
Cyc is a long-term artificial intelligence project that aims to assemble a comprehensive ontology and knowledge base that spans the basic concepts and rules about how the world works. Hoping to capture common sense knowledge, Cyc focuses on implicit knowledge that other AI platforms may take for granted. This is contrasted with facts one might find somewhere on the internet or retrieve via a search engine or Wikipedia. Cyc enables semantic reasoners to perform human-like reasoning and be less "brittle" when confronted with novel situations.

Knowledge representation and reasoning is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can use to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language. Knowledge representation incorporates findings from psychology about how humans solve problems and represent knowledge in order to design formalisms that will make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning, such as the application of rules or the relations of sets and subsets.
The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
Description logics (DL) are a family of formal knowledge representation languages. Many DLs are more expressive than propositional logic but less expressive than first-order logic. In contrast to the latter, the core reasoning problems for DLs are (usually) decidable, and efficient decision procedures have been designed and implemented for these problems. There are general, spatial, temporal, spatiotemporal, and fuzzy description logics, and each description logic features a different balance between expressive power and reasoning complexity by supporting different sets of mathematical constructors.
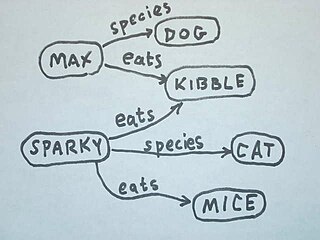
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects.
A modeling language is any artificial language that can be used to express information or knowledge or systems in a structure that is defined by a consistent set of rules. The rules are used for interpretation of the meaning of components in the structure Programing language.
In information science, an upper ontology is an ontology which consists of very general terms that are common across all domains. An important function of an upper ontology is to support broad semantic interoperability among a large number of domain-specific ontologies by providing a common starting point for the formulation of definitions. Terms in the domain ontology are ranked under the terms in the upper ontology, e.g., the upper ontology classes are superclasses or supersets of all the classes in the domain ontologies.
In computer science and artificial intelligence, ontology languages are formal languages used to construct ontologies. They allow the encoding of knowledge about specific domains and often include reasoning rules that support the processing of that knowledge. Ontology languages are usually declarative languages, are almost always generalizations of frame languages, and are commonly based on either first-order logic or on description logic.
Semantic integration is the process of interrelating information from diverse sources, for example calendars and to do lists, email archives, presence information, documents of all sorts, contacts, search results, and advertising and marketing relevance derived from them. In this regard, semantics focuses on the organization of and action upon information by acting as an intermediary between heterogeneous data sources, which may conflict not only by structure but also context or value.
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
Simple Knowledge Organization System (SKOS) is a W3C recommendation designed for representation of thesauri, classification schemes, taxonomies, subject-heading systems, or any other type of structured controlled vocabulary. SKOS is part of the Semantic Web family of standards built upon RDF and RDFS, and its main objective is to enable easy publication and use of such vocabularies as linked data.
Gellish is an ontology language for data storage and communication, designed and developed by Andries van Renssen since mid-1990s. It started out as an engineering modeling language but evolved into a universal and extendable conceptual data modeling language with general applications. Because it includes domain-specific terminology and definitions, it is also a semantic data modelling language and the Gellish modeling methodology is a member of the family of semantic modeling methodologies.
Frames are an artificial intelligence data structure used to divide knowledge into substructures by representing "stereotyped situations". They were proposed by Marvin Minsky in his 1974 article "A Framework for Representing Knowledge". Frames are the primary data structure used in artificial intelligence frame languages; they are stored as ontologies of sets.
The concept of the Social Semantic Web subsumes developments in which social interactions on the Web lead to the creation of explicit and semantically rich knowledge representations. The Social Semantic Web can be seen as a Web of collective knowledge systems, which are able to provide useful information based on human contributions and which get better as more people participate. The Social Semantic Web combines technologies, strategies and methodologies from the Semantic Web, social software and the Web 2.0.
Machine interpretation of documents and services in Semantic Web environment is primarily enabled by (a) the capability to mark documents, document segments and services with semantic tags and (b) the ability to establish contextual relations between the tags with a domain model, which is formally represented as ontology. Human beings use natural languages to communicate an abstract view of the world. Natural language constructs are symbolic representations of human experience and are close to the conceptual model that Semantic Web technologies deal with. Thus, natural language constructs have been naturally used to represent the ontology elements. This makes it convenient to apply Semantic Web technologies in the domain of textual information. In contrast, multimedia documents are perceptual recording of human experience. An attempt to use a conceptual model to interpret the perceptual records gets severely impaired by the semantic gap that exists between the perceptual media features and the conceptual world. Notably, the concepts have their roots in perceptual experience of human beings and the apparent disconnect between the conceptual and the perceptual world is rather artificial. The key to semantic processing of multimedia data lies in harmonizing the seemingly isolated conceptual and the perceptual worlds. Representation of the Domain knowledge needs to be extended to enable perceptual modeling, over and above conceptual modeling that is supported. The perceptual model of a domain primarily comprises observable media properties of the concepts. Such perceptual models are useful for semantic interpretation of media documents, just as the conceptual models help in the semantic interpretation of textual documents.

In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.

In information science a conceptualization is an abstract simplified view of some selected part of the world, containing the objects, concepts, and other entities that are presumed of interest for some particular purpose and the relationships between them. An explicit specification of a conceptualization is an ontology, and it may occur that a conceptualization can be realized by several distinct ontologies. An ontological commitment in describing ontological comparisons is taken to refer to that subset of elements of an ontology shared with all the others. "An ontology is language-dependent", its objects and interrelations described within the language it uses, while a conceptualization is always the same, more general, its concepts existing "independently of the language used to describe it". The relation between these terms is shown in the figure to the right.

UMBEL is a logically organized knowledge graph of 34,000 concepts and entity types that can be used in information science for relating information from disparate sources to one another. It was retired at the end of 2019. UMBEL was first released in July 2008. Version 1.00 was released in February 2011. Its current release is version 1.50.
A semantic triple, or RDF triple or simply triple, is the atomic data entity in the Resource Description Framework (RDF) data model. As its name indicates, a triple is a set of three entities that codifies a statement about semantic data in the form of subject–predicate–object expressions.
