Additive white Gaussian noise (AWGN) is a basic noise model used in information theory to mimic the effect of many random processes that occur in nature. The modifiers denote specific characteristics:
Additive because it is added to any noise that might be intrinsic to the information system.
White refers to the idea that it has uniform power spectral density across the frequency band for the information system. It is an analogy to the color white which may be realized by uniform emissions at all frequencies in the visible spectrum.
Wideband noise comes from many natural noise sources, such as the thermal vibrations of atoms in conductors (referred to as thermal noise or Johnson–Nyquist noise), shot noise, black-body radiation from the earth and other warm objects, and from celestial sources such as the Sun. The central limit theorem of probability theory indicates that the summation of many random processes will tend to have distribution called Gaussian or Normal.
The AWGN channel is a good model for many satellite and deep space communication links. It is not a good model for most terrestrial links because of multipath, terrain blocking, interference, etc. However, for terrestrial path modeling, AWGN is commonly used to simulate background noise of the channel under study, in addition to multipath, terrain blocking, interference, ground clutter and self interference that modern radio systems encounter in terrestrial operation.
Channel capacity
The AWGN channel is represented by a series of outputs at discrete-time event index . is the sum of the input and noise, , where is independent and identically distributed and drawn from a zero-mean normal distribution with variance (the noise). The are further assumed to not be correlated with the .
The capacity of the channel is infinite unless the noise is nonzero, and the are sufficiently constrained. The most common constraint on the input is the so-called "power" constraint, requiring that for a codeword transmitted through the channel, we have:
where represents the maximum channel power. Therefore, the channel capacity for the power-constrained channel is given by:[clarification needed]
where is the distribution of . Expand , writing it in terms of the differential entropy:
From this bound, we infer from a property of the differential entropy that
Therefore, the channel capacity is given by the highest achievable bound on the mutual information:
Where is maximized when:
Thus the channel capacity for the AWGN channel is given by:
Channel capacity and sphere packing
Suppose that we are sending messages through the channel with index ranging from to , the number of distinct possible messages. If we encode the messages to bits, then we define the rate as:
A rate is said to be achievable if there is a sequence of codes so that the maximum probability of error tends to zero as approaches infinity. The capacity is the highest achievable rate.
Consider a codeword of length sent through the AWGN channel with noise level . When received, the codeword vector variance is now , and its mean is the codeword sent. The vector is very likely to be contained in a sphere of radius around the codeword sent. If we decode by mapping every message received onto the codeword at the center of this sphere, then an error occurs only when the received vector is outside of this sphere, which is very unlikely.
Each codeword vector has an associated sphere of received codeword vectors which are decoded to it and each such sphere must map uniquely onto a codeword. Because these spheres therefore must not intersect, we are faced with the problem of sphere packing. How many distinct codewords can we pack into our -bit codeword vector? The received vectors have a maximum energy of and therefore must occupy a sphere of radius . Each codeword sphere has radius . The volume of an n-dimensional sphere is directly proportional to , so the maximum number of uniquely decodeable spheres that can be packed into our sphere with transmission power P is:
By this argument, the rate R can be no more than .
Achievability
In this section, we show achievability of the upper bound on the rate from the last section.
A codebook, known to both encoder and decoder, is generated by selecting codewords of length n, i.i.d. Gaussian with variance and mean zero. For large n, the empirical variance of the codebook will be very close to the variance of its distribution, thereby avoiding violation of the power constraint probabilistically.
Received messages are decoded to a message in the codebook which is uniquely jointly typical. If there is no such message or if the power constraint is violated, a decoding error is declared.
Let denote the codeword for message , while is, as before the received vector. Define the following three events:
Event :the power of the received message is larger than .
Event : the transmitted and received codewords are not jointly typical.
Event : is in , the typical set where , which is to say that the incorrect codeword is jointly typical with the received vector.
An error therefore occurs if , or any of the occur. By the law of large numbers, goes to zero as n approaches infinity, and by the joint Asymptotic Equipartition Property the same applies to . Therefore, for a sufficiently large , both and are each less than . Since and are independent for , we have that and are also independent. Therefore, by the joint AEP, . This allows us to calculate , the probability of error as follows:
Therefore, as n approaches infinity, goes to zero and . Therefore, there is a code of rate R arbitrarily close to the capacity derived earlier.
Coding theorem converse
Here we show that rates above the capacity are not achievable.
Suppose that the power constraint is satisfied for a codebook, and further suppose that the messages follow a uniform distribution. Let be the input messages and the output messages. Thus the information flows as:
Let be the encoded message of codeword index i. Then:
Let be the average power of the codeword of index i:
where the sum is over all input messages . and are independent, thus the expectation of the power of is, for noise level :
And, if is normally distributed, we have that
Therefore,
We may apply Jensen's equality to , a concave (downward) function of x, to get:
Because each codeword individually satisfies the power constraint, the average also satisfies the power constraint. Therefore,
which we may apply to simplify the inequality above and get:
Therefore, it must be that . Therefore, R must be less than a value arbitrarily close to the capacity derived earlier, as .
Effects in time domain
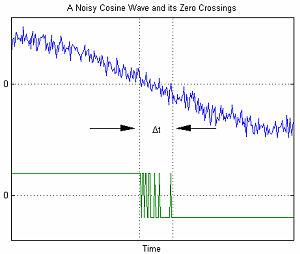
Zero crossings of a noisy cosine
In serial data communications, the AWGN mathematical model is used to model the timing error caused by random jitter (RJ).
The graph to the right shows an example of timing errors associated with AWGN. The variable Δt represents the uncertainty in the zero crossing. As the amplitude of the AWGN is increased, the signal-to-noise ratio decreases. This results in increased uncertainty Δt.[1]
When affected by AWGN, the average number of either positive-going or negative-going zero crossings per second at the output of a narrow bandpass filter when the input is a sine wave is
where
ƒ0 = the center frequency of the filter,
B = the filter bandwidth,
SNR = the signal-to-noise power ratio in linear terms.
Effects in phasor domain
AWGN contributions in the phasor domain
In modern communication systems, bandlimited AWGN cannot be ignored. When modeling bandlimited AWGN in the phasor domain, statistical analysis reveals that the amplitudes of the real and imaginary contributions are independent variables which follow the Gaussian distribution model. When combined, the resultant phasor's magnitude is a Rayleigh-distributed random variable, while the phase is uniformly distributed from 0 to2π.
The graph to the right shows an example of how bandlimited AWGN can affect a coherent carrier signal. The instantaneous response of the noise vector cannot be precisely predicted, however, its time-averaged response can be statistically predicted. As shown in the graph, we confidently predict that the noise phasor will reside about 38% of the time inside the 1σ circle, about 86% of the time inside the 2σ circle, and about 98% of the time inside the 3σ circle.[1]
In mathematical physics, the Dirac delta distribution, also known as the unit impulse, is a generalized function or distribution over the real numbers, whose value is zero everywhere except at zero, and whose integral over the entire real line is equal to one.
In mathematics, the Wiener process is a real-valued continuous-time stochastic process named in honor of American mathematician Norbert Wiener for his investigations on the mathematical properties of the one-dimensional Brownian motion. It is often also called Brownian motion due to its historical connection with the physical process of the same name originally observed by Scottish botanist Robert Brown. It is one of the best known Lévy processes and occurs frequently in pure and applied mathematics, economics, quantitative finance, evolutionary biology, and physics.
Channel capacity, in electrical engineering, computer science, and information theory, is the tight upper bound on the rate at which information can be reliably transmitted over a communication channel.
In information theory, the typical set is a set of sequences whose probability is close to two raised to the negative power of the entropy of their source distribution. That this set has total probability close to one is a consequence of the asymptotic equipartition property (AEP) which is a kind of law of large numbers. The notion of typicality is only concerned with the probability of a sequence and not the actual sequence itself.
In thermodynamics, the Helmholtz free energy is a thermodynamic potential that measures the useful work obtainable from a closed thermodynamic system at a constant temperature (isothermal). The change in the Helmholtz energy during a process is equal to the maximum amount of work that the system can perform in a thermodynamic process in which temperature is held constant. At constant temperature, the Helmholtz free energy is minimized at equilibrium.
In probability theory, a Chernoff bound is an exponentially decreasing upper bound on the tail of a random variable based on its moment generating function. The minimum of all such exponential bounds forms the Chernoff or Chernoff-Cramér bound, which may decay faster than exponential. It is especially useful for sums of independent random variables, such as sums of Bernoulli random variables.
In the theory of stochastic processes, the Karhunen–Loève theorem, also known as the Kosambi–Karhunen–Loève theorem states that a stochastic process can be represented as an infinite linear combination of orthogonal functions, analogous to a Fourier series representation of a function on a bounded interval. The transformation is also known as Hotelling transform and eigenvector transform, and is closely related to principal component analysis (PCA) technique widely used in image processing and in data analysis in many fields.
In probability theory, Hoeffding's inequality provides an upper bound on the probability that the sum of bounded independent random variables deviates from its expected value by more than a certain amount. Hoeffding's inequality was proven by Wassily Hoeffding in 1963.
In information theory, Shannon's source coding theorem establishes the statistical limits to possible data compression for data whose source is an independent identically-distributed random variable, and the operational meaning of the Shannon entropy.
Szemerédi's regularity lemma is one of the most powerful tools in extremal graph theory, particularly in the study of large dense graphs. It states that the vertices of every large enough graph can be partitioned into a bounded number of parts so that the edges between different parts behave almost randomly.
In information theory, the noisy-channel coding theorem, establishes that for any given degree of noise contamination of a communication channel, it is possible to communicate discrete data nearly error-free up to a computable maximum rate through the channel. This result was presented by Claude Shannon in 1948 and was based in part on earlier work and ideas of Harry Nyquist and Ralph Hartley.
In information theory, the error exponent of a channel code or source code over the block length of the code is the rate at which the error probability decays exponentially with the block length of the code. Formally, it is defined as the limiting ratio of the negative logarithm of the error probability to the block length of the code for large block lengths. For example, if the probability of error of a decoder drops as , where is the block length, the error exponent is . In this example, approaches for large . Many of the information-theoretic theorems are of asymptotic nature, for example, the channel coding theorem states that for any rate less than the channel capacity, the probability of the error of the channel code can be made to go to zero as the block length goes to infinity. In practical situations, there are limitations to the delay of the communication and the block length must be finite. Therefore, it is important to study how the probability of error drops as the block length go to infinity.
In probability theory and theoretical computer science, McDiarmid's inequality is a concentration inequality which bounds the deviation between the sampled value and the expected value of certain functions when they are evaluated on independent random variables. McDiarmid's inequality applies to functions that satisfy a bounded differences property, meaning that replacing a single argument to the function while leaving all other arguments unchanged cannot cause too large of a change in the value of the function.
In mathematics, the Grothendieck inequality states that there is a universal constant with the following property. If Mij is an n × n matrix with
In mathematics, the Riemann hypothesis is the conjecture that the Riemann zeta function has its zeros only at the negative even integers and complex numbers with real part 1/2. Many consider it to be the most important unsolved problem in pure mathematics. It is of great interest in number theory because it implies results about the distribution of prime numbers. It was proposed by Bernhard Riemann (1859), after whom it is named.
Anatoly Alexeyevich Karatsuba was a Russian mathematician working in the field of analytic number theory, p-adic numbers and Dirichlet series.
In computer networks, self-similarity is a feature of network data transfer dynamics. When modeling network data dynamics the traditional time series models, such as an autoregressive moving average model are not appropriate. This is because these models only provide a finite number of parameters in the model and thus interaction in a finite time window, but the network data usually have a long-range dependent temporal structure. A self-similar process is one way of modeling network data dynamics with such a long range correlation. This article defines and describes network data transfer dynamics in the context of a self-similar process. Properties of the process are shown and methods are given for graphing and estimating parameters modeling the self-similarity of network data.
In mathematics, singular integral operators of convolution type are the singular integral operators that arise on Rn and Tn through convolution by distributions; equivalently they are the singular integral operators that commute with translations. The classical examples in harmonic analysis are the harmonic conjugation operator on the circle, the Hilbert transform on the circle and the real line, the Beurling transform in the complex plane and the Riesz transforms in Euclidean space. The continuity of these operators on L2 is evident because the Fourier transform converts them into multiplication operators. Continuity on Lp spaces was first established by Marcel Riesz. The classical techniques include the use of Poisson integrals, interpolation theory and the Hardy–Littlewood maximal function. For more general operators, fundamental new techniques, introduced by Alberto Calderón and Antoni Zygmund in 1952, were developed by a number of authors to give general criteria for continuity on Lp spaces. This article explains the theory for the classical operators and sketches the subsequent general theory.
In mathematics and theoretical computer science, analysis of Boolean functions is the study of real-valued functions on or from a spectral perspective. The functions studied are often, but not always, Boolean-valued, making them Boolean functions. The area has found many applications in combinatorics, social choice theory, random graphs, and theoretical computer science, especially in hardness of approximation, property testing, and PAC learning.
Stochastic gradient Langevin dynamics (SGLD) is an optimization and sampling technique composed of characteristics from Stochastic gradient descent, a Robbins–Monro optimization algorithm, and Langevin dynamics, a mathematical extension of molecular dynamics models. Like stochastic gradient descent, SGLD is an iterative optimization algorithm which uses minibatching to create a stochastic gradient estimator, as used in SGD to optimize a differentiable objective function. Unlike traditional SGD, SGLD can be used for Bayesian learning as a sampling method. SGLD may be viewed as Langevin dynamics applied to posterior distributions, but the key difference is that the likelihood gradient terms are minibatched, like in SGD. SGLD, like Langevin dynamics, produces samples from a posterior distribution of parameters based on available data. First described by Welling and Teh in 2011, the method has applications in many contexts which require optimization, and is most notably applied in machine learning problems.
References
1 2 McClaning, Kevin, Radio Receiver Design, Noble Publishing Corporation
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.