Related Research Articles

Artificial neural networks are a branch of machine learning models that are built using principles of neuronal organization discovered by connectionism in the biological neural networks constituting animal brains.
A recurrent neural network (RNN) is one of the two broad types of artificial neural network, characterized by direction of the flow of information between its layers. In contrast to the uni-directional feedforward neural network, it is a bi-directional artificial neural network, meaning that it allows the output from some nodes to affect subsequent input to the same nodes. Their ability to use internal state (memory) to process arbitrary sequences of inputs makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. The term "recurrent neural network" is used to refer to the class of networks with an infinite impulse response, whereas "convolutional neural network" refers to the class of finite impulse response. Both classes of networks exhibit temporal dynamic behavior. A finite impulse recurrent network is a directed acyclic graph that can be unrolled and replaced with a strictly feedforward neural network, while an infinite impulse recurrent network is a directed cyclic graph that can not be unrolled.

Spiking neural networks (SNNs) are artificial neural networks that more closely mimic natural neural networks. In addition to neuronal and synaptic state, SNNs incorporate the concept of time into their operating model. The idea is that neurons in the SNN do not transmit information at each propagation cycle, but rather transmit information only when a membrane potential—an intrinsic quality of the neuron related to its membrane electrical charge—reaches a specific value, called the threshold. When the membrane potential reaches the threshold, the neuron fires, and generates a signal that travels to other neurons which, in turn, increase or decrease their potentials in response to this signal. A neuron model that fires at the moment of threshold crossing is also called a spiking neuron model.
Reservoir computing is a framework for computation derived from recurrent neural network theory that maps input signals into higher dimensional computational spaces through the dynamics of a fixed, non-linear system called a reservoir. After the input signal is fed into the reservoir, which is treated as a "black box," a simple readout mechanism is trained to read the state of the reservoir and map it to the desired output. The first key benefit of this framework is that training is performed only at the readout stage, as the reservoir dynamics are fixed. The second is that the computational power of naturally available systems, both classical and quantum mechanical, can be used to reduce the effective computational cost.

Long short-term memory (LSTM) network is a recurrent neural network (RNN), aimed to deal with the vanishing gradient problem present in traditional RNNs. Its relative insensitivity to gap length is its advantage over other RNNs, hidden Markov models and other sequence learning methods. It aims to provide a short-term memory for RNN that can last thousands of timesteps, thus "long short-term memory". It is applicable to classification, processing and predicting data based on time series, such as in handwriting, speech recognition, machine translation, speech activity detection, robot control, video games, and healthcare.
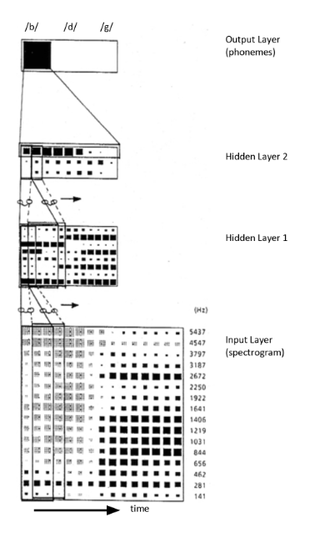
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
There are many types of artificial neural networks (ANN).

Deep learning is the subset of machine learning methods based on artificial neural networks with representation learning. The adjective "deep" refers to the use of multiple layers in the network. Methods used can be either supervised, semi-supervised or unsupervised.
Convolutional neural network (CNN) is a regularized type of feed-forward neural network that learns feature engineering by itself via filters optimization. Vanishing gradients and exploding gradients, seen during backpropagation in earlier neural networks, are prevented by using regularized weights over fewer connections. For example, for each neuron in the fully-connected layer 10,000 weights would be required for processing an image sized 100 × 100 pixels. However, applying cascaded convolution kernels, only 25 neurons are required to process 5x5-sized tiles. Higher-layer features are extracted from wider context windows, compared to lower-layer features.
A context model defines how context data are structured and maintained. It aims to produce a formal or semi-formal description of the context information that is present in a context-aware system. In other words, the context is the surrounding element for the system, and a model provides the mathematical interface and a behavioral description of the surrounding environment.
Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.

In artificial intelligence, a differentiable neural computer (DNC) is a memory augmented neural network architecture (MANN), which is typically recurrent in its implementation. The model was published in 2016 by Alex Graves et al. of DeepMind.

A Residual Neural Network is a deep learning model in which the weight layers learn residual functions with reference to the layer inputs. A Residual Network is a network with skip connections that perform identity mappings, merged with the layer outputs by addition. It behaves like a Highway Network whose gates are opened through strongly positive bias weights. This enables deep learning models with tens or hundreds of layers to train easily and approach better accuracy when going deeper. The identity skip connections, often referred to as "residual connections", are also used in the 1997 LSTM networks, Transformer models, the AlphaGo Zero system, the AlphaStar system, and the AlphaFold system.
Neural architecture search (NAS) is a technique for automating the design of artificial neural networks (ANN), a widely used model in the field of machine learning. NAS has been used to design networks that are on par or outperform hand-designed architectures. Methods for NAS can be categorized according to the search space, search strategy and performance estimation strategy used:

A transformer is a deep learning architecture based on the multi-head attention mechanism. It is notable for not containing any recurrent units, and thus requires less training time than previous recurrent neural architectures, such as long short-term memory (LSTM), and its later variation has been prevalently adopted for training large language models on large (language) datasets, such as the Wikipedia corpus and Common Crawl. Input text is split into n-grams encoded as tokens and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished. Though the transformer paper was published in 2017, the softmax-based attention mechanism was proposed in 2014 for machine translation, and the Fast Weight Controller, similar to a transformer, was proposed in 1992.
LeNet is a convolutional neural network structure proposed by LeCun et al. in 1998. In general, LeNet refers to LeNet-5 and is a simple convolutional neural network. Convolutional neural networks are a kind of feed-forward neural network whose artificial neurons can respond to a part of the surrounding cells in the coverage range and perform well in large-scale image processing.
A deep learning processor (DLP), or a deep learning accelerator, is an electronic circuit designed for deep learning algorithms, usually with separate data memory and dedicated instruction set architecture. Deep learning processors range from mobile devices, such as neural processing units (NPUs) in Apple iPhones or Huawei cellphones, and personal computers such as Apple silicon Macs, to cloud computing servers such as tensor processing units (TPU) in the Google Cloud Platform.

Video super-resolution (VSR) is the process of generating high-resolution video frames from the given low-resolution video frames. Unlike single-image super-resolution (SISR), the main goal is not only to restore more fine details while saving coarse ones, but also to preserve motion consistency.
A vision transformer (ViT) is a transformer designed for computer vision. A ViT breaks down an input image into a series of patches, serialises each patch into a vector, and maps it to a smaller dimension with a single matrix multiplication. These vector embeddings are then processed by a transformer encoder as if they were token embeddings.
References
- 1 2 3 4 5 6 7 Gu, Albert; Dao, Tri. "Mamba: Linear-Time Sequence Modeling with Selective State Spaces". arXiv: 2312.00752 .
- ↑ Chowdhury, Hasan. "The tech powering ChatGPT won't make AI as smart as humans. Others might". Business Insider. Retrieved 13 January 2024.
- ↑ Pandey, Mohit (6 December 2023). "Mamba is Here to Mark the End of Transformers". Analytics India Magazine. Retrieved 13 January 2024.
- ↑ Gu, Albert; Goel, Karan; Re, Christopher (6 October 2021). "Efficiently Modeling Long Sequences with Structured State Spaces". ICLR. Retrieved 13 January 2024.
- ↑ Gu, Albert; Johnson, Isys; Goel, Karan; Saab, Khaled Kamal; Dao, Tri; Rudra, A.; R'e, Christopher (26 October 2021). "Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers". NeurIPS. Retrieved 13 January 2024.
- 1 2 Tickoo, Aneesh (10 December 2023). "Researchers from CMU and Princeton Unveil Mamba: A Breakthrough SSM Architecture Exceeding Transformer Efficiency for Multimodal Deep Learning Applications". MarkTechPost. Retrieved 13 January 2024.
- ↑ Pióro, Maciej; Ciebiera, Kamil; Król, Krystian; Ludziejewski, Jan; Jaszczur, Sebastian. "MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts". arXiv: 2401.04081 .
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General | |||||||
| Concepts | |||||||
| Applications | |||||||
| Hardware | |||||||
| Software libraries | |||||||
| Implementations |
| ||||||
| People | |||||||
| Organizations | |||||||
| Architectures |
| ||||||
| |||||||