Sampang Regency is a regency of East Java province, Indonesia. It is situated on Madura Island, bordering on Pamekasan Regency to the east, the Java Sea to the north, Bangkalan Regency to the west, and Madura Strait to the south. It covers an area of 1,228.25 km2, and had a population of at the 2010 census 877,772 and at the 2020 census 969,694; the official estimate as of mid-2023 was 988,360 - comprising 488,900 males and 499,460 females. The administrative centre is the port of Sampang, on the south coast of Madura.

Purwakarta Regency is a landlocked regency (kabupaten) of West Java, Indonesia. The town of Purwakarta is its regency seat.

Sukoharjo Regency is a regency in the Central Java province in Indonesia. It covers an area of 493.23 km2 and had a population of 824,238 at the 2010 Census and 907,587 at the 2020 Census; the official estimate as of mid-2023 was 932,680. Its administrative centre is in the town of Sukoharjo, about 10 km south of Surakarta. This regency is bordered by the city of Surakarta in the north, Karanganyar Regency in the east, Wonogiri Regency and Yogyakarta in the south as well as Klaten Regency in the west. The regency is part of the metropolitan zone of Surakarta, which is known as Subosukawonosraten.

Banjarnegara is an inland regency in the southwestern part of Central Java province in Indonesia. The regency covers an area of 1,069.73 km2, and it had a population of 868,913 at the 2010 Census and 1,017,767 at the 2020 Census; the official estimate as at mid 2023 was 1,047,226. Its capital is the town of Banjarnegara.
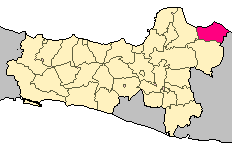
Rembang Regency is a regency on the extreme northeast coast of Central Java Province, on the island of Java in Indonesia. The regency covers an area of 1,036.70 km2 on Java, and it had a population of 591,359 at the 2010 Census and 645,333 at the 2020 Census; the official estimate as of mid-2023 was 660,166, of whom 331,870 were males and 328,296 were females. Its administrative capital is the town of Rembang.

Sragen Regency is a regency in the eastern part of Central Java province in Indonesia. It covers an area of 994.57 km2 and had a population of 858,266 at the 2010 Census and 976,951 at the 2020 Census; the official estimate as at mid 2023 was 997,485. Its capital is the town of Sragen, located about 30 km to the northeast of Surakarta. Sragen is bordered by East Java Province to the east.

Kediri Regency is a regency (kabupaten) located in East Java province, Indonesia. It is one of two 'Daerah Tingkat II' that has the name 'Kediri'. The Regency covers an area of 1,563.42 km2 and had a population of 1,499,768 as of the 2010 census and 1,635,294 at the 2020 census; the official estimate as at mid 2023 was 1,684,454.

Mojokerto Regency is a regency in East Java Province of Indonesia. It is part of the Surabaya metropolitan area which comprises Gresik Regency, Bangkalan Regency, Mojokerto Regency, Mojokerto City, Surabaya City, Sidoarjo Regency, and Lamongan Regency. The Regency covers an area of 969.36 km2. The population of the Regency was 908,004 in 2000, but had risen to 1,025,443 at the 2010 Census and to 1,119,209 at the 2020 Census; the official estimate as of mid-2022 was 1,133,584, and the total for mid-2023 was 1,145,400. Many of them earn their living as small farmers and craftsmen.

East Sumba Regency is geographically the largest of the four regencies which divide the island of Sumba, within East Nusa Tenggara Province of Indonesia. It occupies 62% of the entire island, being much less densely populated than the western third. The town of Waingapu is the capital of East Sumba Regency. The population of East Sumba Regency was 227,732 at the 2010 Census and 244,820 at the 2020 Census; the official estimate as at mid 2022 was 255,498.

Dompu Regency is a regency of the Indonesian Province of West Nusa Tenggara. It is located on the island of Sumbawa and the capital is Dompu. It is bordered to the north and to the east by two non-contiguous parts of Bima Regency, and to the west by Sumbawa Regency, as well as on its coasts by Saleh Bay, Sanggar Bay, and Cempi Bay. It covers an area of 2,324.55 km2, and the population at the 2010 Census was 218,984 and at the 2020 Census was 236,665; the official estimate as at mid 2023 was 247,188.

East Flores Regency is a regency in East Nusa Tenggara province of Indonesia. Established in 1958, the regency has its seat (capital) in Larantuka on Flores Island. It covers a land area of 1,812.58 km2, and it had a population of 232,605 as of the 2010 census and 276,896 at the 2020 Census; the official estimate as of mid-2023 was 288,310 - comprising 141,738 males and 146,572 females. The regency encompasses the eastern tip of the island of Flores, together with all of the adjacent islands of Adonara and Solor to the east of Flores, with some much smaller offshore islands. On 4 October 1999, the island of Lembata at the eastern end of the Solor Archipelago was separated from the East Flores Regency to create its own Regency.

Paser Regency is the southernmost regency (kabupaten) within the East Kalimantan province of Indonesia. It was created in 1959, originally spelt "Pasir Regency", but renamed "Paser" in 2007; however its northeastern districts were split off on 10 April 2002 to form the new Penajam North Paser Regency. The residual regency covers an area of 11,603.94 km2, and it had a population of 230,316 at the 2010 Census and 275,452 at the 2020 Census; the official estimate as at mid-2023 was 303,424. Its administrative centre is the town of Tana Paser.

Merangin Regency is a regency (kabupaten) of Jambi Province on the island of Sumatra, Indonesia. It was created on 4 October 1999 by the division of the former Sarolangun Bangko Regency into a new Sarolangun Regency in the east and this Merangin Regency in the west. The regency covers an area of 7,679.0 km2, and had a population of 333,206 at the 2010 census and 354,052 at the 2020 census; the official estimate as at mid 2023 was 368,389 - comprising 187,026 males and 181,363 females. The administrative capital is the town of Bangko.
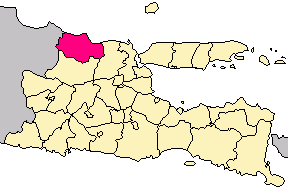
Tuban Regency is a regency in the East Java province of Indonesia. The Dutch name of the regency is 'Toeban'. It covers a land area of 1,839.94 sq. km, and had a population of 1,118,464 at the 2010 Census and 1,198,012 at the 2020 Census; the official estimate as of mid-2023 was 1,258,368. The administrative centre is the coastal town of Tuban.