Related Research Articles

Inuktitut syllabics is an abugida-type writing system used in Canada by the Inuktitut-speaking Inuit of the territory of Nunavut and the Nunavik and Nunatsiavut regions of Quebec and Labrador, respectively. In 1976, the Language Commission of the Inuit Cultural Institute made it the co-official script for the Inuit languages, along with the Latin script.

Canadian syllabic writing, or simply syllabics, is a family of writing systems used in a number of Indigenous Canadian languages of the Algonquian, Inuit, and (formerly) Athabaskan language families. These languages had no formal writing system previously. They are valued for their distinctiveness from the Latin script and for the ease with which literacy can be achieved. For instance, by the late 19th century the Cree had achieved what may have been one of the highest rates of literacy in the world.
Unicode has subscripted and superscripted versions of a number of characters including a full set of Arabic numerals. These characters allow any polynomial, chemical and certain other equations to be represented in plain text without using any form of markup like HTML or TeX.

GNU FreeFont is a family of free OpenType, TrueType and WOFF vector fonts, implementing as much of the Universal Character Set (UCS) as possible, aside from the very large CJK Asian character set. The project was initiated in 2002 by Primož Peterlin and is now maintained by Steve White.
Yi Syllables is a Unicode block containing the 1,165 characters of the Liangshan Standard Yi script for writing the Nuosu language.
In the Unicode standard, a plane is a contiguous group of 65,536 (216) code points. There are 17 planes, identified by the numbers 0 to 16, which corresponds with the possible values 00–1016 of the first two positions in six position hexadecimal format (U+hhhhhh). Plane 0 is the Basic Multilingual Plane (BMP), which contains most commonly used characters. The higher planes 1 through 16 are called "supplementary planes". The last code point in Unicode is the last code point in plane 16, U+10FFFF. As of Unicode version 15.1, five of the planes have assigned code points (characters), and seven are named.
Unified Canadian Aboriginal Syllabics is a Unicode block containing syllabic characters for writing Inuktitut, Carrier, Cree, Ojibwe, Blackfoot and Canadian Athabascan languages. Additions for some Cree dialects, Ojibwe, and Dene can be found at the Unified Canadian Aboriginal Syllabics Extended block.
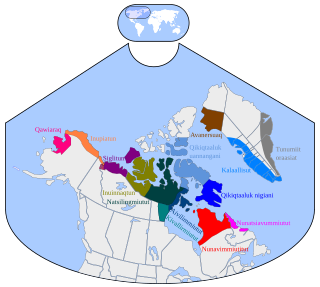
Natchilingmiutut (ᓇᑦᕠᓕᖕᒥᐅᑐᑦ), Netsilik, Natsilik, Nattilik, Netsilingmiut, Natsilingmiutut, Nattilingmiutut, or Nattiliŋmiutut is an Inuit language variety spoken in western Nunavut, Canada, by Netsilik Inuit.
Cherokee is a Unicode block containing the syllabic characters for writing the Cherokee language. When Cherokee was first added to Unicode in version 3.0 it was treated as a unicameral alphabet, but in version 8.0 it was redefined as a bicameral script. The Cherokee block contains all the uppercase letters plus six lowercase letters. The Cherokee Supplement block, added in version 8.0, contains the rest of the lowercase letters. For backwards compatibility, the Unicode case folding algorithm—which usually converts a string to lowercase characters—maps Cherokee characters to uppercase.
CJK Unified Ideographs is a Unicode block containing the most common CJK ideographs used in modern Chinese, Japanese, Korean and Vietnamese characters. When contrasted with other blocks containing CJK Unified Ideographs, it is also referred to as the Unified Repertoire and Ordering (URO).
CJK Unified Ideographs Extension C is a Unicode block containing rare and historic CJK ideographs for Chinese, Japanese, Korean, and Vietnamese submitted to the Ideographic Research Group between 2002 and 2006, plus five "urgently needed" characters added in Unicode versions 14.0 and 15.0, some of which had previously been mistakenly unified with other characters.
CJK Unified Ideographs Extension D is a Unicode block containing uncommon CJK ideographs for Chinese, Japanese, Korean, and Vietnamese, some of which are in current use. Much smaller than most Unicode blocks for CJK unified ideographs, Extension D consists of characters which were submitted to the Ideographic Research Group as "urgently needed characters" between 2006 and 2009. Characters submitted during the same period which were needed less urgently were included in CJK Unified Ideographs Extension E instead.
CJK Compatibility Ideographs is a Unicode block created to contain mostly Han characters that were encoded in multiple locations in other established character encodings, in addition to their CJK Unified Ideographs assignments, in order to retain round-trip compatibility between Unicode and those encodings. However, it also contains 12 unified ideographs sourced from Japanese character sets from IBM.
Linear B Syllabary is a Unicode block containing characters for the syllabic writing of Mycenaean Greek.
Linear B Ideograms is a Unicode block containing ideographic characters for writing Mycenaean Greek. Several Linear B ideographs double as syllabic letters, and are encoded in the Linear B Syllabary block.
Euphemia is a sans-serif typeface for Unified Canadian Syllabics.
Variation Selectors is a Unicode block containing 16 variation selectors used to specify a glyph variant for a preceding character. They are currently used to specify standardized variation sequences for mathematical symbols, emoji symbols, 'Phags-pa letters, and CJK unified ideographs corresponding to CJK compatibility ideographs. At present only standardized variation sequences with VS1, VS2, VS3, VS15 and VS16 have been defined; VS15 and VS16 are reserved to request that a character should be displayed as text or as an emoji respectively.
Cherokee Supplement is a Unicode block containing the syllabic characters for writing the Cherokee language. When Cherokee was first added to Unicode in version 3.0 it was treated as a unicameral alphabet, but in version 8.0 it was redefined as a bicameral script. The Cherokee Supplement block contains lowercase letters only, whereas the Cherokee block contains all the uppercase letters, together with six lowercase letters. For backwards compatibility, the Unicode case folding algorithm—which usually converts a string to lowercase characters—maps Cherokee characters to uppercase.
CJK Unified Ideographs Extension G is a Unicode block containing rare and historic CJK Unified Ideographs for Chinese, Japanese, Korean, and Vietnamese which were submitted to the Ideographic Research Group during 2015. It is the first block to be allocated to the Tertiary Ideographic Plane.
Unified Canadian Aboriginal Syllabics Extended-A is a Unicode block containing extensions to the Canadian syllabics contained in the Unified Canadian Aboriginal Syllabics Unicode block. The extension adds missing characters for Nattilik and historical characters for Cree and Ojibwe.
References
- ↑ "Unicode character database". The Unicode Standard. Retrieved 2023-07-26.
- ↑ "Enumerated Versions of The Unicode Standard". The Unicode Standard. Retrieved 2023-07-26.