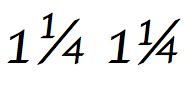The Unicode Consortium and the ISO/IEC JTC 1/SC 2/WG 2 jointly collaborate on the list of the characters in the Universal Coded Character Set. The Universal Coded Character Set, most commonly called the Universal Character Set (abbr. UCS, official designation: ISO/IEC 10646), is an international standard to map characters, discrete symbols used in natural language, mathematics, music, and other domains, to unique machine-readable data values. By creating this mapping, the UCS enables computer software vendors to interoperate, and transmit—interchange—UCS-encoded text strings from one to another. Because it is a universal map, it can be used to represent multiple languages at the same time. This avoids the confusion of using multiple legacy character encodings, which can result in the same sequence of codes having multiple interpretations depending on the character encoding in use, resulting in mojibake if the wrong one is chosen.
UCS has a potential capacity of over 1 million characters. Each UCS character is abstractly represented by a code point, an integer between 0 and 1,114,111 (1,114,112 = 220 + 216or 17 × 216 = 0x110000code points), used to represent each character within the internal logic of text processing software. As of Unicode17.0, released in September 2025, 303,808 (27%) of these code points are allocated, 159,866 (14%) have been assigned characters, 137,468 (12%) are reserved for private use, 2,048 are used to enable the mechanism of surrogates, and 66 are designated as noncharacters, leaving the remaining 810,304 (73%) unallocated. The number of encoded characters is made up as follows:
159,629 graphical characters (some of which do not have a visible glyph, but are still counted as graphical)
ISO maintains the basic mapping of characters from character name to code point. Often, the terms character and code point will be used interchangeably. However, when a distinction is made, a code point refers to the integer of the character: what one might think of as its address. Meanwhile, a character in ISO/IEC 10646 includes the combination of the code point and its name, Unicode adds many other useful properties to the character set, such as block, category, script, and directionality.
In addition to the UCS, the supplementary Unicode Standard, (not a joint project with ISO, but rather a publication of the Unicode Consortium,) provides other implementation details such as:
different collations of characters and character strings for different languages
an algorithm for laying out bidirectional text ("the BiDi algorithm"), where text on the same line may shift between left-to-right ("LTR") and right-to-left ("RTL")
An HTML or XML numeric character reference refers to a character by its Universal Character Set/Unicode code point, and uses the format
&#nnnn;
or
&#xhhhh;
where nnnn is the code point in decimal form, and hhhh is the code point in hexadecimal form. The x must be lowercase in XML documents. The nnnn or hhhh may be any number of digits and may include leading zeros. The hhhh may mix uppercase and lowercase, though uppercase is the usual style.
In contrast, a character entity reference refers to a character by the name of an entity which has the desired character as its replacement text. The entity must either be predefined (built into the markup language) or explicitly declared in a Document Type Definition (DTD). The format is the same as for any entity reference:
&name;
where name is the case-sensitive name of the entity. The semicolon is required.
Unicode and ISO divide the set of code points into 17 planes, each capable of containing 65536 distinct characters or 1,114,112 total. As of 2025 (Unicode 17.0) ISO and the Unicode Consortium has only allocated characters and blocks in seven of the 17 planes. The others remain empty and reserved for future use.
Most characters are currently assigned to the first plane: the Basic Multilingual Plane. This is to help ease the transition for legacy software since the Basic Multilingual Plane is addressable with just two octets. The characters outside the first plane usually have very specialized or rare use.
Each plane corresponds with the value of the one or two hexadecimal digits (0—9, A—F) preceding the four final ones: hence U+24321 is in Plane 2, U+4321 is in Plane 0 (implicitly read U+04321), and U+10A200 would be in Plane 16 (hex 10 = decimal 16). Within one plane, the range of code points is hexadecimal 0000—FFFF, yielding a maximum of 65536 code points. Planes restrict code points to a subset of that range.
Unicode adds a block property to UCS that further divides each plane into separate blocks. Each block is a grouping of characters by their use such as "mathematical operators" or "Hebrew script characters". When assigning characters to previously unassigned code points, the Consortium typically allocates entire blocks of similar characters: for example all the characters belonging to the same script or all similarly purposed symbols get assigned to a single block. Blocks may also maintain unassigned or reserved code points when the Consortium expects a block to require additional assignments.
The first 256 code points in the UCS correspond with those of ISO 8859-1, the most popular 8-bit character encoding in the Western world. As a result, the first 128 characters are also identical to ASCII. Though Unicode refers to these as a Latin script block, these two blocks contain many characters that are commonly useful outside of the Latin script. In general, not all characters in a given block need be of the same script, and a given script can occur in several different blocks.
Categories
Unicode assigns to every UCS character a general category and subcategory. The general categories are: letter, mark, number, punctuation, symbol, or control (in other words a formatting or non-graphical character).
Types include:
Modern, Historic, and Ancient Scripts. As of 2025 (Unicode 17.0), the UCS identifies 172 scripts that are, or have been, used throughout of the world. Many more are in various approval stages for future inclusion of the UCS.[2]
International Phonetic Alphabet. The UCS devotes several blocks (over 300 characters) to characters for the International Phonetic Alphabet.
Combining Diacritical Marks. An important advance conceived by Unicode in designing the UCS and related algorithms for handling text was the introduction of combining diacritic marks. By providing accents that can combine with any letter character, the Unicode and the UCS reduce significantly the number of characters needed. While the UCS also includes precomposed characters, these were included primarily to facilitate support within UCS for non-Unicode text processing systems.
Punctuation. Along with unifying diacritical marks, the UCS also sought to unify punctuation across scripts. Many scripts also contain punctuation, however, when that punctuation has no similar semantics in other scripts.
Symbols. Many mathematics, technical, geometrical and other symbols are included within the UCS. This provides distinct symbols with their own code point or character rather than relying on switching fonts to provide symbolic glyphs.
Currency.
Letterlike. These symbols appear like combinations of many common Latin scripts letters such as ℅. Unicode designates many of the letterlike symbols as compatibility characters usually because they can be in plain text by substituting glyphs for a composing sequence of characters: for example substituting the glyph ℅ for the composed sequence of characters c/o.
Number Forms. Number forms primarily consist of precomposed fractions and Roman numerals. Like other areas of composing sequences of characters, the Unicode approach prefers the flexibility of composing fractions by combining characters together. In this case to create fractions, one combines numbers with the fraction slash character (U+2044). As an example of the flexibility this approach provides, there are nineteen precomposed fraction characters included within the UCS. However, there are an infinity of possible fractions. By using composing characters the infinity of fractions is handled by 11 characters (0-9 and the fraction slash). No character set could include code points for every precomposed fraction. Ideally a text system should present the same glyphs for a fraction whether it is one of the precomposed fractions (such as ⅓) or a composing sequence of characters (such as 1⁄3). However, web browsers are not typically that sophisticated with Unicode and text handling. Doing so ensures that precomposed fractions and combining sequence fractions will appear compatible next to each other.
Arrows.
Mathematical.
Geometric Shapes.
Legacy Computing.
Control Pictures Graphical representations of many control characters.
Box Drawing.
Block Elements.
Braille Patterns.
Optical Character Recognition.
Technical.
Dingbats.
Miscellaneous Symbols.
Emoticons.
Symbols and Pictographs.
Alchemical Symbols.
Game Pieces (chess, checkers, go, dice, dominoes, mahjong, playing cards, and many others).
CJK. Devoted to ideographs and other characters to support languages in China, Japan, Korea (CJK), Taiwan, Vietnam, and Thailand.
Radicals and Strokes.
Ideographs. By far the largest portion of the UCS is devoted to ideographs used in languages of Eastern Asia. While the glyph representation of these ideographs have diverged in the languages that use them, the UCS unifies these Han characters in what Unicode refers to as Unihan (for Unified Han). With Unihan, the text layout software must work together with the available fonts and these Unicode characters to produce the appropriate glyph for the appropriate language. Despite unifying these characters, the UCS still includes over 101,000 Unihan ideographs.
Musical Notation.
Duployan shorthands.
Sutton SignWriting.
Compatibility Characters. Several blocks in the UCS are devoted almost entirely to compatibility characters. Compatibility characters are those included for support of legacy text handling systems that do not make a distinction between character and glyph the way Unicode does. For example, many Arabic letters are represented by a different glyph when the letter appears at the end of a word than when the letter appears at the beginning of a word. Unicode's approach prefers to have these letters mapped to the same character for ease of internal machine text processing and storage. To complement this approach, the text software must select different glyph variants for display of the character based on its context. Over 4000 characters are included for such compatibility reasons.
Control Characters.
Surrogates. The UCS includes 2048 code points in the Basic Multilingual Plane (BMP) for surrogate code point pairs. Together these surrogates allow any code point in the sixteen other planes to be addressed by using two surrogate code points. This provides a simple built-in method for encoding the 20.1 bit UCS within a 16 bit encoding such as UTF-16. In this way UTF-16 can represent any character within the BMP with a single 16-bit word. Characters outside the BMP are then encoded using two 16-bit words (4 octets or bytes total) using the surrogate pairs.
Private Use. The consortium provides several private use blocks and planes that can be assigned characters within various communities, as well as operating system and font vendors.
Noncharacters. The consortium guarantees certain code points will never be assigned a character and calls these noncharacter code points. These include the range U+FDD0..U+FDEF, and the last two code points of each plane (ending in the hexadecimal digits FFFE and FFFF).[3]
Unicode codifies over a hundred thousand characters. Most of those represent graphemes for processing as linear text. Some, however, either do not represent graphemes, or, as graphemes, require exceptional treatment.[4][5] Unlike the ASCII control characters and other characters included for legacy round-trip capabilities, these other special-purpose characters endow plain text with important semantics.
Some special characters can alter the layout of text, such as the zero-width joiner and zero-width non-joiner, while others do not affect text layout at all, but instead affect the way text strings are collated, matched or otherwise processed. Other special-purpose characters, such as the mathematical invisibles, generally have no effect on text rendering, though sophisticated text layout software may choose to subtly adjust spacing around them.
Unicode does not specify the division of labor between font and text layout software (or "engine") when rendering Unicode text. Because the more complex font formats, such as OpenType or Apple Advanced Typography, provide for contextual substitution and positioning of glyphs, a simple text layout engine might rely entirely on the font for all decisions of glyph choice and placement. In the same situation a more complex engine may combine information from the font with its own rules to achieve its own idea of best rendering. To implement all recommendations of the Unicode specification, a text engine must be prepared to work with fonts of any level of sophistication, since contextual substitution and positioning rules do not exist in some font formats and are optional in the rest. The fraction slash is an example: complex fonts may or may not supply positioning rules in the presence of the fraction slash character to create a fraction, while fonts in simple formats cannot.
Byte order mark
When appearing at the head of a text file or stream, U+FEFFZERO WIDTH NO-BREAK SPACE hints at the encoding form and its byte order.
If the stream's first byte is 0xFE and the second 0xFF, then the stream's text is not likely to be encoded in UTF-8, since those bytes are invalid in UTF-8. It is also not likely to be UTF-16 in little-endian byte order because 0xFE, 0xFF read as a 16-bit little endian word would be U+FFFE, which is meaningless. The sequence also has no meaning in any arrangement of UTF-32 encoding, so, in summary, it serves as a fairly reliable indication that the text stream is encoded as UTF-16 in big-endian byte order. Conversely, if the first two bytes are 0xFF, 0xFE, then the text stream may be assumed to be encoded as UTF-16LE because, read as a 16-bit little-endian value, the bytes yield the expected 0xFEFF byte order mark. This assumption becomes questionable, however, if the next two bytes are both 0x00; either the text begins with a null character (U+0000), or the correct encoding is actually UTF-32LE, in which the full 4-byte sequence FF FE 00 00 is one character, the BOM.
The UTF-8 sequence corresponding to U+FEFF is 0xEF, 0xBB, 0xBF. This sequence has no meaning in other Unicode encoding forms, so it may serve to indicate that that stream is encoded as UTF-8.
The Unicode specification does not require the use of byte order marks in text streams. It further states that they should not be used in situations where some other method of signaling the encoding form is already in use.
Mathematical invisibles
Primarily for mathematics, the Invisible Separator (U+2063) provides a separator between characters where punctuation or space may be omitted such as in a two-dimensional index like ij. Invisible Times (U+2062) and Function Application (U+2061) are useful in mathematics text where the multiplication of terms or the application of a function is implied without any glyph indicating the operation. Unicode 5.1 introduces the Mathematical Invisible Plus character as well (U+2064) which may indicate that an integral number followed by a fraction should denote their sum, but not their product.
Example of fraction slash use. This typeface (Apple Chancery) shows the synthesized common fraction on the left and the precomposed fraction glyph on the right as a rendering the plain text string "1 1⁄4 1¼". Depending on the text environment, the single string "1 1⁄4" might yield either result, the one on the right through substitution of the fraction sequence with the single precomposed fraction glyph.A more elaborate example of fraction slash usage: plain text "4 221⁄225" rendered in Apple Chancery. This font supplies the text layout software with instructions to synthesize the fraction according to the Unicode rule described in this section.
The U+2044⁄FRACTION SLASH character has special behavior in the Unicode Standard:[6]
The standard form of a fraction built using the fraction slash is defined as follows: any sequence of one or more decimal digits (General Category = Nd), followed by the fraction slash, followed by any sequence of one or more decimal digits. Such a fraction should be displayed as a unit, such as ¾. If the displaying software is incapable of mapping the fraction to a unit, then it can also be displayed as a simple linear sequence as a fallback (for example, 3/4). If the fraction is to be separated from a previous number, then a space can be used, choosing the appropriate width (normal, thin, zero width, and so on). For example, 1 + ZERO WIDTH SPACE + 3 + FRACTION SLASH + 4 is displayed as 1¾.
By following this Unicode recommendation, text processing systems yield sophisticated symbols from plain text alone. Here the presence of the fraction slash character instructs the layout engine to synthesize a fraction from all consecutive digits preceding and following the slash. In practice, results vary because of the complicated interplay between fonts and layout engines. Simple text layout engines tend not to synthesize fractions at all, and instead draw the glyphs as a linear sequence as described in the Unicode fallback scheme.
More sophisticated layout engines face two practical choices: they can follow Unicode's recommendation, or they can rely on the font's own instructions for synthesizing fractions. By ignoring the font's instructions, the layout engine can guarantee Unicode's recommended behavior. By following the font's instructions, the layout engine can achieve better typography because placement and shaping of the digits will be tuned to that particular font at that particular size.
The problem with following the font's instructions is that the simpler font formats have no way to specify fraction synthesis behavior. Meanwhile, the more complex formats do not require the font to specify fraction synthesis behavior and therefore many do not. Most fonts of complex formats can instruct the layout engine to replace a plain text sequence such as 1⁄2 with the precomposed ½ glyph. But because many of them will not issue instructions to synthesize fractions, a plain text string such as 221⁄225 may well render as 22½25 (with the ½ being the substituted precomposed fraction, rather than synthesized). In the face of problems like this, those who wish to rely on the recommended Unicode behavior should choose fonts known to synthesize fractions or text layout software known to produce Unicode's recommended behavior regardless of font.
Bidirectional neutral formatting
Writing direction is the direction glyphs are placed on the page in relation to forward progression of characters in the Unicode string. English and other languages of Latin script have left-to-right writing direction. Several major writing scripts, such as Arabic and Hebrew, have right-to-left writing direction. The Unicode specification assigns a directional type to each character to inform text processors how sequences of characters should be ordered on the page.
While lexical characters (that is, letters) are normally specific to a single writing script, some symbols and punctuation marks are used across many writing scripts. Unicode could have created duplicate symbols in the repertoire that differ only by directional type, but chose instead to unify them and assign them a neutral directional type. They acquire direction at render time from adjacent characters. Some of these characters also have a bidi-mirrored property indicating the glyph should be rendered in mirror-image when used in right-to-left text.
The render-time directional type of a neutral character can remain ambiguous when the mark is placed on the boundary between directional changes. To address this, Unicode includes characters that have strong directionality, have no glyph associated with them, and are ignorable by systems that do not process bidirectional text:
U+061CARABIC LETTER MARK
U+200ELEFT-TO-RIGHT MARK
U+200FRIGHT-TO-LEFT MARK
Surrounding a bidirectionally neutral character by the left-to-right mark will force the character to behave as a left-to-right character while surrounding it by the right-to-left mark will force it to behave as a right-to-left character. The behavior of these characters is detailed in Unicode's Bidirectional Algorithm.
While Unicode is designed to handle multiple languages, multiple writing systems and even text that flows either left-to-right or right-to-left with minimal author intervention, there are special circumstances where the mix of bidirectional text can become intricate—requiring more author control. For these circumstances, Unicode includes five other characters to control the complex embedding of left-to-right text within right-to-left text and vice versa:
Bidirectional formatting
U+202ALEFT-TO-RIGHT EMBEDDING
U+202BRIGHT-TO-LEFT EMBEDDING
U+202CPOP DIRECTIONAL FORMATTING
U+202DLEFT-TO-RIGHT OVERRIDE
U+202ERIGHT-TO-LEFT OVERRIDE
U+2066LEFT-TO-RIGHT ISOLATE
U+2067RIGHT-TO-LEFT ISOLATE
U+2068FIRST STRONG ISOLATE
U+2069POP DIRECTIONAL ISOLATE
Interlinear annotation characters
U+FFF9INTERLINEAR ANNOTATION ANCHOR
U+FFFAINTERLINEAR ANNOTATION SEPARATOR
U+FFFBINTERLINEAR ANNOTATION TERMINATOR
Script-specific
Prefixed format control
U+0600ARABIC NUMBER SIGN
U+0601ARABIC SIGN SANAH
U+0602ARABIC FOOTNOTE MARKER
U+0603ARABIC SIGN SAFHA
U+0604ARABIC SIGN SAMVAT
U+0605ARABIC NUMBER MARK ABOVE
U+06DDARABIC END OF AYAH
U+070FSYRIAC ABBREVIATION MARK
U+0890ARABIC POUND MARK ABOVE
U+0891ARABIC PIASTRE MARK ABOVE
U+110BDKAITHI NUMBER SIGN
U+110CDKAITHI NUMBER SIGN ABOVE
Egyptian Hieroglyphs
U+13430EGYPTIAN HIEROGLYPH VERTICAL JOINER
U+13431EGYPTIAN HIEROGLYPH HORIZONTAL JOINER
U+13432EGYPTIAN HIEROGLYPH INSERT AT TOP START
U+13433EGYPTIAN HIEROGLYPH INSERT AT BOTTOM START
U+13434EGYPTIAN HIEROGLYPH INSERT AT TOP END
U+13435EGYPTIAN HIEROGLYPH INSERT AT BOTTOM END
U+13436EGYPTIAN HIEROGLYPH OVERLAY MIDDLE
U+13437EGYPTIAN HIEROGLYPH BEGIN SEGMENT
U+13438EGYPTIAN HIEROGLYPH END SEGMENT
U+13439EGYPTIAN HIEROGLYPH INSERT AT MIDDLE
U+1343AEGYPTIAN HIEROGLYPH INSERT AT TOP
U+1343BEGYPTIAN HIEROGLYPH INSERT AT BOTTOM
U+1343CEGYPTIAN HIEROGLYPH BEGIN ENCLOSURE
U+1343DEGYPTIAN HIEROGLYPH END ENCLOSURE
U+1343EEGYPTIAN HIEROGLYPH BEGIN WALLED ENCLOSURE
U+1343FEGYPTIAN HIEROGLYPH END WALLED ENCLOSURE
Brahmi
U+1107F𑁿BRAHMI NUMBER JOINER
Characters vs. code points
The term "character" is not well-defined, and what we are referring to most of the time is the grapheme. A grapheme is represented visually by its glyph. The typeface (often erroneously referred to as font) used can depict visual variations of the same character. It is possible that two different graphemes can have the exact same glyph or are visually so close that the average reader cannot tell them apart.
A grapheme is almost always represented by one code point, for example, latin capital letter a is represented by the code point U+0041.
The grapheme U+00C4ÄLATIN CAPITAL LETTER A WITH DIAERESIS is an example where a character can be represented by more than one code point. It can be represented as U+00C4, or as the sequence U+0041ALATIN CAPITAL LETTER A and U+0308◌̈COMBINING DIAERESIS.
When a combining mark is adjacent to a non-combining mark code point, text rendering applications should superimpose the combining mark onto the glyph represented by the other code point to form a grapheme according to a set of rules.[7]
The word BÄM would therefore be three graphemes. It may be made up of three code points or more depending on how the characters are actually composed.
Unicode provides a list of characters it deems whitespace characters for interoperability support. Software Implementations and other standards may use the term to denote a slightly different set of characters. For example, Java does not consider U+00A0NO-BREAK SPACE or U+0085<control-0085> (NEXT LINE) to be whitespace, even though Unicode does. Whitespace characters are characters typically designated for programming environments. Often they have no syntactic meaning in such programming environments and are ignored by the machine interpreters. Unicode designates the legacy control characters U+0009 through U+000D and U+0085 as whitespace characters, as well as all characters whose General Category property value is Separator. There are 25 total whitespace characters as of Unicode 17.0.
Grapheme joiners and non-joiners
U+200DZERO WIDTH JOINER and U+200CZERO WIDTH NON-JOINER control the joining and ligation of glyphs. The joiner does not cause characters that would not otherwise join or ligate to do so, but when paired with the non-joiner these characters can be used to control the joining and ligating properties of the surrounding two joining or ligating characters. The U+034F͏COMBINING GRAPHEME JOINER is used to distinguish two base characters as one common base or digraph, mostly for underlying text processing, collation of strings, case folding and so on.
Word joiners and separators
The most common word separator is U+0020SPACE. However, there are other word joiners and separators that also indicate a break between words and participate in line-breaking algorithms. U+00A0NO-BREAK SPACE also produces a baseline advance without a glyph but inhibits rather than enabling a line-break. The U+200BZERO WIDTH SPACE allows a line-break but provides no space: in a sense joining, rather than separating, two words. Finally, U+2060WORD JOINER inhibits line breaks and also involves none of the white space produced by a baseline advance.
Baseline advance
No baseline advance
Allow line-break (Separators)
U+0020SPACE
U+200BZERO WIDTH SPACE
Inhibit line-break (Joiners)
U+00A0NO-BREAK SPACE
U+2060WORD JOINER
Other separators
Line Separator (U+2028)
Paragraph Separator (U+2029)
These provide Unicode with native paragraph and line separators independent of the legacy encoded ASCII control characters such as carriage return (U+000A), linefeed (U+000D), and Next Line (U+0085). Unicode does not provide for other ASCII formatting control characters which presumably then are not part of the Unicode plain text processing model. These legacy formatting control characters include U+0009<control-0009> (TAB), U+000B<control-000B> (VERTICAL TAB), and Form Feed (U+000C) which is also thought of as a page break.
The space character (U+0020) typically input by the space bar on a keyboard serves semantically as a word separator in many languages. For legacy reasons, the UCS also includes spaces of varying sizes that are compatibility equivalents for the space character. While these spaces of varying width are important in typography, the Unicode processing model calls for such visual effects to be handled by rich text, markup and other such protocols. They are included in the Unicode repertoire primarily to handle lossless roundtrip transcoding from other character set encodings. These spaces include:
U+2000EN QUAD
U+2001EM QUAD
U+2002EN SPACE
U+2003EM SPACE
U+2004THREE-PER-EM SPACE
U+2005FOUR-PER-EM SPACE
U+2006SIX-PER-EM SPACE
U+2007FIGURE SPACE
U+2008PUNCTUATION SPACE
U+2009THIN SPACE
U+200AHAIR SPACE
U+205FMEDIUM MATHEMATICAL SPACE
Aside from the original ASCII space, the other spaces are all compatibility characters. In this context this means that they effectively add no semantic content to the text, but instead provide styling control. Within Unicode, this non-semantic styling control is often referred to as rich text and is outside the thrust of Unicode's goals. Rather than using different spaces in different contexts, this styling should instead be handled through intelligent text layout software.
Three other writing-system-specific word separators are:
U+180EMONGOLIAN VOWEL SEPARATOR
U+3000IDEOGRAPHIC SPACE: behaves as an ideographic separator and generally rendered as white space of the same width as an ideograph.
U+1680OGHAM SPACE MARK: this character is sometimes displayed with a glyph and other times as only white space.
Line-break control characters
Several characters are designed to help control line-breaks either by discouraging them (no-break characters) or suggesting line breaks such as the soft hyphen (U+00AD) (sometimes called the "shy hyphen"). Such characters, though designed for styling, are probably indispensable for the intricate types of line-breaking they make possible.
Break inhibiting
U+2011‑NON-BREAKING HYPHEN
U+00A0NO-BREAK SPACE
U+0F0C༌TIBETAN MARK DELIMITER TSHEG BSTAR
U+202FNARROW NO-BREAK SPACE
The break inhibiting characters are meant to be equivalent to a character sequence wrapped in the Word Joiner U+2060. However, the Word Joiner may be appended before or after any character that would allow a line-break to inhibit such line-breaking.
Break enabling
U+00ADSOFT HYPHEN
U+0F0B་TIBETAN MARK INTERSYLLABIC TSHEG
U+200BZERO WIDTH SPACE
Both the break inhibiting and break enabling characters participate with other punctuation and whitespace characters to enable text imaging systems to determine line breaks within the Unicode Line Breaking Algorithm.[8]
Types of code point
All code points given some kind of purpose or use are considered designated code points. Of those, they may be assigned to an abstract character, or otherwise designated for some other purpose.
Assigned characters
The majority of code points in actual use have been assigned to abstract characters. This includes private-use characters, which though not formally designated by the Unicode standard for a particular purpose, require a sender and recipient to have agreed in advance how they should be interpreted for meaningful information interchange to take place.
The UCS includes 137,468 private-use characters, which are code points for private use spread across three different blocks, each called a Private Use Area (PUA). The Unicode standard recognizes code points within PUAs as legitimate Unicode character codes, but does not assign them any (abstract) character. Instead, individuals, organizations, software vendors, operating system vendors, font vendors and communities of end-users are free to use them as they see fit. Within closed systems, characters in the PUA can operate unambiguously, allowing such systems to represent characters or glyphs not defined in Unicode.[9] In public systems their use is more problematic, since there is no registry and no way to prevent several organizations from adopting the same code points for different purposes. One example of such a conflict is Apple's use of U+F8FF for the Apple logo, versus the ConScript Unicode Registry's use of U+F8FF as klingon mummification glyph in the Klingon script.[10]
The Basic Multilingual Plane (Plane 0) contains 6,400 private-user characters in the eponymously named PUA Private Use Area, which ranges from U+E000 to U+F8FF. The Private Use Planes, Plane 15 and Plane 16, each have their own PUAs of 65,534 private-use characters (with the final two code points of each plane being noncharacters). These are Supplementary Private Use Area-A, which ranges from U+F0000 to U+FFFFD, and Supplementary Private Use Area-B, which ranges from U+100000 to U+10FFFD.
PUAs are a concept inherited from certain Asian encoding systems. These systems had private use areas to encode what the Japanese call gaiji (rare characters not normally found in fonts) in application-specific ways.
Surrogates
The UCS uses surrogates to address characters outside the initial Basic Multilingual Plane without resorting to more-than-16-bit-word representations.[11] There are 1024 "high" surrogates (D800–DBFF) and 1024 "low" surrogates (DC00–DFFF). By combining a pair of surrogates, the remaining characters in all the other planes can be addressed (1024 × 1024 = 1,048,576 code points in the other 16 planes). In UTF-16, they must always appear in pairs, as a high surrogate followed by a low surrogate, thus using 32 bits to denote one code point.
A surrogate pair denotes the code point
1000016 + (H − D80016) × 40016 + (L − DC0016)
where H and L are the numeric values of the high and low surrogates respectively.[12]
Since high surrogate values in the range DB80–DBFF always produce values in the Private Use planes, the high surrogate range can be further divided into (normal) high surrogates (D800–DB7F) and "high private use surrogates" (DB80–DBFF).
Isolated surrogate code points have no general interpretation; consequently, no character code charts or names lists are provided for this range. In the Python programming language, individual surrogate codes are used to embed undecodable bytes in Unicode strings.[13]
Noncharacters
The unhyphenated term "noncharacter" refers to 66 code points (labeled <not a character>) permanently reserved for internal use, and therefore guaranteed to never be assigned to a character.[14] Each of the 17 planes has its two ending code points set aside as noncharacters. So, noncharacters are: U+FFFE and U+FFFF on the BMP, U+1FFFE and U+1FFFF on Plane 1, and so on, up to U+10FFFE and U+10FFFF on Plane 16, for a total of 34 code points. In addition, there is a contiguous range of another 32 noncharacter code points in the BMP, located in Arabic Presentation Forms-A: U+FDD0..U+FDEF. Software implementations are free to use these code points for internal use. One particularly useful example of a noncharacter is the code point U+FFFE. This code point has the reverse UTF-16/UCS-2 byte sequence of the byte order mark (U+FEFF). If a stream of text contains this noncharacter, this is a good indication the text has been interpreted with the incorrect endianness.
Versions of the Unicode standard from 3.1.0 to 6.3.0 claimed that noncharacters "should never be interchanged". Corrigendum #9 of the standard later stated that this was leading to "inappropriate over-rejection", clarifying that noncharacters "are not illegal in interchange nor do they cause ill-formed Unicode text", and removing the original claim.
Reserved code points
All other code points, being those not designated, are referred to as being reserved. These code points may be assigned for a particular use in future versions of the Unicode standard.
Whereas many other character sets assign a character for every possible glyph representation of the character, Unicode seeks to treat characters separately from glyphs. This distinction is not always unambiguous; however, a few examples will help illustrate the distinction. Often two characters may be combined typographically to improve the readability of the text. For example, the three letter sequence "ffi" may be treated as a single glyph. Other character sets would often assign a code point to this glyph in addition to the individual letters: "f" and "i".
In addition, Unicode approaches diacritic modified letters as separate characters that, when rendered, become a single glyph. For example, an "o" with diaeresis: "ö". Traditionally, other character sets assigned a unique character code point for each diacritic modified letter used in each language. Unicode seeks to create a more flexible approach by allowing combining diacritic characters to combine with any letter. This has the potential to significantly reduce the number of active code points needed for the character set. As an example, consider a language that uses the Latin script and combines the diaeresis with the upper- and lower-case letters "a", "o", and "u". With the Unicode approach, only the diaeresis diacritic character needs to be added to the character set to use with the Latin letters: "a", "A", "o", "O", "u", and "U": seven characters in all. A legacy character sets needs to add six precomposed letters with a diaeresis in addition to the six code points it uses for the letters without diaeresis: twelve character code points in total.
Compatibility characters
UCS includes thousands of characters that Unicode designates as compatibility characters. These are characters that were included in UCS in order to provide distinct code points for characters that other character sets differentiate, but would not be differentiated in the Unicode approach to characters.
The chief reason for this differentiation was that Unicode makes a distinction between characters and glyphs. For example, when writing English in a cursive style, the letter "i" may take different forms whether it appears at the beginning of a word, the end of a word, the middle of a word or in isolation. Languages such as Arabic written in an Arabic script are always cursive. Each letter has many different forms. UCS includes 730 Arabic form characters that decompose to just 88 unique Arabic characters. However, these additional Arabic characters are included so that text processing software may translate text from other character sets to UCS and back again without any loss of information crucial for non-Unicode software.
However, for UCS and Unicode in particular, the preferred approach is to always encode or map that letter to the same character no matter where it appears in a word. Then the distinct forms of each letter are determined by the font and text layout software methods. In this way, the internal memory for the characters remains identical regardless of where the character appears in a word. This greatly simplifies searching, sorting and other text processing operations.
Every character in Unicode is defined by a large and growing set of properties. Most of these properties are not part of Universal Character Set. The properties facilitate text processing including collation or sorting of text, identifying words, sentences and graphemes, rendering or imaging text and so on. Below is a list of some of the core properties. There are many others documented in the Unicode Character Database.[15]
Property
Example
Details
Name
LATIN CAPITAL LETTER A
This is a permanent name assigned by the joint cooperation of Unicode and the ISO UCS. A few known poorly chosen names exist and are acknowledged (e.g. U+FE18 PRESENTATION FORM FOR VERTICAL RIGHT WHITE LENTICULAR BRAKCET, which is misspelled – should be BRACKET) but will not be changed, in order to ensure specification stability.[16]
Code Point
U+0041
The Unicode code point is a number also permanently assigned along with the "Name" property and included in the companion UCS. The usual custom is to represent the code point as hexadecimal number with the prefix "U+" in front.
The representative glyphs are provided in code charts.[18]
Script
Latin (Latn)
Each character is part of a certain script. Each script is assigned a 4-letter code, in this case, "Latn" for Latin. There are three special scripts: Unknown (Zyyy) and two Inherited scripts (Zinh and Qaai).
General Category
Lu (Uppercase_Letter)
The general category[19] is expressed as a two-letter sequence such as "Lu" for uppercase letter or "Nd", for decimal digit number.
Combining Class
Not_Reordered (0)
Since diacritics and other combining marks can be expressed with multiple characters in Unicode the "Combining Class" property allows characters to be differentiated by the type of combining character it represents. The combining class can be expressed as an integer between 0 and 255 or as a named value. The integer values allow the combining marks to be reordered into a canonical order to make string comparison of identical strings possible.
Bidirectional Category
Left_To_Right
Indicates the type of character for applying the Unicode bidirectional algorithm.
Bidirectional Mirrored
no
Indicates the character's glyph must be reversed or mirrored within the bidirectional algorithm. Mirrored glyphs can be provided by font makers, extracted from other characters related through the "Bidirectional Mirroring Glyph" property or synthesized by the text rendering system.
Bidirectional Mirroring Glyph
N/A
This property indicates the code point of another character whose glyph can serve as the mirrored glyph for the present character when mirroring within the bidirectional algorithm.
Decimal Digit Value
NaN
For numerals, this property indicates the numeric value of the character. Decimal digits have all three values set to the same value, presentational rich text compatibility characters and other Arabic-Indic non-decimal digits typically have only the latter two properties set to the numeric value of the character while numerals unrelated to Arabic Indic digits such as Roman Numerals or Hanzhou/Suzhou numerals typically have only the "Numeric Value" indicated.
↑Not the official Unicode representative glyph, but merely a representative glyph. To see the official Unicode representative glyph, see the code charts.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.
![.mw-parser-output .hlist dl,.mw-parser-output .hlist ol,.mw-parser-output .hlist ul{margin:0;padding:0}.mw-parser-output .hlist dd,.mw-parser-output .hlist dt,.mw-parser-output .hlist li{margin:0;display:inline}.mw-parser-output .hlist.inline,.mw-parser-output .hlist.inline dl,.mw-parser-output .hlist.inline ol,.mw-parser-output .hlist.inline ul,.mw-parser-output .hlist dl dl,.mw-parser-output .hlist dl ol,.mw-parser-output .hlist dl ul,.mw-parser-output .hlist ol dl,.mw-parser-output .hlist ol ol,.mw-parser-output .hlist ol ul,.mw-parser-output .hlist ul dl,.mw-parser-output .hlist ul ol,.mw-parser-output .hlist ul ul{display:inline}.mw-parser-output .hlist .mw-empty-li{display:none}.mw-parser-output .hlist dt::after{content:": "}.mw-parser-output .hlist dd::after,.mw-parser-output .hlist li::after{content:" * ";font-weight:bold}.mw-parser-output .hlist dd:last-child::after,.mw-parser-output .hlist dt:last-child::after,.mw-parser-output .hlist li:last-child::after{content:none}.mw-parser-output .hlist dd dd:first-child::before,.mw-parser-output .hlist dd dt:first-child::before,.mw-parser-output .hlist dd li:first-child::before,.mw-parser-output .hlist dt dd:first-child::before,.mw-parser-output .hlist dt dt:first-child::before,.mw-parser-output .hlist dt li:first-child::before,.mw-parser-output .hlist li dd:first-child::before,.mw-parser-output .hlist li dt:first-child::before,.mw-parser-output .hlist li li:first-child::before{content:" (";font-weight:normal}.mw-parser-output .hlist dd dd:last-child::after,.mw-parser-output .hlist dd dt:last-child::after,.mw-parser-output .hlist dd li:last-child::after,.mw-parser-output .hlist dt dd:last-child::after,.mw-parser-output .hlist dt dt:last-child::after,.mw-parser-output .hlist dt li:last-child::after,.mw-parser-output .hlist li dd:last-child::after,.mw-parser-output .hlist li dt:last-child::after,.mw-parser-output .hlist li li:last-child::after{content:")";font-weight:normal}.mw-parser-output .hlist ol{counter-reset:listitem}.mw-parser-output .hlist ol>li{counter-increment:listitem}.mw-parser-output .hlist ol>li::before{content:" "counter(listitem)"\a0 "}.mw-parser-output .hlist dd ol>li:first-child::before,.mw-parser-output .hlist dt ol>li:first-child::before,.mw-parser-output .hlist li ol>li:first-child::before{content:" ("counter(listitem)"\a0 "}
.mw-parser-output .navbox{box-sizing:border-box;border:1px solid #a2a9b1;width:100%;clear:both;font-size:88%;text-align:center;padding:1px;margin:1em auto 0}.mw-parser-output .navbox .navbox{margin-top:0}.mw-parser-output .navbox+.navbox,.mw-parser-output .navbox+.navbox-styles+.navbox{margin-top:-1px}.mw-parser-output .navbox-inner,.mw-parser-output .navbox-subgroup{width:100%}.mw-parser-output .navbox-group,.mw-parser-output .navbox-title,.mw-parser-output .navbox-abovebelow{padding:0.25em 1em;line-height:1.5em;text-align:center}.mw-parser-output .navbox-group{white-space:nowrap;text-align:right}.mw-parser-output .navbox,.mw-parser-output .navbox-subgroup{background-color:#fdfdfd;color:inherit}.mw-parser-output .navbox-list{line-height:1.5em;border-color:#fdfdfd}.mw-parser-output .navbox-list-with-group{text-align:left;border-left-width:2px;border-left-style:solid}.mw-parser-output tr+tr>.navbox-abovebelow,.mw-parser-output tr+tr>.navbox-group,.mw-parser-output tr+tr>.navbox-image,.mw-parser-output tr+tr>.navbox-list{border-top:2px solid #fdfdfd}.mw-parser-output .navbox-title{background-color:#ccf;color:inherit}.mw-parser-output .navbox-abovebelow,.mw-parser-output .navbox-group,.mw-parser-output .navbox-subgroup .navbox-title{background-color:#ddf;color:inherit}.mw-parser-output .navbox-subgroup .navbox-group,.mw-parser-output .navbox-subgroup .navbox-abovebelow{background-color:#e6e6ff;color:inherit}.mw-parser-output .navbox-even{background-color:#f7f7f7;color:inherit}.mw-parser-output .navbox-odd{background-color:transparent;color:inherit}.mw-parser-output .navbox .hlist td dl,.mw-parser-output .navbox .hlist td ol,.mw-parser-output .navbox .hlist td ul,.mw-parser-output .navbox td.hlist dl,.mw-parser-output .navbox td.hlist ol,.mw-parser-output .navbox td.hlist ul{padding:0.125em 0}.mw-parser-output .navbox .navbar{display:block;font-size:100%}.mw-parser-output .navbox-title .navbar{float:left;text-align:left;margin-right:0.5em}body.skin--responsive .mw-parser-output .navbox-image img{max-width:none!important}@media print{body.ns-0 .mw-parser-output .navbox{display:none!important}}
.mw-parser-output .legend{page-break-inside:avoid;break-inside:avoid-column}.mw-parser-output .legend-color{display:inline-block;min-width:1.25em;height:1.25em;line-height:1.25;margin:1px 0;text-align:center;border:1px solid black;background-color:transparent;color:black}.mw-parser-output .legend-text{}
Index of predominant national and selected regional or minority scripts
Alphabetic
[L]ogographic
and [S]yllabic
Abjad
Abugida
Latin
Cyrillic
Greek
Armenian
Georgian
Mongolian
Neo-Tifinagh
Osage
Hangul
Hanzi [L]
Kana [S] / Kanji [L]
Hanja [L]
Cherokee [S]
Arabic
Hebrew
North Indic
South Indic
Ethiopic
Thaana
Canadian syllabics
Featural-alphabetic. Limited. Writing systems worldwide.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/6/63/Writing_systems_worldwide.svg/500px-Writing_systems_worldwide.svg.png)