A transformer is a deep learning architecture based on the multi-head attention mechanism.[1] It is notable for not containing any recurrent units, and thus requires less training time than previous recurrent neural architectures, such as long short-term memory (LSTM),[2] and its later variation has been prevalently adopted for training large language models on large (language) datasets, such as the Wikipediacorpus and Common Crawl.[3] Input text is split into n-grams encoded as tokens and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished. Though the transformer paper was published in 2017, the softmax-based attention mechanism was proposed in 2014 for machine translation,[4][5] and the Fast Weight Controller, similar to a transformer, was proposed in 1992.[6][7][8]
In 1990, the Elman network, using a recurrent neural network, encoded each word in a training set as a vector, called a word embedding, and the whole vocabulary as a vector database, allowing it to perform such tasks as sequence-predictions that are beyond the power of a simple multilayer perceptron. A shortcoming of the static embeddings was that they didn't differentiate between multiple meanings of same-spelt words.[13]
In 1992, the Fast Weight Controller was published by Jürgen Schmidhuber.[6] It learns to answer queries by programming the attention weights of another neural network through outer products of key vectors and value vectors called FROM and TO. The Fast Weight Controller was later shown to be equivalent to the unnormalized linear Transformer.[8][7][14][15] The terminology "learning internal spotlights of attention" was introduced in 1993.[16]
In 2001, a one-billion-word large text corpus, scraped from the Internet, referred to as "very very large" at the time, was used for word disambiguation.[18]
In 2012, AlexNet demonstrated the effectiveness of large neural networks for image recognition, encouraging large artificial neural networks approach instead of older, statistical approaches.
In 2014, a 380M-parameter seq2seq model for machine translation using two LSTMs networks was proposed by Sutskever at al.[19] The architecture consists of two parts. The encoder is an LSTM that takes in a sequence of tokens and turns it into a vector. The decoder is another LSTM that converts the vector into a sequence of tokens.
In 2014, gating proved to be useful in a 130M-parameter seq2seq model, which used a simplified gated recurrent units (GRUs). Bahdanau et al[20] showed that GRUs are neither better nor worse than gated LSTMs.[21][22]
In 2014, Bahdanau et al.[23] improved the previous seq2seq model by using an "additive" kind of attention mechanism in-between two LSTM networks. It was, however, not yet the parallelizable (scaled "dot product") kind of attention, later proposed in the 2017 transformer paper.
In 2015, the relative performance of Global and Local (windowed) attention model architectures were assessed by Luong et al, a mixed attention architecture found to improve on the translations offered by Bahdanau's architecture, while the use of a local attention architecture reduced translation time. [24]
In 2016, Google Translate gradually replaced the older statistical machine translation approach with the newer neural-networks-based approach that included a seq2seq model combined by LSTM and the "additive" kind of attention mechanism. They achieved a higher level of performance than the statistical approach, which took ten years to develop, in only nine months.[25][26]
In 2017, the original (100M-sized) encoder-decoder transformer model with a faster (parallelizable or decomposable) attention mechanism was proposed in the "Attention is all you need" paper. As the model had difficulties converging, it was suggested that the learning rate should be linearly scaled up from 0 to maximal value for the first part of the training (i.e. 2% of the total number of training steps). The intent of the transformer model is to take a seq2seq model and remove its recurrent neural networks, but preserve its additive attention mechanism.[1]
In 2018, in the ELMo paper, an entire sentence was processed before an embedding vector was assigning to each word in the sentence. A bi-directional LSTM was used to calculate such, deep contextualized embeddings for each word, improving upon the line of research from bag of words and word2vec.
In 2018, an encoder-only transformer was used in the (more than 1B-sized) BERT model, improving upon ELMo.[27]
In 2020, difficulties with converging the original transformer were solved by normalizing layers before (instead of after) multiheaded attention by Xiong et al. This is called pre-LN Transformer.[30]
In 2023, uni-directional ("autoregressive") transformers were being used in the (more than 100B-sized) GPT-3 and other OpenAIGPT models.[31][32]
Predecessors
Before transformers, predecessors of attention mechanism were added to gated recurrent neural networks, such as LSTMs and gated recurrent units (GRUs), which processed datasets sequentially. Dependency on previous token computations prevented them from being able to parallelize the attention mechanism. In 1992, fast weight controller was proposed as an alternative to recurrent neural networks that can learn "internal spotlights of attention".[16][6] In theory, the information from one token can propagate arbitrarily far down the sequence, but in practice the vanishing-gradient problem leaves the model's state at the end of a long sentence without precise, extractable information about preceding tokens.
The performance of old models was enhanced by adding an attention mechanism, which allowed a model to access any preceding point along the sequence. The attention layer weighs all previous states according to a learned measure of relevance, providing relevant information about far-away tokens. This proved to be especially useful in language translation, where far-away context can be essential for the meaning of a word in a sentence. The state vector has been accessible only after the last English word was processed while, for example, translating it from French by a LSTM model. Although in theory such a vector retains the information about the whole original sentence, in practice the information is poorly preserved. If an attention mechanism is added, the decoder is given access to the state vectors of every input word, not just the last, and can learn attention weights that dictate how much to attend to each input state vector. The augmentation of seq2seq models with the attention mechanism was first implemented in the context of machine translation by Bahdanau, Cho, and Bengio in 2014.[4][5]
Decomposable attention
In 2016, highly parallelizable decomposable attention was successfully combined with a feedforward network.[33] This indicated that attention mechanisms were powerful in themselves and that sequential recurrent processing of data was not necessary to achieve the quality gains of recurrent neural networks with attention. In 2017, Vaswani et al. also proposed replacing recurrent neural networks with self-attention and started the effort to evaluate that idea.[1] Transformers, using an attention mechanism, processing all tokens simultaneously, calculated "soft" weights between them in successive layers. Since the attention mechanism only uses information about other tokens from lower layers, it can be computed for all tokens in parallel, which leads to improved training speed.
Training
Methods for stabilizing training
The plain transformer architecture had difficulty converging. In the original paper[1] the authors recommended using learning rate warmup. That is, the learning rate should linearly scale up from 0 to maximal value for the first part of the training (usually recommended to be 2% of the total number of training steps), before decaying again.
A 2020 paper found that using layer normalizationbefore (instead of after) multiheaded attention and feedforward layers stabilizes training, not requiring learning rate warmup.[30]
The GT3 model integrates CWTE, SWTE, and TTE using a self-adaptive gate layer, enabling efficient and effective fusion of three types of features for end-to-end text-driven stock market prediction.[34]
Pretrain-finetune
Transformers typically undergo self-supervised learning involving unsupervised pretraining followed by supervised fine-tuning. Pretraining is typically done on a larger dataset than fine-tuning, due to the limited availability of labeled training data. Tasks for pretraining and fine-tuning commonly include:
In addition to the NLP applications, it has also been successful in other fields, such as computer vision, or the protein folding applications (such as AlphaFold).
As an illustrative example, Ithaca is an encoder-only transformer with three output heads. It takes as input ancient Greek inscription as sequences of characters, but with illegible characters replaced with "-". Its three output heads respectively outputs probability distributions over Greek characters, location of inscription, and date of inscription.[37]
Implementations
The transformer model has been implemented in standard deep learning frameworks such as TensorFlow and PyTorch.
Transformers is a library produced by Hugging Face that supplies transformer-based architectures and pretrained models.[11]
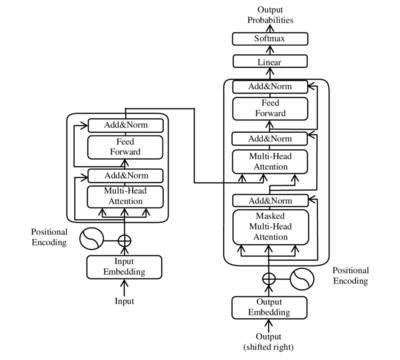
Architecture
An illustration of main components of the transformer model from the original paper, where layers were normalized after (instead of before) multiheaded attention.
All transformers have the same primary components:
Tokenizers, which convert text into tokens.
A single embedding layer, which converts tokens and positions of the tokens into vector representations.
Transformer layers, which carry out repeated transformations on the vector representations, extracting more and more linguistic information. These consist of alternating attention and feedforward layers.
(optional) Un-embedding layer, which converts the final vector representations back to a probability distribution over the tokens.
Transformer layers can be one of two types, encoder and decoder. In the original paper both of them were used, while later models included only one type of them. BERT is an example of an encoder-only model; GPT are decoder-only models.
Input
The input text is parsed into tokens by a tokenizer, most often a byte pair encodingtokenizer, and each token is converted into a vector via looking up from a word embedding table. Then, positional information of the token is added to the word embedding.
Encoder-decoder architecture
Like earlier seq2seq models, the original transformer model used an encoder-decoder architecture. The encoder consists of encoding layers that process the input tokens iteratively one layer after another, while the decoder consists of decoding layers that iteratively process the encoder's output as well as the decoder output's tokens so far.
The function of each encoder layer is to generate contextualized token representations, where each representation corresponds to a token that "mixes" information from other input tokens via self-attention mechanism. Each decoder layer contains two attention sublayers: (1) cross-attention for incorporating the output of encoder (contextualized input token representations), and (2) self-attention for "mixing" information among the input tokens to the decoder (i.e., the tokens generated so far during inference time).[38][39]
Both the encoder and decoder layers have a feed-forward neural network for additional processing of the outputs and contain residual connections and layer normalization steps.[39]
Scaled dot-product attention
The transformer building blocks are scaled dot-productattention units. For each attention unit, the transformer model learns three weight matrices: the query weights , the key weights , and the value weights . For each token , the input token representation is multiplied with each of the three weight matrices to produce a query vector , a key vector , and a value vector . Attention weights are calculated using the query and key vectors: the attention weight from token to token is the dot product between and . The attention weights are divided by the square root of the dimension of the key vectors, , which stabilizes gradients during training, and passed through a softmax which normalizes the weights. The fact that and are different matrices allows attention to be non-symmetric: if token attends to token (i.e. is large), this does not necessarily mean that token will attend to token (i.e. could be small). The output of the attention unit for token is the weighted sum of the value vectors of all tokens, weighted by , the attention from token to each token.
The attention calculation for all tokens can be expressed as one large matrix calculation using the softmax function, which is useful for training due to computational matrix operation optimizations that quickly compute matrix operations. The matrices , and are defined as the matrices where the th rows are vectors , , and respectively. Then we can represent the attention as
where softmax is taken over the horizontal axis.
Multi-head attention
One set of matrices is called an attention head, and each layer in a transformer model has multiple attention heads. While each attention head attends to the tokens that are relevant to each token, multiple attention heads allow the model to do this for different definitions of "relevance". In addition, the influence field representing relevance can become progressively dilated in successive layers. Many transformer attention heads encode relevance relations that are meaningful to humans. For example, some attention heads can attend mostly to the next word, while others mainly attend from verbs to their direct objects.[40] The computations for each attention head can be performed in parallel, which allows for fast processing. The outputs for the attention layer are concatenated to pass into the feed-forward neural network layers.
Concretely, let the multiple attention heads be indexed by , then we have
where the matrix is the concatenation of word embeddings, and the matrices are "projection matrices" owned by individual attention head , and is a final projection matrix owned by the whole multi-headed attention head.
Masked attention
It may be necessary to cut out attention links between some word-pairs. For example, the decoder for token position should not have access to token position . This may be accomplished before the softmax stage by adding a mask matrix that is at entries where the attention link must be cut, and at other places:
Encoder
Each encoder consists of two major components: a self-attention mechanism and a feed-forward neural network. The self-attention mechanism accepts input encodings from the previous encoder and weights their relevance to each other to generate output encodings. The feed-forward neural network further processes each output encoding individually. These output encodings are then passed to the next encoder as its input, as well as to the decoders.
The first encoder takes positional information and embeddings of the input sequence as its input, rather than encodings. The positional information is necessary for the transformer to make use of the order of the sequence, because no other part of the transformer makes use of this.[1]
The encoder is bidirectional. Attention can be placed on tokens before and after the current token. Tokens are used instead of words to account for polysemy.
A diagram of a sinusoidal positional encoding with parameters
Positional encoding
A positional encoding is a fixed-size vector representation that encapsulates the relative positions of tokens within a target sequence: it provides the transformer model with information about where the words are in the input sequence.
The positional encoding is defined as a function of type , where is a positive even integer. The full positional encoding – as defined in the original paper – is given by the equation:
where .
Here, is a free parameter that should be significantly larger than the biggest that would be input into the positional encoding function. In the original paper,[1] the authors chose .
The function is in a simpler form when written as a complex function of type
where . The main reason the authors chose this as the positional encoding function is that it allows one to perform shifts as linear transformations:
where is the distance one wishes to shift. This allows the transformer to take any encoded position, and find the encoding of the position n-steps-ahead or n-steps-behind, by a matrix multiplication. By taking a linear sum, any convolution can also be implemented as linear transformations:
for any constants . This allows the transformer to take any encoded position and find a linear sum of the encoded locations of its neighbors. This sum of encoded positions, when fed into the attention mechanism, would create attention weights on its neighbors, much like what happens in a convolutional neural networklanguage model. In the author's words, "we hypothesized it would allow the model to easily learn to attend by relative position".
Each decoder consists of three major components: a self-attention mechanism, an attention mechanism over the encodings, and a feed-forward neural network. The decoder functions in a similar fashion to the encoder, but an additional attention mechanism is inserted which instead draws relevant information from the encodings generated by the encoders. This mechanism can also be called the encoder-decoder attention.[1][39]
Like the first encoder, the first decoder takes positional information and embeddings of the output sequence as its input, rather than encodings. The transformer must not use the current or future output to predict an output, so the output sequence must be partially masked to prevent this reverse information flow.[1] This allows for autoregressive text generation. For all attention heads, attention can't be placed on following tokens. The last decoder is followed by a final linear transformation and softmax layer, to produce the output probabilities over the vocabulary.
All members of OpenAI's GPT series have a decoder-only architecture.
Terminology
In large language models, the terminology is somewhat different than the terminology used in the original Transformer paper:[41]
"encoder only": full encoder, full decoder.
"encoder-decoder": full encoder, autoregressive decoder.
Here "autoregressive" means that a mask is inserted in the attention head to zero out all attention from one token to all tokens following it, as described in the "masked attention" section.
Generally, Transformer-based language models are of two types: causal (or "autoregressive") and masked. The GPT series is causal and decoder only. BERT is masked and encoder only.[42][43] The T5 series is encoder-decoder, with a full encoder and autoregressive decoder.[35]
Subsequent work
Alternative activation functions
The original transformer uses ReLU activation function. Other activation functions were developed, such as SwiGLU.[44]
Alternative positional encodings
Transformers may use other positional encoding methods than sinusoidal.[45]
RoPE (rotary positional embedding),[46] is best explained by considering a list of 2-dimensional vectors . Now pick some angle . Then RoPE encoding is
Equivalently, if we write the 2-dimensional vectors as complex numbers , then RoPE encoding is just multiplication by an angle:
For a list of -dimensional vectors, a RoPE encoder is defined by a sequence of angles . Then the RoPE encoding is applied to each pair of coordinates.
The benefit of RoPE is that the dot-product between two vectors depends on their relative location only:
for any integer .
ALiBi (Attention with Linear Biases)[47] is not a replacement for the positional encoder on the original transformer. Instead, it is an additional positional encoder that is directly plugged into the attention mechanism. Specifically, the ALiBi attention mechanism is
Here, is a real number ("scalar"), and is the linear bias matrix defined by
in other words, .
ALiBi allows pretraining on short context windows, then finetuning on longer context windows. Since it is directly plugged into the attention mechanism, it can be combined with any positional encoder that is plugged into the "bottom" of the entire network (which is where the sinusoidal encoder on the original transformer, as well as RoPE and many others, are located).
Relative Position Encodings[48] is similar to ALiBi, but more generic:
FlashAttention[49] is an algorithm that implements the transformer attention mechanism efficiently on a GPU. It performs matrix multiplications in blocks, such that each block fits within the cache of a GPU, and by careful management of the blocks it minimizes data copying between GPU caches (as data movement is slow).
An improved version, FlashAttention-2,[50][51][52] was developed to cater to the rising demand for language models capable of handling longer context lengths. It offers enhancements in work partitioning and parallelism, enabling it to achieve up to 230 TFLOPs/s on A100 GPUs (FP16/BF16), a 2x speed increase over the original FlashAttention.
Key advancements in FlashAttention-2 include the reduction of non-matmul FLOPs, improved parallelism over the sequence length dimension, better work partitioning between GPU warps, and added support for head dimensions up to 256 and multi-query attention (MQA) and grouped-query attention (GQA).
Benchmarks revealed FlashAttention-2 to be up to 2x faster than FlashAttention and up to 9x faster than a standard attention implementation in PyTorch. Future developments include optimization for new hardware like H100 GPUs and new data types like FP8.
Multi-Query Attention
Multi-Query Attention changes the multiheaded attention mechanism.[53] Whereas normally,
with Multi-Query Attention, there is just one , thus:
This has a neutral effect on model quality and training speed, but increases inference speed.
Speculative decoding
Transformers are used in large language models for autoregressive sequence generation: generating a stream of text, one token at a time. However, in most settings, decoding from a language models is memory-bound, meaning that we have spare compute power available. Speculative decoding[54][55] uses this spare compute power by computing several tokens in parallel. Similarly to speculative execution in CPUs, future tokens are computed concurrently, by speculating on the value of previous tokens, and are later discarded if it turns out the speculation was incorrect.
Specifically, consider a transformer model like GPT-3 with a context window size of 512. To generate an entire context window autoregressively with greedy decoding, it must be run for 512 times, each time generating a token . However, if we had some educated guess for the values of these tokens, we could verify all of them in parallel, in one run of the model, by checking that each is indeed the token with the largest log-likelihood in the -th output.
In speculative decoding, a smaller model or some other simple heuristic is used to generate a few speculative tokens that are subsequently verified by the larger model. For example, suppose a small model generated four speculative tokens: . These tokens are run through the larger model, and only and are accepted. The same run of the large model already generated a new token to replace , and is completely discarded. The process then repeats (starting from the 4th token) until all tokens are generated.
For non-greedy decoding, similar ideas apply, except the speculative tokens are accepted or rejected stochastically, in a way that guarantees the final output distribution is the same as if speculative decoding was not used.[54][56]
Sub-quadratic transformers
Training transformer-based architectures can be expensive, especially for long inputs.[57] Alternative architectures include the Reformer (which reduces the computational load from to [57]), or models like ETC/BigBird (which can reduce it to )[58] where is the length of the sequence. This is done using locality-sensitive hashing and reversible layers.[59][60]
Ordinary transformers require a memory size that is quadratic in the size of the context window. Attention-free transformers[61] reduce this to a linear dependence while still retaining the advantages of a transformer by linking the key to the value.
Long Range Arena (2020)[62] is a standard benchmark for comparing the behavior of transformer architectures over long inputs.
where are independent samples from the normal distribution . This choice of parameters satisfy , or
Consequently, the one-headed attention, with one query, can be written as
where . Similarly for multiple queries, and for multiheaded attention. This approximation can be computed in linear time, as we can compute the matrix first, then multiply it with the query. In essence, we have managed to obtain a more precise version of
Performer (2022)[64] uses the same Random Feature Attention, but are first independently sampled from the normal distribution , then they are Gram-Schmidt processed.
Multimodality
Transformers can also be used/adapted for modalities (input or output) beyond just text, usually by finding a way to "tokenize" the modality.
Vision transformers[28] adapt the transformer to computer vision by breaking down input images as a series of patches, turning them into vectors, and treating them like tokens in a standard transformer.
Conformer[29] and later Whisper[65] follow the same pattern for speech recognition, first turning the speech signal into a spectrogram, which is then treated like an image, i.e. broken down into a series of patches, turned into vectors and treated like tokens in a standard transformer.
Perceivers by Andrew Jaegle et al. (2021)[66][67] can learn from large amounts of heterogeneous data.
Regarding image outputs, Peebles et al introduced a diffusion transformer (DiT) which facilitates use of the transformer architecture for diffusion-based image production.[68] Also, Google released a transformer-centric image generator called "Muse" based on parallel decoding and masked generative transformer technology.[69] (Transformers played a less-central role with prior image-producing technologies,[70] albeit still a significant one.[71])
See also
Perceiver– Machine learning algorithm for non-textual data
A language model is a probabilistic model of a natural language. In 1980, the first significant statistical language model was proposed, and during the decade IBM performed ‘Shannon-style’ experiments, in which potential sources for language modeling improvement were identified by observing and analyzing the performance of human subjects in predicting or correcting text.
The softmax function, also known as softargmax or normalized exponential function, converts a vector of K real numbers into a probability distribution of K possible outcomes. It is a generalization of the logistic function to multiple dimensions, and used in multinomial logistic regression. The softmax function is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes, based on Luce's choice axiom.
An autoencoder is a type of artificial neural network used to learn efficient codings of unlabeled data. An autoencoder learns two functions: an encoding function that transforms the input data, and a decoding function that recreates the input data from the encoded representation. The autoencoder learns an efficient representation (encoding) for a set of data, typically for dimensionality reduction.
In machine learning, feature learning or representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
Multimodal learning, in the context of machine learning, is a type of deep learning using a combination of various modalities of data, often arising in real-world applications. An example of multi-modal data is data that combines text with imaging data consisting of pixel intensities and annotation tags. As these modalities have fundamentally different statistical properties, combining them is non-trivial, which is why specialized modelling strategies and algorithms are required. The model is then trained to able to understand and work with multiple forms of data.
Word2vec is a technique in natural language processing (NLP) for obtaining vector representations of words. These vectors capture information about the meaning of the word and their usage in context. The word2vec algorithm estimates these representations by modeling text in a large corpus. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that they capture the semantic and syntactic qualities of words; as such, a simple mathematical function can indicate the level of semantic similarity between the words represented by those vectors.
Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.
Gated recurrent units (GRUs) are a gating mechanism in recurrent neural networks, introduced in 2014 by Kyunghyun Cho et al. The GRU is like a long short-term memory (LSTM) with a gating mechanism to input or forget certain features, but lacks a context vector or output gate, resulting in fewer parameters than LSTM. GRU's performance on certain tasks of polyphonic music modeling, speech signal modeling and natural language processing was found to be similar to that of LSTM. GRUs showed that gating is indeed helpful in general, and Bengio's team came to no concrete conclusion on which of the two gating units was better.
Mixture of experts (MoE) is a machine learning technique where multiple expert networks (learners) are used to divide a problem space into homogeneous regions. It differs from ensemble techniques in that for MoE, typically only one or a few expert models are run for each input, whereas in ensemble techniques, all models are run on every input.
A capsule neural network (CapsNet) is a machine learning system that is a type of artificial neural network (ANN) that can be used to better model hierarchical relationships. The approach is an attempt to more closely mimic biological neural organization.
Paraphrase or paraphrasing in computational linguistics is the natural language processing task of detecting and generating paraphrases. Applications of paraphrasing are varied including information retrieval, question answering, text summarization, and plagiarism detection. Paraphrasing is also useful in the evaluation of machine translation, as well as semantic parsing and generation of new samples to expand existing corpora.
Bidirectional Encoder Representations from Transformers (BERT) is a language model based on the transformer architecture, notable for its dramatic improvement over previous state of the art models. It was introduced in October 2018 by researchers at Google. A 2020 literature survey concluded that "in a little over a year, BERT has become a ubiquitous baseline in Natural Language Processing (NLP) experiments counting over 150 research publications analyzing and improving the model."
In machine learning, a variational autoencoder (VAE) is an artificial neural network architecture introduced by Diederik P. Kingma and Max Welling. It is part of the families of probabilistic graphical models and variational Bayesian methods.
Seq2seq is a family of machine learning approaches used for natural language processing. Applications include language translation, image captioning, conversational models, and text summarization. Seq2seq uses sequence transformation: it turns one sequence into another sequence.
A Neural Network Gaussian Process (NNGP) is a Gaussian process (GP) obtained as the limit of a certain type of sequence of neural networks. Specifically, a wide variety of network architectures converges to a GP in the infinitely wide limit, in the sense of distribution. The concept constitutes an intensional definition, i.e., a NNGP is just a GP, but distinguished by how it is obtained.
Machine learning-based attention is a mechanism which intuitively mimicks cognitive attention. It calculates "soft" weights for each word, more precisely for its embedding, in the context window. These weights can be computed either in parallel or sequentially. "Soft" weights can change during each runtime, in contrast to "hard" weights, which are (pre-)trained and fine-tuned and remain frozen afterwards.
A graph neural network (GNN) belongs to a class of artificial neural networks for processing data that can be represented as graphs.
A vision transformer (ViT) is a transformer designed for computer vision. A ViT breaks down an input image into a series of patches, serialises each patch into a vector, and maps it to a smaller dimension with a single matrix multiplication. These vector embeddings are then processed by a transformer encoder as if they were token embeddings.
Prompt engineering is the process of structuring text that can be interpreted and understood by a generative AI model. A prompt is natural language text describing the task that an AI should perform.
A large language model (LLM) is a language model notable for its ability to achieve general-purpose language generation. LLMs acquire these abilities by learning statistical relationships from text documents during a computationally intensive self-supervised and semi-supervised training process. LLMs are artificial neural networks typically built with a transformer-based architecture. Some recent implementations are based on alternative architectures such as recurrent neural network variants and Mamba.
References
1 2 3 4 5 6 7 8 9 10 Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N; Kaiser, Łukasz; Polosukhin, Illia (2017). "Attention is All you Need"(PDF). Advances in Neural Information Processing Systems. Curran Associates, Inc. 30.
↑ He, Cheng (31 December 2021). "Transformer in CV". Transformer in CV. Towards Data Science. Archived from the original on 16 April 2023. Retrieved 19 June 2021.
1 2 Schmidhuber, Jürgen (1993). "Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets". ICANN 1993. Springer. pp.460–463.
↑ Brown, Peter F. (1993). "The mathematics of statistical machine translation: Parameter estimation". Computational Linguistics (19): 263–311.
↑ Wu, Yonghui; etal. (2016-09-01). "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation". arXiv:1609.08144 [cs.CL].
↑ Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina (11 October 2018). "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding". arXiv:1810.04805v2 [cs.CL].
1 2 Dosovitskiy, Alexey; Beyer, Lucas; Kolesnikov, Alexander; Weissenborn, Dirk; Zhai, Xiaohua; Unterthiner, Thomas; Dehghani, Mostafa; Minderer, Matthias; Heigold, Georg; Gelly, Sylvain; Uszkoreit, Jakob (2021-06-03). "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale". arXiv:2010.11929 [cs.CV].
↑ Clark, Kevin; Khandelwal, Urvashi; Levy, Omer; Manning, Christopher D. (August 2019). "What Does BERT Look at? An Analysis of BERT's Attention". Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Florence, Italy: Association for Computational Linguistics: 276–286. arXiv:1906.04341. doi:10.18653/v1/W19-4828. Archived from the original on 2020-10-21. Retrieved 2020-05-20.
↑ Chen, Charlie; Borgeaud, Sebastian; Irving, Geoffrey; Lespiau, Jean-Baptiste; Sifre, Laurent; Jumper, John (2023-02-02), Accelerating Large Language Model Decoding with Speculative Sampling, arXiv:2302.01318
– Discussion of the effect of a transformer layer as equivalent to a Hopfield update, bringing the input closer to one of the fixed points (representable patterns) of a continuous-valued Hopfield network
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.