
S, or for lowercase, s, is the nineteenth letter of the Latin alphabet, used in the English alphabet, the alphabets of other western European languages and other latin alphabets worldwide. Its name in English is ess, plural esses.
A cedilla, or cedille, is a hook or tail added under certain letters as a diacritical mark to modify their pronunciation. In Catalan, French, and Portuguese it is used only under the letter c, and the entire letter is called, respectively, c trencada, c cédille, and c cedilhado. It is used to mark vowel nasalization in many languages of Sub-Saharan Africa, including Vute from Cameroon.

Ç or ç (C-cedilla) is a Latin script letter used in the Albanian, Azerbaijani, Manx, Tatar, Turkish, Turkmen, Kurdish, Kazakh, and Romance alphabets. Romance languages that use this letter include Catalan, French, Portuguese, and Occitan, as a variant of the letter C with a cedilla. It is also occasionally used in Crimean Tatar and in Tajik to represent the sound. It is rarely used in Balinese, usually only in the word "Çaka" during Nyepi, one of the Balinese Hinduism holidays. It is often retained in the spelling of loanwords from any of these languages in English, Basque, Dutch, Spanish and other languages using the Latin alphabet.
A caron is a diacritic mark placed over certain letters in the orthography of some languages, to indicate a change of the related letter's pronunciation.

The grapheme Š, š is used in various contexts representing the sh sound like in the word show, usually denoting the voiceless postalveolar fricative /ʃ/ or similar voiceless retroflex fricative /ʂ/. In the International Phonetic Alphabet this sound is denoted with ʃ or ʂ, but the lowercase š is used in the Americanist phonetic notation, as well as in the Uralic Phonetic Alphabet. It represents the same sound as the Turkic letter Ş and the Romanian letter Ș (S-comma), the Hebrew and Yiddish letter ש, the Ge'ez (Ethiopic) letter ሠ,the Cyrillic letter Ш, the Arabic letter ش, and the Armenian letter Շ(շ).
ISO/IEC 8859-2:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 2: Latin alphabet No. 2, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as "Latin-2". It is generally intended for Central or "Eastern European" languages that are written in the Latin script. Note that ISO/IEC 8859-2 is very different from code page 852 which is also referred to as "Latin-2" in Czech and Slovak regions. Almost half the use of the encoding is for Polish, and it's the main legacy encoding for Polish, while virtually all use of it has been replaced by UTF-8.

S-cedilla is a letter used in some of the Turkic languages. It occurs in the Azerbaijani, Gagauz, Turkish, and Turkmen alphabets. It is also planned to be in the Latin-based Kazakh alphabet. It is used in Brahui, Chechen, Crimean Tatar, Kurdish, and Tatar as well, when they are written in the Latin alphabet.

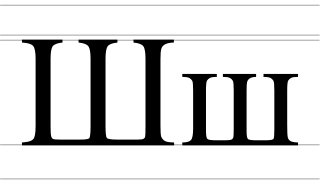
Ll/ll is a digraph that occurs in several languages.

A digraph or digram is a pair of characters used in the orthography of a language to write either a single phoneme, or a sequence of phonemes that does not correspond to the normal values of the two characters combined.

The Romanian alphabet is a variant of the Latin alphabet used for writing the Romanian language. It is a modification of the classical Latin alphabet and consists of 31 letters, five of which have been modified from their Latin originals for the phonetic requirements of the language.
Sha, She or Shu, alternatively transliterated Ša is a letter of the Glagolitic and Cyrillic scripts. It commonly represents the voiceless postalveolar fricative, like the pronunciation of sh in "ship". More precisely, the sound in Russian denoted by ш is commonly transcribed as a palatoalveolar fricative but is actually a voiceless retroflex fricative. It is used in every variation of the Cyrillic alphabet for Slavic and non-Slavic languages.

Esh is a character used in phonology to represent the voiceless postalveolar fricative.

T-comma is a letter which consists of a t with a diacritical comma underneath it, and is distinct from t-cedilla. It is part of the Romanian alphabet, used to represent the Romanian language sound, the voiceless alveolar affricate. The letter is also a part of the Finno-Ugric Livonian language alphabet, representing the sound.

Ś is a letter of the Latin alphabet, formed from S with the addition of an acute accent. It is used in Polish and Montenegrin alphabets, and in certain other languages or romanizations.

Ch is a digraph in the Latin script. It is treated as a letter of its own in the Chamorro, Old Spanish, Czech, Slovak, Igbo, Uzbek, Quechua, Ladino, Guarani, Welsh, Cornish, Breton, Ukrainian, Japanese, Latynka, and Belarusian Łacinka alphabets. Formerly ch was also considered a separate letter for collation purposes in Modern Spanish, Vietnamese, and sometimes in Polish; now the digraph ch in these languages continues to be used, but it is considered as a sequence of letters and sorted as such.

T-cedilla is a letter which is part of the Gagauz alphabet, used to represent the sound, the voiceless alveolar affricate. It is written as the letter T with a cedilla below and it has both the lower-case (U+0163) and the upper-case variants (U+0162). It is also used in the Manjak and Mankanya language for.

J, or j, is the tenth letter of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its usual name in English is jay, with a now-uncommon variant jy.

C, or c, is the third letter of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is cee, plural cees.
Unicode supports several phonetic scripts and notation systems through its existing scripts and the addition of extra blocks with phonetic characters. These phonetic characters are derived from an existing script, usually Latin, Greek or Cyrillic. Apart from the International Phonetic Alphabet (IPA), extensions to the IPA and obsolete and nonstandard IPA symbols, these blocks also contain characters from the Uralic Phonetic Alphabet and the Americanist Phonetic Alphabet.

In Hebrew orthography the rafe or raphe is a diacritic, a subtle horizontal overbar placed above certain letters to indicate that they are to be pronounced as fricatives.



