
An alphabet is a standard set of letters written to represent particular sounds in a spoken language. Specifically, letters largely correspond to phonemes as the smallest sound segments that can distinguish one word from another in a given language. Not all writing systems represent language in this way: a syllabary assigns symbols to spoken syllables, while logographies assign symbols to words, morphemes, or other semantic units.
An abjad, also abgad, is a writing system in which only consonants are represented, leaving the vowel sounds to be inferred by the reader. This contrasts with alphabets, which provide graphemes for both consonants and vowels. The term was introduced in 1990 by Peter T. Daniels. Other terms for the same concept include partial phonemic script, segmentally linear defective phonographic script, consonantary, consonant writing, and consonantal alphabet.

An abugida – sometimes also called alphasyllabary, neosyllabary, or pseudo-alphabet – is a segmental writing system in which consonant–vowel sequences are written as units; each unit is based on a consonant letter, and vowel notation is secondary, similar to a diacritical mark. This contrasts with a full alphabet, in which vowels have status equal to consonants, and with an abjad, in which vowel marking is absent, partial, or optional – in less formal contexts, all three types of the script may be termed "alphabets". The terms also contrast them with a syllabary, in which a single symbol denotes the combination of one consonant and one vowel.

The Arabic alphabet, or the Arabic abjad, is the Arabic script as specifically codified for writing the Arabic language. It is written from right-to-left in a cursive style, and includes 28 letters, of which most have contextual letterforms. Unlike the modern Latin alphabet, the script has no concept of letter case. The Arabic alphabet is considered an abjad, with only consonants required to be written; due to its optional use of diacritics to notate vowels, it is considered an impure abjad.
A mater lectionis is any consonant that is used to indicate a vowel, primarily in the writing of Semitic languages such as Arabic, Hebrew and Syriac. The letters that do this in Hebrew are aleph א, he ה, waw ו and yod י, with the latter two in particular being more often vowels than they are consonants. In Arabic, the matres lectionis are ʾalif ا, wāw و and yāʾ ي.
Thaana, Tãna, Taana or Tāna is the present writing system of the Maldivian language spoken in the Maldives. Thaana has characteristics of both an abugida and a true alphabet, with consonants derived from indigenous and Arabic numerals, and vowels derived from the vowel diacritics of the Arabic abjad. Maldivian orthography in Thaana is largely phonemic.
The Phoenician alphabet is an abjad used across the Mediterranean civilization of Phoenicia for most of the 1st millennium BC. It was one of the first alphabets, and attested in Canaanite and Aramaic inscriptions found across the Mediterranean region. In the history of writing systems, the Phoenician script also marked the first to have a fixed writing direction—while previous systems were multi-directional, Phoenician was written horizontally, from right to left. It developed directly from the Proto-Sinaitic script used during the Late Bronze Age, which was derived in turn from Egyptian hieroglyphs.
Ugarit was an ancient port city in northern Syria about 10 kilometers north of modern Latakia. At its height it ruled an area roughly equivalent to the modern Latakia Governorate. It was discovered by accident in 1928 with the Ugaritic texts. Its ruins are often called Ras Shamra after the headland where they lie.

Ugaritic is an extinct Northwest Semitic language known through the Ugaritic texts discovered by French archaeologists in 1928 at Ugarit, including several major literary texts, notably the Baal cycle.
Phoenician is an extinct Canaanite Semitic language originally spoken in the region surrounding the cities of Tyre and Sidon. Extensive Tyro-Sidonian trade and commercial dominance led to Phoenician becoming a lingua franca of the maritime Mediterranean during the Iron Age. The Phoenician alphabet spread to Greece during this period, where it became the source of all modern European scripts.
The Greek alphabet has been used to write the Greek language since the late 9th or early 8th century BC. It was derived from the earlier Phoenician alphabet, and is the earliest known alphabetic script to have developed distinct letters for consonants as well as vowels. In Archaic and early Classical times, the Greek alphabet existed in many local variants, but, by the end of the 4th century BC, the Ionic-based Euclidean alphabet, with 24 letters, ordered from alpha to omega, had become standard throughout the Greek-speaking world and is the version that is still used for Greek writing today.
Ayin is the sixteenth letter of the Semitic scripts, including Phoenician ʿayin 𐤏, Hebrew ʿayinע, Aramaic ʿē 𐡏, Syriac ʿē ܥ, and Arabic ʿaynع.
Aleph is the first letter of the Semitic abjads, including Phoenician ʾālep 𐤀, Hebrew ʾālefא, Aramaic ʾālap 𐡀, Syriac ʾālap̄ ܐ, Arabic ʾalifا, and North Arabian 𐪑. It also appears as South Arabian 𐩱 and Ge'ez ʾälef አ.

The Proto-Sinaitic script is a Middle Bronze Age writing system known from a small corpus of about 30-40 inscriptions and fragments from Serabit el-Khadim in the Sinai Peninsula, as well as two inscriptions from Wadi el-Hol in Middle Egypt. Together with about 20 known Proto-Canaanite inscriptions, it is also known as Early Alphabetic, i.e. the earliest trace of alphabetic writing and the common ancestor of both the Ancient South Arabian script and the Phoenician alphabet, which led to many modern alphabets including the Greek alphabet. According to common theory, Canaanites or Hyksos who spoke a Canaanite language repurposed Egyptian hieroglyphs to construct a different script.
The history of the alphabet goes back to the consonantal writing system used to write Semitic languages in the Levant during the 2nd millennium BC. Nearly all alphabetic scripts used throughout the world today ultimately go back to this Semitic script. Its origins can be traced to the Proto-Sinaitic script that represented the language of Semitic-speaking workers and slaves in Egypt. Unskilled in the complex hieroglyphic system used to write the Egyptian language, which required a large number of pictograms, they selected a small number of those commonly seen in their surroundings to describe the sounds, as opposed to the semantic values, of their own Canaanite language. This script was partly influenced by the older Egyptian hieratic, a cursive script related to Egyptian hieroglyphs. The Semitic alphabet became the ancestor of multiple writing systems across the Middle East, Europe, northern Africa, and South Asia, mainly through Phoenician and the closely related Paleo-Hebrew alphabet, and later Aramaic and the Nabatean—derived from the Aramaic alphabet and developed into the Arabic alphabet—five closely related members of the Semitic family of scripts that were in use during the early 1st millennium BC.
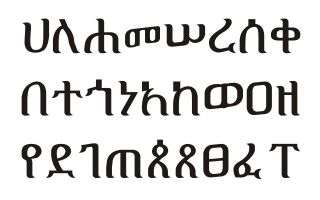
Geʽez is a script used as an abugida (alphasyllabary) for several Afro-Asiatic and Nilo-Saharan languages of Ethiopia and Eritrea. It originated as an abjad and was first used to write the Geʽez language, now the liturgical language of the Ethiopian Orthodox Tewahedo Church, the Eritrean Orthodox Tewahedo Church, the Eritrean Catholic Church, the Ethiopian Catholic Church, and Haymanot Judaism of the Beta Israel Jewish community in Ethiopia. In the languages Amharic and Tigrinya, the script is often called fidäl (ፊደል), meaning "script" or "letter". Under the Unicode Standard and ISO 15924, it is defined as Ethiopic text.

A semi-syllabary is a writing system that behaves partly as an alphabet and partly as a syllabary. The main group of semi-syllabic writing are the Paleohispanic scripts of ancient Spain, a group of semi-syllabaries that transform redundant plosive consonants of the Phoenician alphabet into syllabograms.
Ugaritic is an extinct Northwest Semitic language. This article describes the grammar of the Ugaritic language. For more information regarding the Ugaritic language in general, see Ugaritic language.

The Ugaritic texts are a corpus of ancient cuneiform texts discovered in 1928 in Ugarit and Ras Ibn Hani in Syria, and written in Ugaritic, an otherwise unknown Northwest Semitic language. Approximately 1,500 texts and fragments have been found to date. The texts were written in the 13th and 12th centuries BC.


