Ariel is the fourth-largest moon of Uranus. Ariel orbits and rotates in Uranus's equatorial plane, which is almost perpendicular to the planet's orbit, giving the moon an extreme seasonal cycle.
It was discovered on 24 October 1851 by William Lassell and named for a character in two different pieces of literature. As of 2019, much of the detailed knowledge of Ariel derives from a single flyby of Uranus performed by the space probeVoyager 2 in 1986, which managed to image around 35% of the moon's surface. There are no active plans at present to return to study the moon in more detail, although various concepts such as a Uranus Orbiter and Probe have been proposed.
After Miranda, Ariel is the second-closest of Uranus's five major rounded satellites. Among the smallest of the Solar System's 19 known spherical moons (it ranks 14th among them in diameter), it is believed to be composed of roughly equal parts ice and rocky material. Its mass is approximately equal in magnitude to Earth's hydrosphere.
Like all of Uranus's moons, Ariel probably formed from an accretion disc that surrounded the planet shortly after its formation, and, like other large moons, it is likely differentiated, with an inner core of rock surrounded by a mantle of ice. Ariel has a complex surface consisting of extensive cratered terrain cross-cut by a system of scarps, canyons, grabens and ridges. The surface shows signs of more recent geological activity than other Uranian moons, most likely due to tidal heating.
Discovery and name
Both Ariel and the slightly larger Uranian satellite Umbriel were discovered by William Lassell on 24 October 1851.[11][12] Although William Herschel, who discovered Uranus's two largest moons Titania and Oberon in 1787, claimed to have observed four additional moons,[13] this was never confirmed and those four objects are now thought to be spurious.[14][15][16]
Planetary moons other than Earth's were never given symbols in the astronomical literature. Denis Moskowitz, a software engineer who designed most of the dwarf planet symbols, proposed an A (the initial of Ariel) combined with the low globe of Jérôme Lalande's Uranus symbol as the symbol of Ariel (). This symbol is not widely used.[21]
Orbit
Among Uranus's five major moons, Ariel is the second closest to the planet, orbiting at the distance of about 190,000km.[g] Its orbit has a small eccentricity and is inclined very little relative to the equator of Uranus.[3] Its orbital period is around 2.5Earth days, coincident with its rotational period. This means that one side of the moon always faces the planet; a condition known as tidal lock.[22] Ariel's orbit lies completely inside the Uranian magnetosphere.[8] The trailing hemispheres (those facing away from their directions of orbit) of airless satellites orbiting inside a magnetosphere like Ariel are struck by magnetospheric plasma co-rotating with the planet.[23] This bombardment may lead to the darkening of the trailing hemispheres observed for all Uranian moons except Oberon (see below).[8] Ariel also captures magnetospheric charged particles, producing a pronounced dip in energetic particle count near the moon's orbit observed by Voyager 2 in 1986.[24]
Because Ariel, like Uranus, orbits the Sunalmost on its side relative to its rotation, its northern and southern hemispheres face either directly towards or directly away from the Sun at the solstices. This means it is subject to an extreme seasonal cycle; just as Earth's poles see permanent night or daylight around the solstices, Ariel's poles see permanent night or daylight for half a Uranian year (42 Earth years), with the Sun rising close to the zenith over one of the poles at each solstice.[8] The Voyager 2 flyby coincided with the 1986 southern summer solstice, when nearly the entire northern hemisphere was dark. Once every 42 years, when Uranus has an equinox and its equatorial plane intersects the Earth, mutual occultations of Uranus's moons become possible. A number of such events occurred in 2007–2008, including an occultation of Ariel by Umbriel on 19 August 2007.[25]
Currently Ariel is not involved in any orbital resonance with other Uranian satellites. In the past, however, it may have been in a 5:3 resonance with Miranda, which could have been partially responsible for the heating of that moon (although the maximum heating attributable to a former 1:3 resonance of Umbriel with Miranda was likely about three times greater).[26] Ariel may have once been locked in the 4:1 resonance with Titania, from which it later escaped.[27] Escape from a mean motion resonance is much easier for the moons of Uranus than for those of Jupiter or Saturn, due to Uranus's lesser degree of oblateness.[27] This resonance, which was likely encountered about 3.8billion years ago, would have increased Ariel's orbital eccentricity, resulting in tidal friction due to time-varying tidal forces from Uranus. This would have caused warming of the moon's interior by as much as 20K.[27]
Ariel is the fourth-largest of the Uranian moons by size and mass. It is also the 14th-largest moon in the Solar System. The moon's density is 1.52g/cm3, which indicates that it consists of roughly equal parts water ice and a dense non-ice component.[28] The latter could consist of rock and carbonaceous material including heavy organic compounds known as tholins.[22] The presence of water ice is supported by infraredspectroscopic observations, which have revealed crystalline water ice on the surface of the moon, which is porous and thus transmits little solar heat to layers below.[8][29] Water ice absorption bands are stronger on Ariel's leading hemisphere than on its trailing hemisphere.[8] The cause of this asymmetry is not known, but it may be related to bombardment by charged particles from Uranus's magnetosphere, which is stronger on the trailing hemisphere (due to the plasma's co-rotation).[8] The energetic particles tend to sputter water ice, decompose methane trapped in ice as clathrate hydrate and darken other organics, leaving a dark, carbon-rich residue behind.[8]
Except for water, two other compounds have been identified on the surface of Ariel by infrared spectroscopy. The first is carbon dioxide (CO2), which is concentrated mainly on its trailing hemisphere. Ariel shows the strongest spectroscopic evidence for CO2 of any Uranian satellite,[8] and was the first Uranian satellite on which this compound was discovered.[8] The origin of the carbon dioxide is not completely clear. It might be produced locally from carbonates or organic materials under the influence of the energetic charged particles coming from Uranus's magnetosphere or solar ultraviolet radiation. This hypothesis would explain the asymmetry in its distribution, as the trailing hemisphere is subject to a more intense magnetospheric influence than the leading hemisphere. Another possible source is the outgassing of primordial CO2 trapped by water ice in Ariel's interior. The escape of CO2 from the interior may be related to past geological activity on this moon.[8]
The second compound identified by its feature at wavelength of 2.2μm on Ariel is ammonia, which is distributed more or less homogeneously over the surface. The presence of ammonia may indicate that Ariel was geologically active in recent past.[30]
Given its size, rock/ice composition and the possible presence of salt or ammonia in solution to lower the freezing point of water, Ariel's interior may be differentiated into a rocky core surrounded by an icy mantle.[28] If this is the case, the radius of the core (372km) is about 64% of the radius of the moon, and its mass is around 56% of the moon's mass—the parameters are dictated by the moon's composition. The pressure in the center of Ariel is about 0.3GPa (3kbar).[28] The current state of the icy mantle is unclear. The existence of a subsurface ocean is currently considered possible,[31] though a 2006 study suggests that radiogenic heating alone would not be enough to allow for one.[28] More scientific research concluded that an active underwater ocean is possible for the 4 largest moons of Uranus.[32][33][34]
In April 2025, a published study attempted to constrain the actual depth of Ariel's possible subsurface ocean using clues gleaned from all the visible fractures and grabens on Ariel's surface, as well as clues from Ariel's inferred past orbital eccentricity. The study claimed that in the past, Ariel's orbital eccentricity could have been as high as 0.04, causing extreme tidal stresses that provided the heat necessary to maintain Ariel's subsurface ocean in a liquid state. The study also pointed out the fact that volatile materials, particularly ammonia, were tentatively detected on Ariel. Since these compounds dissipate rapidly in space and are easily broken down by interaction with Uranus' magnetic field, they consider it as an indication that something is replenishing them on Ariel, suggesting that the moon's subsurface ocean was still active in the recent past. The study concluded that Ariel's subsurface ocean might have been as deep as 170km (110mi).[35]
Surface
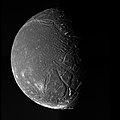
The highest-resolution Voyager 2 color image of Ariel. Canyons with floors covered by smooth plains are visible at lower right. The bright crater Laica is at lower left.
Albedo and color
Ariel is the most reflective of Uranus's moons.[7] Its surface shows an opposition surge: the reflectivity decreases from 53% at a phase angle of 0° (geometrical albedo) to 35% at an angle of about 1°. The Bond albedo of Ariel is about 23%—the highest among Uranian satellites.[7] The surface of Ariel is generally neutral in color.[36] There may be an asymmetry between the leading and trailing hemispheres;[37] the latter appears to be redder than the former by 2%.[h] Ariel's surface generally does not demonstrate any correlation between albedo and geology on one hand and color on the other hand. For instance, canyons have the same color as the cratered terrain. However, bright impact deposits around some fresh craters are slightly bluer in color.[36][37] There are also some slightly blue spots, which do not correspond to any known surface features.[37]
Possible geological activity
In February 2025, planetary scientists at Johns Hopkins University published their findings on the possibility that Ariel might be geologically active using images taken by Voyager 2 back in 1986. According to the study, the numerous grooves and grabens running across Ariel's surface might be the result of liquid water oozing out from the moon's possible subsurface ocean. As the liquid water flows out, it pushes aside the solid icy surface of the moon, splitting apart Ariel's surface similar to how lava flowing out of the Earth's mantle pushes apart the oceanic crust on Earth's Mid-Atlantic Ridge; but instead of lava, it is liquid water for Ariel. The freshly ejected water then freezes once it reaches the surface, creating a new icy crust and the cycle of splitting apart the crust and generating fresh crust continues. If this study's conclusions are correct, then the fresh materials at the center of the grooves and gravens might be exposed samples of what a subsurface ocean might contain, making them attractive places to study and even get samples from to learn more about the nature of subsurface oceans. The study suggests that the grooves are good sources of carbon oxides samples.[38]
The observed surface of Ariel can be divided into three terrain types: cratered terrain, ridged terrain, and plains.[39] The main surface features are impact craters, canyons, fault scarps, ridges, and troughs.[40]
Graben (chasmata) near Ariel's terminator. Their floors are covered by smooth material, possibly extruded from beneath via cryovolcanism. Several are cut by sinuous central grooves, e.g. Sprite and Leprechaun valles above and below the triangular horst near the bottom.
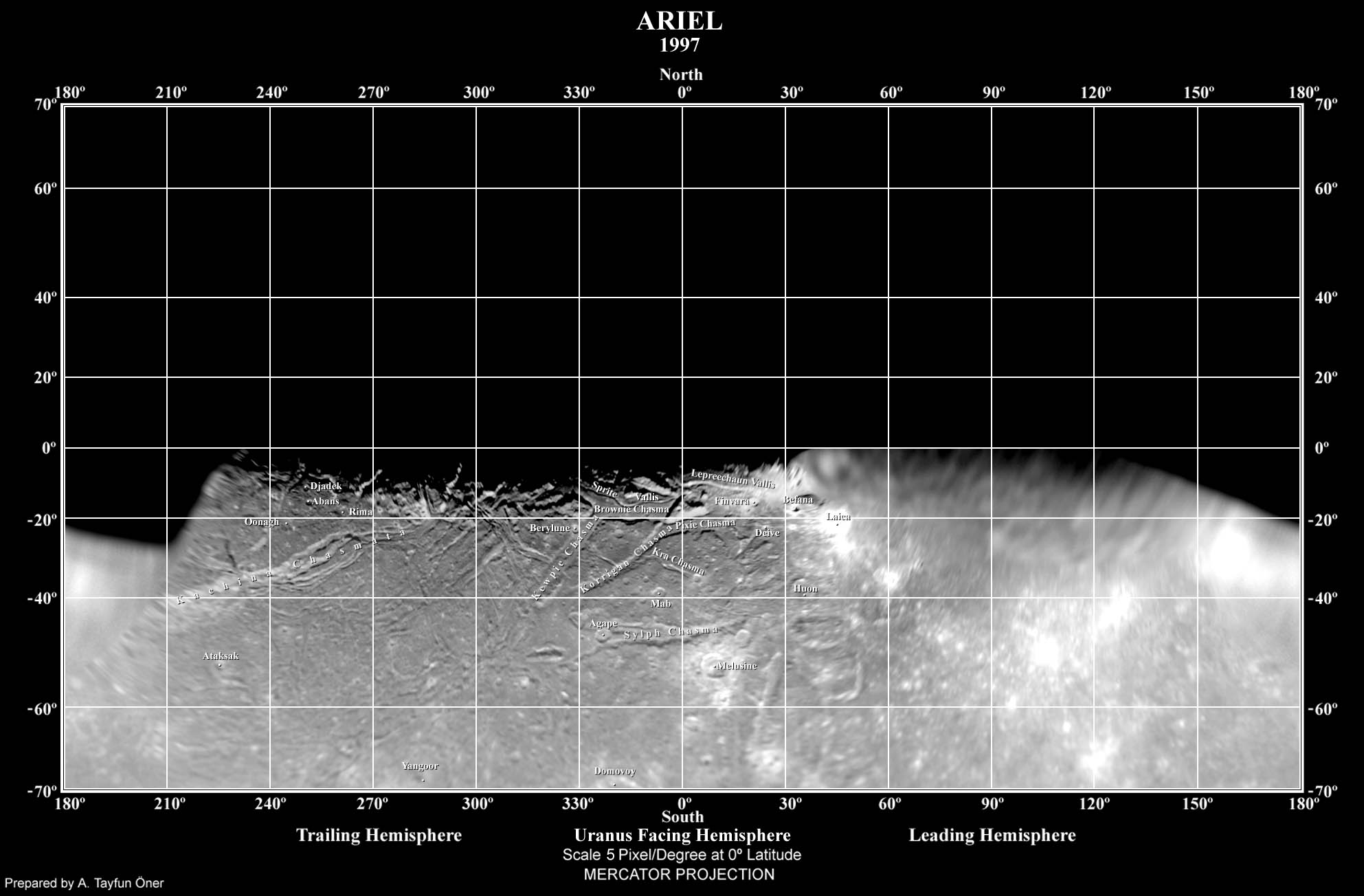
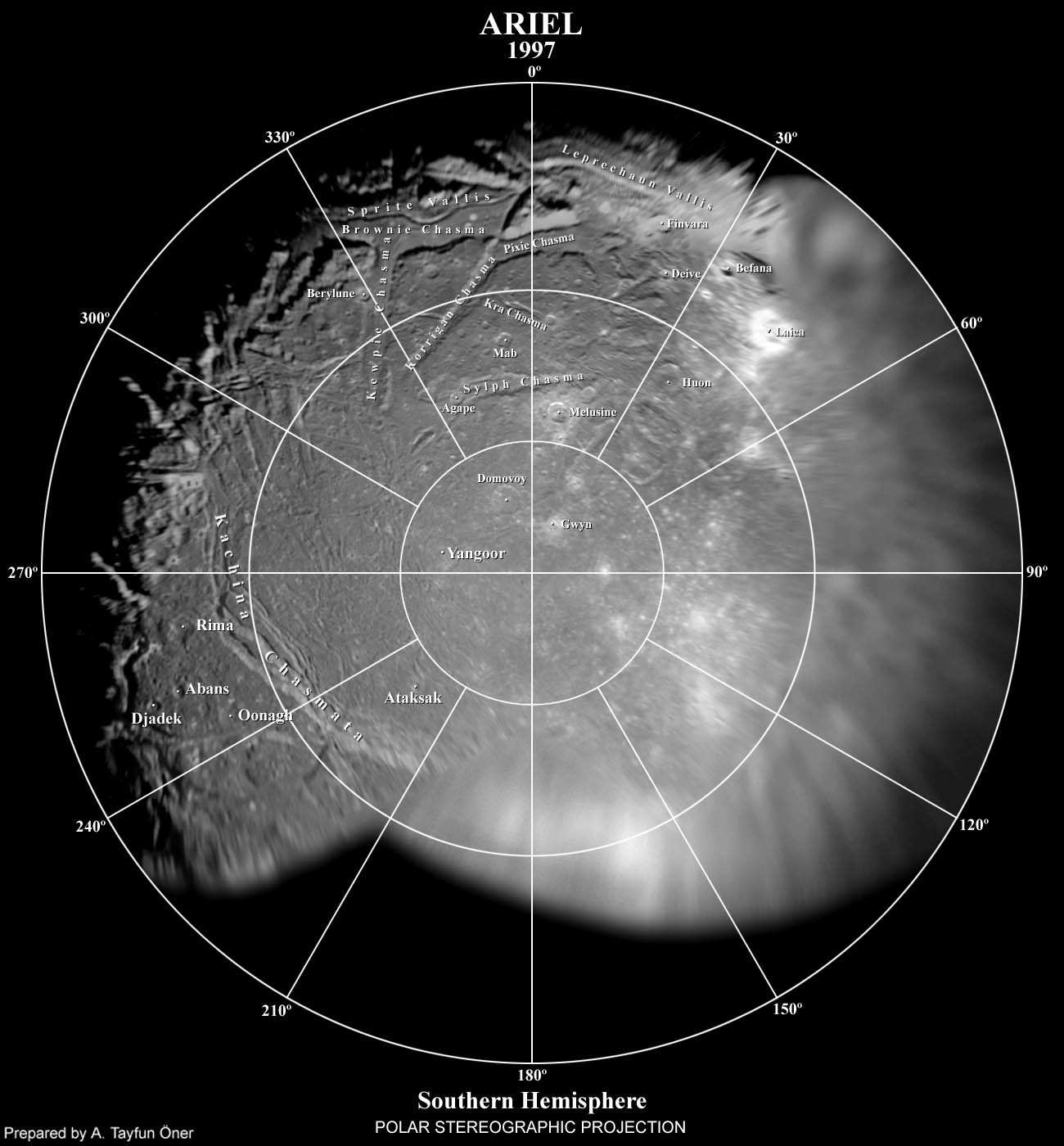
The cratered terrain, a rolling surface covered by numerous impact craters and centered on Ariel's south pole, is the moon's oldest and most geographically extensive geological unit.[39] It is intersected by a network of scarps, canyons (graben), and narrow ridges mainly occurring in Ariel's mid-southern latitudes.[39] The canyons, known as chasmata,[41] probably represent graben formed by extensional faulting, which resulted from global tensional stresses caused by the freezing of water (or aqueous ammonia) in the moon's interior (see below).[22][39] They are 15–50km wide and trend mainly in an east- or northeasterly direction.[39] The floors of many canyons are convex; rising up by 1–2km.[41] Sometimes the floors are separated from the walls of canyons by grooves (troughs) about 1km wide.[41] The widest graben have grooves running along the crests of their convex floors, which are called valles.[22] The longest canyon is Kachina Chasma, at over 620km in length (the feature extends into the hemisphere of Ariel that Voyager 2 did not see illuminated).[40][42]
The second main terrain type—ridged terrain—comprises bands of ridges and troughs hundreds of kilometers in extent. It bounds the cratered terrain and cuts it into polygons. Within each band, which can be up to 25 to 70km wide, are individual ridges and troughs up to 200km long and between 10 and 35km apart. The bands of ridged terrain often form continuations of canyons, suggesting that they may be a modified form of the graben or the result of a different reaction of the crust to the same extensional stresses, such as brittle failure.[39]
False-color map of Ariel. The prominent noncircular crater below and left of center is Yangoor. Part of it was erased during formation of ridged terrain via extensional tectonics.
The youngest terrain observed on Ariel are the plains: relatively low-lying smooth areas that must have formed over a long period of time, judging by their varying levels of cratering.[39] The plains are found on the floors of canyons and in a few irregular depressions in the middle of the cratered terrain.[22] In the latter case they are separated from the cratered terrain by sharp boundaries, which in some cases have a lobate pattern.[39] The most likely origin for the plains is through volcanic processes; their linear vent geometry, resembling terrestrial shield volcanoes, and distinct topographic margins suggest that the erupted liquid was very viscous, possibly a supercooled water/ammonia solution, with solid ice volcanism also a possibility.[41] The thickness of these hypothetical cryolava flows is estimated at 1–3km.[41] The canyons must therefore have formed at a time when endogenic resurfacing was still taking place on Ariel.[39] A few of these areas appear to be less than 100million years old, suggesting that Ariel may still be geologically active in spite of its relatively small size and lack of current tidal heating.[43]
Ariel appears to be fairly evenly cratered compared to other moons of Uranus;[22] the relative paucity of large craters[i] suggests that its surface does not date to the Solar System's formation, which means that Ariel must have been completely resurfaced at some point of its history.[39] Ariel's past geologic activity is believed to have been driven by tidal heating at a time when its orbit was more eccentric than currently.[27] The largest crater observed on Ariel, Yangoor, is only 78km across,[40] and shows signs of subsequent deformation. All large craters on Ariel have flat floors and central peaks, and few of the craters are surrounded by bright ejecta deposits. Many craters are polygonal, indicating that their appearance was influenced by the preexisting crustal structure. In the cratered plains there are a few large (about 100km in diameter) light patches that may be degraded impact craters. If this is the case they would be similar to palimpsests on Jupiter's moon Ganymede.[39] It has been suggested that a circular depression 245km in diameter located at 10°S 30°E is a large, highly degraded impact structure.[45]
Origin and evolution
Ariel is thought to have formed from an accretion disc or subnebula; a disc of gas and dust that either existed around Uranus for some time after its formation or was created by the giant impact that most likely gave Uranus its large obliquity.[46] The precise composition of the subnebula is not known; however, the higher density of Uranian moons compared to the moons of Saturn indicates that it may have been relatively water-poor.[j][22] Significant amounts of carbon and nitrogen may have been present in the form of carbon monoxide (CO) and molecular nitrogen (N2), instead of methane and ammonia.[46] The moons that formed in such a subnebula would contain less water ice (with CO and N2 trapped as clathrate) and more rock, explaining the higher density.[22]
The accretion process probably lasted for several thousand years before the moon was fully formed.[46] Models suggest that impacts accompanying accretion caused heating of Ariel's outer layer, reaching a maximum temperature of around 195K at a depth of about 31km.[47] After the end of formation, the subsurface layer cooled, while the interior of Ariel heated due to decay of radioactive elements present in its rocks.[22] The cooling near-surface layer contracted, while the interior expanded. This caused strong extensional stresses in the moon's crust reaching estimates of 30 MPa, which may have led to cracking.[48] Some present-day scarps and canyons may be a result of this process,[39] which lasted for about 200million years.[48]
The initial accretional heating together with continued decay of radioactive elements and likely tidal heating may have led to melting of the ice if an antifreeze like ammonia (in the form of ammonia hydrate) or some salt was present.[47] The melting may have led to the separation of ice from rocks and formation of a rocky core surrounded by an icy mantle.[28] A layer of liquid water (ocean) rich in dissolved ammonia may have formed at the core–mantle boundary. The eutectic temperature of this mixture is 176K.[28] The ocean, however, is likely to have frozen long ago. The freezing of the water likely led to the expansion of the interior, which may have been responsible for the formation of the canyons and obliteration of the ancient surface.[39] The liquids from the ocean may have been able to erupt to the surface, flooding floors of canyons in the process known as cryovolcanism.[47] More recent analysis concluded that an active ocean is probable for the 4 largest moons of Uranus; specifically including Ariel.[33]
Thermal modeling of Saturn's moon Dione, which is similar to Ariel in size, density, and surface temperature, suggests that solid state convection could have lasted in Ariel's interior for billions of years, and that temperatures in excess of 173 K (the melting point of aqueous ammonia) may have persisted near its surface for several hundred million years after formation, and near a billion years closer to the core.[39]
HST image of Ariel transiting Uranus, complete with shadow
The apparent magnitude of Ariel is 14.8;[10] similar to that of Pluto near perihelion. However, while Pluto can be seen through a telescope of 30cm aperture,[49] Ariel, due to its proximity to Uranus's glare, is often not visible to telescopes of 40cm aperture.[50]
The only close-up images of Ariel were obtained by the Voyager 2 probe, which photographed the moon during its flyby of Uranus in January 1986. The closest approach of Voyager 2 to Ariel was 127,000km (79,000mi)—significantly less than the distances to all other Uranian moons except Miranda.[51] The best images of Ariel have a spatial resolution of about 2km.[39] They cover about 40% of the surface, but only 35% was photographed with the quality required for geological mapping and crater counting.[39] At the time of the flyby, the southern hemisphere of Ariel (like those of the other moons) was pointed towards the Sun, so the northern (dark) hemisphere could not be studied.[22] No other spacecraft has ever visited the Uranian system.[52] The possibility of sending the Cassini spacecraft to Uranus was evaluated during its mission extension planning phase.[53][failed verification] It would have taken about twenty years to get to the Uranian system after departing Saturn, and these plans were scrapped in favour of remaining at Saturn and eventually destroying the spacecraft in Saturn's atmosphere.[53]
Transits
On 26 July 2006, the Hubble Space Telescope captured a rare transit made by Ariel on Uranus, which cast a shadow that could be seen on the Uranian cloud tops. Such events are rare and only occur around equinoxes, as the moon's orbital plane about Uranus is tilted 98° to Uranus's orbital plane about the Sun.[54] Another transit, in 2008, was recorded by the European Southern Observatory.[55]
↑ Escape velocity derived from the mass m, the gravitational constantG and the radius r: √2Gm/r.
↑The five major moons are Miranda, Ariel, Umbriel, Titania and Oberon.
↑ The color is determined by the ratio of albedos viewed through the green (0.52–0.59μm) and violet (0.38–0.45μm) Voyager filters.[36][37]
↑ The surface density of craters larger than 30km in diameter ranges from 20 to 70 per million km2 on Ariel, whereas it is about 1800 for Oberon or Umbriel.[44]
↑ For instance, Tethys, a Saturnian moon, has the density of 0.97g/cm3, which means that it is more than 90% water.[8]
↑Krimigis, S. M.; Armstrong, T. P.; Axford, W. I.; Cheng, A. F.; Gloeckler, G.; Hamilton, D. C.; Keath, E. P.; Lanzerotti, L. J.; Mauk, B. H. (4 July 1986). "The Magnetosphere of Uranus: Hot Plasma and Radiation Environment". Science. 233 (4759): 97–102. Bibcode:1986Sci...233...97K. doi:10.1126/science.233.4759.97. PMID17812897. S2CID46166768.
↑Tittemore, William C.; Wisdom, Jack (June 1990). "Tidal evolution of the Uranian satellites: III. Evolution through the Miranda-Umbriel 3:1, Miranda-Ariel 5:3, and Ariel-Umbriel 2:1 mean-motion commensurabilities". Icarus. 85 (2): 394–443. Bibcode:1990Icar...85..394T. doi:10.1016/0019-1035(90)90125-S. hdl:1721.1/57632.
123Bell, J. F. III; McCord, T. B. (1991). A search for spectral units on the Uranian satellites using color ratio images. Lunar and Planetary Science Conference, 21st, Mar. 12–16, 1990 (Conference Proceedings). Houston, TX, United States: Lunar and Planetary Sciences Institute. pp.473–489. Bibcode:1991LPSC...21..473B.
12345Schenk, P. M. (1991). "Fluid Volcanism on Miranda and Ariel: Flow Morphology and Composition". Journal of Geophysical Research. 96: 1887. Bibcode:1991JGR....96.1887S. doi:10.1029/90JB01604. (See pages 1893–1896)
↑Plescia, J. B. (1987). "Geology and Cratering History of Ariel". Abstracts of the Lunar and Planetary Science Conference. 18: 788. Bibcode:1987LPI....18..788P.
12Hillier, John; Squyres, Steven W. (August 1991). "Thermal stress tectonics on the satellites of Saturn and Uranus". Journal of Geophysical Research. 96 (E1): 15, 665–15, 674. Bibcode:1991JGR....9615665H. doi:10.1029/91JE01401.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.











{kind=link}
{kind=link}
{kind=link}