
In probability theory and statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is The parameter is the mean or expectation of the distribution, while the parameter is the variance. The standard deviation of the distribution is . A random variable with a Gaussian distribution is said to be normally distributed, and is called a normal deviate.

In probability theory, the central limit theorem (CLT) states that, under appropriate conditions, the distribution of a normalized version of the sample mean converges to a standard normal distribution. This holds even if the original variables themselves are not normally distributed. There are several versions of the CLT, each applying in the context of different conditions.

The Navier–Stokes equations are partial differential equations which describe the motion of viscous fluid substances. They were named after French engineer and physicist Claude-Louis Navier and the Irish physicist and mathematician George Gabriel Stokes. They were developed over several decades of progressively building the theories, from 1822 (Navier) to 1842–1850 (Stokes).

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables, each of which clusters around a mean value.
In probability theory and statistics, the cumulantsκn of a probability distribution are a set of quantities that provide an alternative to the moments of the distribution. Any two probability distributions whose moments are identical will have identical cumulants as well, and vice versa.
A Newtonian fluid is a fluid in which the viscous stresses arising from its flow are at every point linearly correlated to the local strain rate — the rate of change of its deformation over time. Stresses are proportional to the rate of change of the fluid's velocity vector.

In nuclear physics, the chiral model, introduced by Feza Gürsey in 1960, is a phenomenological model describing effective interactions of mesons in the chiral limit (where the masses of the quarks go to zero), but without necessarily mentioning quarks at all. It is a nonlinear sigma model with the principal homogeneous space of a Lie group as its target manifold. When the model was originally introduced, this Lie group was the SU(N), where N is the number of quark flavors. The Riemannian metric of the target manifold is given by a positive constant multiplied by the Killing form acting upon the Maurer–Cartan form of SU(N).
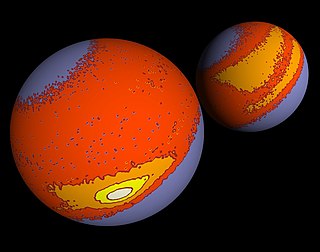
Directional statistics is the subdiscipline of statistics that deals with directions, axes or rotations in Rn. More generally, directional statistics deals with observations on compact Riemannian manifolds including the Stiefel manifold.
In probability and statistics, a circular distribution or polar distribution is a probability distribution of a random variable whose values are angles, usually taken to be in the range [0, 2π). A circular distribution is often a continuous probability distribution, and hence has a probability density, but such distributions can also be discrete, in which case they are called circular lattice distributions. Circular distributions can be used even when the variables concerned are not explicitly angles: the main consideration is that there is not usually any real distinction between events occurring at the opposite ends of the range, and the division of the range could notionally be made at any point.

In probability theory and directional statistics, the von Mises distribution is a continuous probability distribution on the circle. It is a close approximation to the wrapped normal distribution, which is the circular analogue of the normal distribution. A freely diffusing angle on a circle is a wrapped normally distributed random variable with an unwrapped variance that grows linearly in time. On the other hand, the von Mises distribution is the stationary distribution of a drift and diffusion process on the circle in a harmonic potential, i.e. with a preferred orientation. The von Mises distribution is the maximum entropy distribution for circular data when the real and imaginary parts of the first circular moment are specified. The von Mises distribution is a special case of the von Mises–Fisher distribution on the N-dimensional sphere.

In directional statistics, the Kent distribution, also known as the 5-parameter Fisher–Bingham distribution, is a probability distribution on the unit sphere. It is the analogue on S2 of the bivariate normal distribution with an unconstrained covariance matrix. The Kent distribution was proposed by John T. Kent in 1982, and is used in geology as well as bioinformatics.
Bayesian linear regression is a type of conditional modeling in which the mean of one variable is described by a linear combination of other variables, with the goal of obtaining the posterior probability of the regression coefficients and ultimately allowing the out-of-sample prediction of the regressandconditional on observed values of the regressors. The simplest and most widely used version of this model is the normal linear model, in which given is distributed Gaussian. In this model, and under a particular choice of prior probabilities for the parameters—so-called conjugate priors—the posterior can be found analytically. With more arbitrarily chosen priors, the posteriors generally have to be approximated.
In statistics, the multivariate t-distribution is a multivariate probability distribution. It is a generalization to random vectors of the Student's t-distribution, which is a distribution applicable to univariate random variables. While the case of a random matrix could be treated within this structure, the matrix t-distribution is distinct and makes particular use of the matrix structure.
In quantum mechanics, the Pauli equation or Schrödinger–Pauli equation is the formulation of the Schrödinger equation for spin-1/2 particles, which takes into account the interaction of the particle's spin with an external electromagnetic field. It is the non-relativistic limit of the Dirac equation and can be used where particles are moving at speeds much less than the speed of light, so that relativistic effects can be neglected. It was formulated by Wolfgang Pauli in 1927. In its linearized form it is known as Lévy-Leblond equation.
In fluid dynamics and electrostatics, slender-body theory is a methodology that can be used to take advantage of the slenderness of a body to obtain an approximation to a field surrounding it and/or the net effect of the field on the body. Principal applications are to Stokes flow — at very low Reynolds numbers — and in electrostatics.
In probability theory and statistics, the negative multinomial distribution is a generalization of the negative binomial distribution (NB(x0, p)) to more than two outcomes.
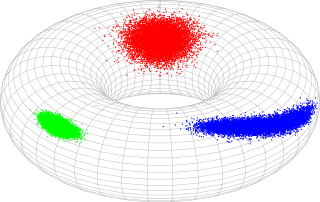
In probability theory and statistics, the bivariate von Mises distribution is a probability distribution describing values on a torus. It may be thought of as an analogue on the torus of the bivariate normal distribution. The distribution belongs to the field of directional statistics. The general bivariate von Mises distribution was first proposed by Kanti Mardia in 1975. One of its variants is today used in the field of bioinformatics to formulate a probabilistic model of protein structure in atomic detail, such as backbone-dependent rotamer libraries.

In probability theory, a logit-normal distribution is a probability distribution of a random variable whose logit has a normal distribution. If Y is a random variable with a normal distribution, and t is the standard logistic function, then X = t(Y) has a logit-normal distribution; likewise, if X is logit-normally distributed, then Y = logit(X)= log (X/(1-X)) is normally distributed. It is also known as the logistic normal distribution, which often refers to a multinomial logit version (e.g.).
The optical metric was defined by German theoretical physicist Walter Gordon in 1923 to study the geometrical optics in curved space-time filled with moving dielectric materials.
In the mathematical theory of probability, multivariate Laplace distributions are extensions of the Laplace distribution and the asymmetric Laplace distribution to multiple variables. The marginal distributions of symmetric multivariate Laplace distribution variables are Laplace distributions. The marginal distributions of asymmetric multivariate Laplace distribution variables are asymmetric Laplace distributions.










































































































































