
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Nucleic acids are biopolymers, or large biomolecules, essential to all known forms of life. They are composed of nucleotides, which are the monomers made of three components: a 5-carbon sugar, a phosphate group and a nitrogenous base. The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). If the sugar is ribose, the polymer is RNA; if the sugar is the ribose derivative deoxyribose, the polymer is DNA.

Nucleotides are organic molecules consisting of a nucleoside and a phosphate. They serve as monomeric units of the nucleic acid polymers – deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), both of which are essential biomolecules within all life-forms on Earth. Nucleotides are obtained in the diet and are also synthesized from common nutrients by the liver.

Nucleobases, also known as nitrogenous bases or often simply bases, are nitrogen-containing biological compounds that form nucleosides, which, in turn, are components of nucleotides, with all of these monomers constituting the basic building blocks of nucleic acids. The ability of nucleobases to form base pairs and to stack one upon another leads directly to long-chain helical structures such as ribonucleic acid (RNA) and deoxyribonucleic acid (DNA).
A nucleic acid sequence is a succession of bases signified by a series of a set of five different letters that indicate the order of nucleotides forming alleles within a DNA or RNA (GACU) molecule. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.

A wobble base pair is a pairing between two nucleotides in RNA molecules that does not follow Watson-Crick base pair rules. The four main wobble base pairs are guanine-uracil (G-U), hypoxanthine-uracil (I-U), hypoxanthine-adenine (I-A), and hypoxanthine-cytosine (I-C). In order to maintain consistency of nucleic acid nomenclature, "I" is used for hypoxanthine because hypoxanthine is the nucleobase of inosine; nomenclature otherwise follows the names of nucleobases and their corresponding nucleosides. The thermodynamic stability of a wobble base pair is comparable to that of a Watson-Crick base pair. Wobble base pairs are fundamental in RNA secondary structure and are critical for the proper translation of the genetic code.
Endonucleases are enzymes that cleave the phosphodiester bond within a polynucleotide chain. Some, such as deoxyribonuclease I, cut DNA relatively nonspecifically, while many, typically called restriction endonucleases or restriction enzymes, cleave only at very specific nucleotide sequences. Endonucleases differ from exonucleases, which cleave the ends of recognition sequences instead of the middle (endo) portion. Some enzymes known as "exo-endonucleases", however, are not limited to either nuclease function, displaying qualities that are both endo- and exo-like. Evidence suggests that endonuclease activity experiences a lag compared to exonuclease activity.

A Hoogsteen base pair is a variation of base-pairing in nucleic acids such as the A•T pair. In this manner, two nucleobases, one on each strand, can be held together by hydrogen bonds in the major groove. A Hoogsteen base pair applies the N7 position of the purine base and C6 amino group, which bind the Watson–Crick (N3–C4) face of the pyrimidine base.

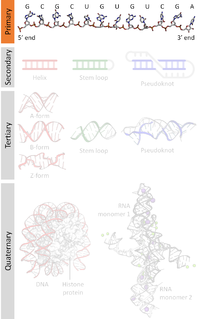
Biomolecular structure is the intricate folded, three-dimensional shape that is formed by a molecule of protein, DNA, or RNA, and that is important to its function. The structure of these molecules may be considered at any of several length scales ranging from the level of individual atoms to the relationships among entire protein subunits. This useful distinction among scales is often expressed as a decomposition of molecular structure into four levels: primary, secondary, tertiary, and quaternary. The scaffold for this multiscale organization of the molecule arises at the secondary level, where the fundamental structural elements are the molecule's various hydrogen bonds. This leads to several recognizable domains of protein structure and nucleic acid structure, including such secondary-structure features as alpha helixes and beta sheets for proteins, and hairpin loops, bulges, and internal loops for nucleic acids. The terms primary, secondary, tertiary, and quaternary structure were introduced by Kaj Ulrik Linderstrøm-Lang in his 1951 Lane Medical Lectures at Stanford University.

Directionality, in molecular biology and biochemistry, is the end-to-end chemical orientation of a single strand of nucleic acid. In a single strand of DNA or RNA, the chemical convention of naming carbon atoms in the nucleotide pentose-sugar-ring means that there will be a 5′-end, which frequently contains a phosphate group attached to the 5′ carbon of the ribose ring, and a 3′-end, which typically is unmodified from the ribose -OH substituent. In a DNA double helix, the strands run in opposite directions to permit base pairing between them, which is essential for replication or transcription of the encoded information.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology and evolutionary biology. It is intended as introductory material for novices; for more specific and technical detail, see the article corresponding to each term. For related terms, see Glossary of evolutionary biology.
Nucleic acid thermodynamics is the study of how temperature affects the nucleic acid structure of double-stranded DNA (dsDNA). The melting temperature (Tm) is defined as the temperature at which half of the DNA strands are in the random coil or single-stranded (ssDNA) state. Tm depends on the length of the DNA molecule and its specific nucleotide sequence. DNA, when in a state where its two strands are dissociated, is referred to as having been denatured by the high temperature.
Nucleic acid analogues are compounds which are analogous to naturally occurring RNA and DNA, used in medicine and in molecular biology research. Nucleic acids are chains of nucleotides, which are composed of three parts: a phosphate backbone, a pentose sugar, either ribose or deoxyribose, and one of four nucleobases. An analogue may have any of these altered. Typically the analogue nucleobases confer, among other things, different base pairing and base stacking properties. Examples include universal bases, which can pair with all four canonical bases, and phosphate-sugar backbone analogues such as PNA, which affect the properties of the chain . Nucleic acid analogues are also called Xeno Nucleic Acid and represent one of the main pillars of xenobiology, the design of new-to-nature forms of life based on alternative biochemistries.
Ribosomal frameshifting, also known as translational frameshifting or translational recoding, is a biological phenomenon that occurs during translation that results in the production of multiple, unique proteins from a single mRNA. The process can be programmed by the nucleotide sequence of the mRNA and is sometimes affected by the secondary, 3-dimensional mRNA structure. It has been described mainly in viruses, retrotransposons and bacterial insertion elements, and also in some cellular genes.
The nucleic acid notation currently in use was first formalized by the International Union of Pure and Applied Chemistry (IUPAC) in 1970. This universally accepted notation uses the Roman characters G, C, A, and T, to represent the four nucleotides commonly found in deoxyribonucleic acids (DNA). Given the rapidly expanding role for genetic sequencing, synthesis, and analysis in biology, researchers have been compelled to develop alternate notations to further support the analysis and manipulation of genetic data. These notations generally exploit size, shape, and symmetry to accomplish these objectives.
Experimental approaches of determining the structure of nucleic acids, such as RNA and DNA, can be largely classified into biophysical and biochemical methods. Biophysical methods use the fundamental physical properties of molecules for structure determination, including X-ray crystallography, NMR and cryo-EM. Biochemical methods exploit the chemical properties of nucleic acids using specific reagents and conditions to assay the structure of nucleic acids. Such methods may involve chemical probing with specific reagents, or rely on native or analogue chemistry. Different experimental approaches have unique merits and are suitable for different experimental purposes.

Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNA's and RNA's tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.
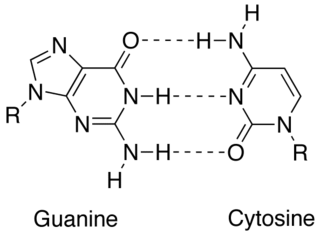
In molecular biology, complementarity describes a relationship between two structures each following the lock-and-key principle. In nature complementarity is the base principle of DNA replication and transcription as it is a property shared between two DNA or RNA sequences, such that when they are aligned antiparallel to each other, the nucleotide bases at each position in the sequences will be complementary, much like looking in the mirror and seeing the reverse of things. This complementary base pairing allows cells to copy information from one generation to another and even find and repair damage to the information stored in the sequences.

Nucleic acidquaternary structure refers to the interactions between separate nucleic acid molecules, or between nucleic acid molecules and proteins. The concept is analogous to protein quaternary structure, but as the analogy is not perfect, the term is used to refer to a number of different concepts in nucleic acids and is less commonly encountered. Similarly other biomolecules such as proteins, nucleic acids have four levels of structural arrangement: primary, secondary, tertiary, and quaternary structure. Primary structure is the linear sequence of nucleotides, secondary structure involves small local folding motifs, and tertiary structure is the 3D folded shape of nucleic acid molecule. In general, quaternary structure refers to 3D interactions between multiple subunits. In the case of nucleic acids, quaternary structure refers to interactions between multiple nucleic acid molecules or between nucleic acids and proteins. Nucleic acid quaternary structure is important for understanding DNA, RNA, and gene expression because quaternary structure can impact function. For example, when DNA is packed into chromatin, therefore exhibiting a type of quaternary structure, gene transcription will be inhibited.
