Geostatistics is a branch of statistics focusing on spatial or spatiotemporal datasets. Developed originally to predict probability distributions of ore grades for mining operations, it is currently applied in diverse disciplines including petroleum geology, hydrogeology, hydrology, meteorology, oceanography, geochemistry, geometallurgy, geography, forestry, environmental control, landscape ecology, soil science, and agriculture. Geostatistics is applied in varied branches of geography, particularly those involving the spread of diseases (epidemiology), the practice of commerce and military planning (logistics), and the development of efficient spatial networks. Geostatistical algorithms are incorporated in many places, including geographic information systems (GIS).

In machine learning, support vector machines are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues SVMs are one of the most robust prediction methods, being based on statistical learning frameworks or VC theory proposed by Vapnik and Chervonenkis (1974). Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier. SVM maps training examples to points in space so as to maximise the width of the gap between the two categories. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
Factor analysis is a statistical method used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors. For example, it is possible that variations in six observed variables mainly reflect the variations in two unobserved (underlying) variables. Factor analysis searches for such joint variations in response to unobserved latent variables. The observed variables are modelled as linear combinations of the potential factors plus "error" terms, hence factor analysis can be thought of as a special case of errors-in-variables models.

In statistics, originally in geostatistics, kriging or Kriging, also known as Gaussian process regression, is a method of interpolation based on Gaussian process governed by prior covariances. Under suitable assumptions of the prior, kriging gives the best linear unbiased prediction (BLUP) at unsampled locations. Interpolating methods based on other criteria such as smoothness may not yield the BLUP. The method is widely used in the domain of spatial analysis and computer experiments. The technique is also known as Wiener–Kolmogorov prediction, after Norbert Wiener and Andrey Kolmogorov.
In statistics, a linear probability model (LPM) is a special case of a binary regression model. Here the dependent variable for each observation takes values which are either 0 or 1. The probability of observing a 0 or 1 in any one case is treated as depending on one or more explanatory variables. For the "linear probability model", this relationship is a particularly simple one, and allows the model to be fitted by linear regression.
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable.
In spatial statistics the theoretical variogram, denoted , is a function describing the degree of spatial dependence of a spatial random field or stochastic process . The semivariogram is half the variogram.
In robust statistics, robust regression seeks to overcome some limitations of traditional regression analysis. A regression analysis models the relationship between one or more independent variables and a dependent variable. Standard types of regression, such as ordinary least squares, have favourable properties if their underlying assumptions are true, but can give misleading results otherwise. Robust regression methods are designed to limit the effect that violations of assumptions by the underlying data-generating process have on regression estimates.
Digital soil mapping (DSM) in soil science, also referred to as predictive soil mapping or pedometric mapping, is the computer-assisted production of digital maps of soil types and soil properties. Soil mapping, in general, involves the creation and population of spatial soil information by the use of field and laboratory observational methods coupled with spatial and non-spatial soil inference systems.

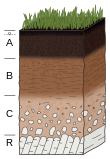
Soil map is a geographical representation showing diversity of soil types and/or soil properties in the area of interest. It is typically the end result of a soil survey inventory, i.e. soil survey. Soil maps are most commonly used for land evaluation, spatial planning, agricultural extension, environmental protection and similar projects. Traditional soil maps typically show only general distribution of soils, accompanied by the soil survey report. Many new soil maps are derived using digital soil mapping techniques. Such maps are typically richer in context and show higher spatial detail than traditional soil maps. Soil maps produced using (geo)statistical techniques also include an estimate of the model uncertainty.
In statistics, generalized least squares (GLS) is a method used to estimate the unknown parameters in a linear regression model when there is a certain degree of correlation between the residuals in the regression model. In such cases, ordinary least squares and weighted least squares may need to be more statistically efficient or else lead to misleading inferences. GLS was first described by Alexander Aitken in 1935.
The Richards equation represents the movement of water in unsaturated soils, and is attributed to Lorenzo A. Richards who published the equation in 1931. It is a quasilinear partial differential equation; its analytical solution is often limited to specific initial and boundary conditions. Proof of the existence and uniqueness of solution was given only in 1983 by Alt and Luckhaus. The equation is based on Darcy-Buckingham law representing flow in porous media under variably saturated conditions, which is stated as
The European Soil Database is the only harmonized soil database in Europe from which many other data information and services are derived. For instance, the European Soil Database v2 Raster Library contains raster (grid) data files with cell sizes of 1km x 1km for a large number of soil related parameters. Each grid is aligned with the INSPIRE reference grid. These rasters are in the public domain and allow expert users to use the data for instance to run soil-, water- and air related models.. The European Soil Database may be downloaded from the European Soil Data Center.
The hat operator is a mathematical notation with various uses in different branches of science and mathematics.
Pedodiversity is the variation of soil properties within an area. Pedodiversity studies were first started by analyzing soil series–area relationships. According to Guo et al. (2003) the term pedodiversity was developed by McBratney (1992) who discussed landscape preservation strategies based on pedodiversity. Recently, examinations of pedodiversity using indices commonly used to characterize bio-diversity have been made. Ibáñez et al. (1995) first introduced ecological diversity indices as measures of pedodiversity. They include Species richness, abundance, and Shannon index. Richness is the number of different soil types, which is the number of soil classes at particular level in a taxonomic system. Abundance is defined as the distribution of the number of soil individuals.
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modelled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression.
In statistics and in machine learning, a linear predictor function is a linear function of a set of coefficients and explanatory variables, whose value is used to predict the outcome of a dependent variable. This sort of function usually comes in linear regression, where the coefficients are called regression coefficients. However, they also occur in various types of linear classifiers, as well as in various other models, such as principal component analysis and factor analysis. In many of these models, the coefficients are referred to as "weights".
In applied statistics and geostatistics, regression-kriging (RK) is a spatial prediction technique that combines a regression of the dependent variable on auxiliary variables with interpolation (kriging) of the regression residuals. It is mathematically equivalent to the interpolation method variously called universal kriging and kriging with external drift, where auxiliary predictors are used directly to solve the kriging weights.
Kernel methods are a well-established tool to analyze the relationship between input data and the corresponding output of a function. Kernels encapsulate the properties of functions in a computationally efficient way and allow algorithms to easily swap functions of varying complexity.
In statistics, linear regression is a linear approach for modelling the relationship between a scalar response and one or more explanatory variables. The case of one explanatory variable is called simple linear regression; for more than one, the process is called multiple linear regression. This term is distinct from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable.