Jombang Regency is a regency of East Java, Indonesia, situated to the southwest of Surabaya. The capital of the regency is the town of Jombang. The regency has an area of 1,159.50 km2 and a population of 1,202,407 at the 2010 census and 1,318,062 at the 2020 census; the official estimate as of mid-2023 was 1,370,510. It became a regency in 1910. It was the birthplace of Abdurrahman Wahid, the 4th president of Indonesia.

Sikka is a regency within East Nusa Tenggara province, Indonesia, on the island of Flores. It is bordered to the west by Ende Regency and to the east by East Flores Regency. It covers an area of 1,675.36 km2 and had a population of 300,301 at the 2010 census and 321,953 at the 2020 Census; the official estimate as at mid 2023 was 335,360 - comprising 163,060 males and 172,300 females). The capital is the town of Maumere, which comprises the districts of Alok Barat, Alok and Alok Timur.

Ende Regency is a regency on the island of Flores, within East Nusa Tenggara Province of Indonesia. The capital is the town of Ende, on the south coast of the Regency. The regency covers an area of 2,085.19 km2, and it had a population of 260,605 at the 2010 Census and 270,763 at the 2020 Census; the official estimate as at mid 2023 was 278,581. It is bordered to the west by Nagekeo Regency and to the east by Sikka Regency, while the Flores Sea lies to the north and the Savu Sea to the south.

Bangkalan Regency is a regency of East Java province in Indonesia. The seat of its government is the town of Bangkalan. The regency is located on the west side of Madura Island, bordering Sampang Regency to the east, Java Sea to the north, and Madura Strait to the west and the south sides. It covers an area of 1,260.15 km2, and had a population of 906,761 at the 2010 census and reached 1,060,377 at the 2020 census; however the official estimate as at mid-2023 showed a decline to 1,047,306 – comprising 515,428 males and 531,878 females.

Nganjuk Regency is a regency (kabupaten) of East Java Province, Indonesia. It borders Bojonegoro Regency in the north, Jombang Regency in the east, Kediri Regency in the south and Madiun Regency in the west. It covers an area of 1,224.33 sq. km, and had a population of 1,017,030 at the 2010 Census and 1,103,902 at the 2020 Census; the official estimate as of mid-2023 was 1,144,508. The administrative centre of the regency is the town of Nganjuk. The current regent is Dr. Drs. H. Marhaen Djumadi, S.E., S.H., M.M., M.B.A.

Pamekasan Regency is a regency (kabupaten) of the province of East Java, Indonesia. It is located on Madura Island approximately 120 kilometres (75 mi) east of Surabaya, the provincial capital. The regency covers an area of 792.30 square kilometres (305.91 sq mi), and at the 2010 census it had a population of 795,918 ; at the 2020 census the total was 850,057 and the official estimate as of mid-2023 was 882,837 – comprising 431,891 males and 450,946 females. The administrative capital is the town of Pamekasan.

Sampang Regency is a regency of East Java province, Indonesia. It is situated on Madura Island, bordering on Pamekasan Regency to the east, the Java Sea to the north, Bangkalan Regency to the west, and Madura Strait to the south. It covers an area of 1,228.25 km2, and had a population of at the 2010 census 877,772 and at the 2020 census 969,694; the official estimate as of mid-2023 was 988,360 - comprising 488,900 males and 499,460 females. The administrative centre is the port of Sampang, on the south coast of Madura.

Situbondo Regency is a regency (kabupaten) in the east of East Java province, Indonesia. It covers an area of 1,658.03 km2, and had a population of 647,619 at the 2010 Census and 685,967 at the 2020 Census; the official estimate as at mid 2023 was 684,343. It is located towards the eastern end of Java, before Banyuwangi. The administrative centre is Situbondo, a small town within the regency. One of the famous tourist sites is Baluran National Park.

South Bengkulu is a regency of Bengkulu Province, Indonesia, on the island of Sumatra. It originally comprised all of that part of Bengkulu Province situated to the southeast of the city of Bengkulu, but on 25 February 2003 this area was split into three parts, with the most southeastern districts split off to form a new Kaur Regency and the most northwestern districts split off to form a new Seluma Regency. The reduced South Bengkulu Regency now covers 1,186.10 km2, and had a population of 142,940 at the 2010 Census and 166,249 at the 2020 Census; the official estimate as at mid 2022 was 170,093. The regency's administrative centre is the coastal town of Manna.

Banjarnegara is an inland regency in the southwestern part of Central Java province in Indonesia. The regency covers an area of 1,069.73 km2, and it had a population of 868,913 at the 2010 Census and 1,017,767 at the 2020 Census; the official estimate as at mid 2022 was 1,038,718. Its capital is the town of Banjarnegara.

Soppeng Regency is a landlocked regency in South Sulawesi province of Indonesia. Soppeng Regency has its seat of government (capital) in the town of Watansoppeng, located 180 km from Makassar. The regency covers an area of 1,557 km2, and had a population of 223,826 at the 2010 Census and 235,167 at the 2020 Census; the official estimate as at mid 2022 was 236,049.

Asahan Regency is a regency in North Sumatra Province of Indonesia. Following the creation of the new Batubara Regency, the regency now covers an area of 3,732.97 square kilometres; it had a population of 668,272 according to the 2010 census and 769,960 in the 2020 Census; the official estimate as of mid-2023 was 802,563. Its administrative centre is now the large town of Kisaran. The Regency surrounds but now does not include the city of Tanjungbalai which was its capital until created an independent city in 1984. The Asahan Sultanate was located in the region.

Mojokerto Regency is a regency in East Java Province of Indonesia. It is part of the Surabaya metropolitan area which comprises Gresik Regency, Bangkalan Regency, Mojokerto Regency, Mojokerto City, Surabaya City, Sidoarjo Regency, and Lamongan Regency. The Regency covers an area of 969.36 km2. The population of the Regency was 908,004 in 2000, but had risen to 1,025,443 at the 2010 Census and to 1,119,209 at the 2020 Census; the official estimate as of mid-2022 was 1,133,584, and the total for mid-2023 was 1,145,400. Many of them earn their living as small farmers and craftsmen.

South Labuhanbatu Regency is a regency of North Sumatra Province of Indonesia, created on 21 July 2008 by being carved out of the southern districts of the existing Labuhanbatu Regency. The new South Labuhanbatu Regency covers an area of 3,596 square kilometres and according to the 2010 census it had a population of 277,673, which rose to 314,094 at the 2020 Census; the official estimate as at mid 2023 was 330,797. Its administrative headquarters are at the town of Kotapinang.

Langkat Regency is the northernmost regency of North Sumatra Province in Indonesia. Its administrative centre is the town of Stabat. It has a land area of 6,263.29 km2 and its population was 967,535 at the 2010 Census and 1,030,202 at the 2020 Census; the official estimate as at mid 2023 was 1,066,711 - comprising 538,822 males and 527,889 females.

Mandailing Natal, abbreviated as Madina, is a regency in North Sumatra Province of Indonesia. It covers an area of 6,620.70 square kilometres and it had a population of 403,894 people at the 2010 census and 472,886 at the 2020 Census; the official estimate as at mid 2023 was 496,975. The capital lies at Panyabungan. The Regency was formerly a part of South Tapanuli Regency until it was created as a separate regency on 23 November 1998. It is the southernmost regency in North Sumatra, and the largest regency by land area in the province, with Langkat Regency second to it.

Sumbawa Regency is a Regency (Kabupaten) of the Indonesian Province of West Nusa Tenggara. It is located on the island of Sumbawa and covers an area of 6,643.99 km2, following the separation on 18 December 2003 of what were until then its westernmost five districts to form the newly-created West Sumbawa Regency. It includes the substantial island of Moyo, lying off the north coast of Sumbawa. The population of the Regency at the 2010 Census was 415,789, which rose at the 2020 Census to 509,753; the official estimate as at mid 2023 was 529,487. The capital is the town of Sumbawa Besar on the north coast of Sumbawa Island.

East Flores Regency is a regency in East Nusa Tenggara province of Indonesia. Established in 1958, the regency has its seat (capital) in Larantuka on Flores Island. It covers a land area of 1,812.58 km2, and it had a population of 232,605 as of the 2010 census and 276,896 at the 2020 Census; the official estimate as of mid-2023 was 288,310 - comprising 141,738 males and 146,572 females. The regency encompasses the eastern tip of the island of Flores, together with all of the adjacent islands of Adonara and Solor to the east of Flores, with some much smaller offshore islands. On 4 October 1999, the island of Lembata at the eastern end of the Solor Archipelago was separated from the East Flores Regency to create its own Regency.

West Kotawaringin Regency is one of the thirteen regencies which comprise the Central Kalimantan Province on the island of Kalimantan (Borneo), Indonesia. It originally comprised the whole western part of the province, but on 10 April 2002 the most westerly districts were split off to form the new Lamandau Regency and Sukamara Regency. The population of the residual part of West Kotawaringin Regency was 235,803 at the 2010 Census and 270,388 at the 2020 Census; the official estimate as at mid 2022 was 274,935. The town of Pangkalan Bun in Arut Selatan District is the capital of West Kotawaringin Regency. The regency has an area of about 10,759 km2.
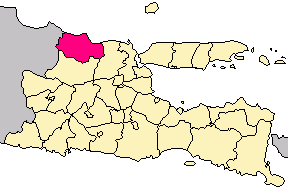
Tuban Regency is a regency in the East Java province of Indonesia. The Dutch name of the regency is 'Toeban'. It covers a land area of 1,839.94 sq. km, and had a population of 1,118,464 at the 2010 Census and 1,198,012 at the 2020 Census; the official estimate as of mid-2023 was 1,258,368. The administrative centre is the coastal town of Tuban.