"Hanzi" and "Chinese character" redirect here. For the philosopher, see Han Fei. For the anthology attributed to him, see Han Feizi. For the moth species, see Cilix glaucata.
Chinese characters[a] are logographs used to write the Chinese languages and others from regions historically influenced by Chinese culture, including Japan, Korea, and Vietnam. Of the four independently invented writing systems accepted by scholars, they represent the only one that has remained in continuous use. Over a documented history spanning more than three millennia, the function, style, and means of writing characters have changed greatly. Unlike letters in alphabets that reflect the sounds of speech, Chinese characters generally represent morphemes, the units of meaning in a language. Writing all of the frequently used vocabulary in a language requires roughly 2000–3000 characters; as of 2025[update], more than 100000 have been identified and included in The Unicode Standard. Characters are created according to several principles, where aspects of shape and pronunciation may be used to indicate the character's meaning.
The first attested characters are oracle bone inscriptions made during the 13th centuryBCE in what is now Anyang, Henan, as part of divinations conducted by the Shang dynasty royal house. Character forms were originally ideographic or pictographic in style, but evolved as writing spread across China. Numerous attempts have been made to reform the script, including the promotion of small seal script by the Qin dynasty (221–206BCE). Clerical script, which had matured by the early Han dynasty (202BCE–220CE), abstracted the forms of characters—obscuring their pictographic origins in favour of making them easier to write. Following the Han, regular script emerged as the result of cursive influence on clerical script, and has been the primary style used for characters since. Informed by a long tradition of lexicography, states using Chinese characters have standardized their forms—broadly, simplified characters are used to write Chinese in mainland China, Singapore, and Malaysia, while traditional characters are used in Taiwan, Hong Kong, and Macau.
Where the use of characters spread beyond China, they were initially used to write Literary Chinese; they were then often adapted to write local languages spoken throughout the Sinosphere. In Japanese, Korean, and Vietnamese, Chinese characters are known as kanji, hanja, and chữ Hán respectively. Writing traditions also emerged for some of the other languages of China, like the sawndip script used to write the Zhuang languages of Guangxi. Each of these written vernaculars used existing characters to write the language's native vocabulary, as well as the loanwords it borrowed from Chinese. In addition, each invented characters for local use. In written Korean and Vietnamese, Chinese characters have largely been replaced with alphabets—leaving Japanese as the only major non-Chinese language still written using them, alongside the other elements of the Japanese writing system.
At the most basic level, characters are composed of strokes that are written in a fixed order. Historically, methods of writing characters have included inscribing stone, bone, or bronze; brushing ink onto silk, bamboo, or paper; and printing with woodblocks or moveable type. Technologies invented since the 19th century to facilitate the use of characters include telegraph codes and typewriters, as well as input methods and text encodings on computers.
Chinese characters are accepted as representing one of four independent inventions of writing in human history.[b] In each instance, writing evolved from a system using two distinct types of ideographs—either pictographs visually depicting objects or concepts, or fixed signs representing concepts only by shared convention. These systems are classified as proto-writing, because the techniques they used were insufficient to carry the meaning of spoken language by themselves.[3]
Various innovations were required for Chinese characters to emerge from proto-writing. Firstly, pictographs became distinct from simple pictures in use and appearance—for example, the pictograph 大, meaning 'large', was originally a picture of a large man, but one would need to be aware of its specific meaning in order to interpret the sequence 大鹿 as signifying 'large deer', rather than being a picture of a large man and a deer next to one another. Due to this process of abstraction, as well as to make characters easier to write, pictographs gradually became more simplified and regularized—often to the extent that the original objects represented are no longer obvious.[4]
This proto-writing system was limited to representing a relatively narrow range of ideas with a comparatively small library of symbols. This compelled innovations that allowed for symbols which indicated elements of spoken language directly.[5] In each historical case, this was accomplished by some form of the rebus technique, where the symbol for a word is used to indicate a different word with a similar pronunciation, depending on context.[6] This allowed for words that lacked a plausible pictographic representation to be written down for the first time. This technique preempted more sophisticated methods of character creation that would further expand the lexicon. The process whereby writing emerged from proto-writing took place over a long period; when the purely pictorial use of symbols disappeared, leaving only those representing spoken words, the process was complete.[7]
Chinese characters have been used in several different writing systems throughout history. A writing system is most commonly defined to include the written symbols themselves, called graphemes—which may include characters, numerals, or punctuation—as well as the rules by which they are used to record language.[8] Chinese characters are logographs, which are graphemes that represent units of meaning in a language. Specifically, characters represent a language's morphemes, its most basic units of meaning. Morphemes in Chinese—and therefore the characters used to write them—are nearly always a single syllable in length. In some special cases, characters may denote non-morphemic syllables as well; due to this, written Chinese is often characterized as morphosyllabic.[9][c] Logographs may be contrasted with letters in an alphabet, which generally represent phonemes, the distinct units of sound used by speakers of a language.[11] Despite their origins in picture-writing, Chinese characters are no longer ideographs capable of representing ideas directly; their comprehension relies on the reader's knowledge of the particular language being written.[12]
The areas where Chinese characters were historically used—sometimes collectively termed the Sinosphere—have a long tradition of lexicography attempting to explain and refine their use; for most of history, analysis revolved around a model first popularized in the 2nd-century Shuowen Jiezi dictionary.[13] More recent models have analysed the methods used to create characters, how characters are structured, and how they function in a given writing system.[14]
Structural analysis
Most characters can be analysed structurally as compounds made of smaller components (部件; bùjiàn), which are often independent characters in their own right, adjusted to occupy a given position in the compound.[15] Components within a character may serve a specific function—phonetic components provide a hint for the character's pronunciation, and semantic components indicate some element of the character's meaning. Components that serve neither function may be classified as pure signs with no particular meaning, other than their presence distinguishing one character from another.[16]
A straightforward structural classification scheme may consist of three pure classes of semantographs, phonographs, and signs—having only semantic, phonetic, and form components respectively—as well as classes corresponding to each combination of component types.[17] Of the 3500 characters that are frequently used in Standard Chinese, pure semantographs are estimated to be the rarest, accounting for about 5% of the lexicon, followed by pure signs with 18%, and semantic–form and phonetic–form compounds together accounting for 19%. The remaining 58% are phono-semantic compounds.[18]
The 20th-century Chinese palaeographer Qiu Xigui presented three principles of character function adapted from earlier proposals by Tang Lan[zh] and Chen Mengjia,[19] with semantographs describing all characters with forms wholly related to their meaning, regardless of the method by which the meaning was originally depicted; phonographs that include a phonetic component; and loangraphs encompassing existing characters that have been borrowed to write other words. Qiu also acknowledged the existence of character classes that fall outside of these principles, such as pure signs.[20]
Semantographs
Pictographs
Graphical evolution of pictographs
日 ('Sun')
山 ('mountain')
象 ('elephant')
Most of the oldest characters are pictographs (象形; xiàngxíng), representational pictures of physical objects.[21] Examples include 日 ('Sun'), 月 ('Moon'), and 木 ('tree'). Over time, the forms of pictographs have been simplified in order to make them easier to write.[22] As a result, modern readers generally cannot deduce what many pictographs were originally meant to resemble; without knowing the context of their origin in picture-writing, they may be interpreted instead as pure signs. However, if a pictograph's use in compounds still reflects its original meaning, as with 日 in 晴 ('clear sky'), it can still be analysed as a semantic component.[23][24]
Pictographs have often been extended from their original meanings to take on additional layers of metaphor and synecdoche, which sometimes displace the character's original sense. When this process results in excessive ambiguity between distinct senses written with the same character, it is usually resolved by new compounds being derived to represent particular senses.[25]
Indicatives
Indicatives (指事; zhǐshì), also called simple ideographs or self-explanatory characters,[21] are visual representations of abstract concepts that lack any tangible form. Examples include 上 ('up') and 下 ('down')—these characters were originally written as dots placed above and below a line, and later evolved into their present forms with less potential for graphical ambiguity in context.[26] More complex indicatives include 凸 ('convex'), 凹 ('concave'), and 平 ('flat and level').[27]
Compound ideographs
The compound character 好 illustrated as its component characters 女 and 子 positioned side by side
Compound ideographs (会意; 會意; huìyì)—also called logical aggregates, associative idea characters, or syssemantographs—combine other characters to convey a new, synthetic meaning. A canonical example is 明 ('bright'), interpreted as the juxtaposition of the two brightest objects in the sky: 日 ('Sun') and 月 ('Moon'), together expressing their shared quality of brightness. Other examples include 休 ('rest'), composed of pictographs 人 ('man') and 木 ('tree'), and 好 ('good'), composed of 女 ('woman') and 子 ('child').[28]
Many traditional examples of compound ideographs are now believed to have actually originated as phono-semantic compounds, made obscure by subsequent changes in pronunciation.[29] For example, the Shuowen Jiezi describes 信 ('trust') as an ideographic compound of 人 ('man') and 言 ('speech'), but modern analyses instead identify it as a phono-semantic compound—though with disagreement as to which component is phonetic.[30]Peter A. Boodberg and William G. Boltz go so far as to deny that any compound ideographs were devised in antiquity, maintaining that secondary readings that are now lost are responsible for the apparent absence of phonetic indicators,[31] but their arguments have been rejected by other scholars.[32]
Phonographs
Phono-semantic compounds
Phono-semantic compounds (形声; 形聲; xíngshēng) are composed of at least one semantic component and one phonetic component.[33] They may be formed by one of several methods, often by adding a phonetic component to disambiguate a loangraph, or by adding a semantic component to represent a specific extension of a character's meaning.[34] Examples of phono-semantic compounds include 河 (hé; 'river'), 湖 (hú; 'lake'), 流 (liú; 'stream'), 沖 (chōng; 'surge'), and 滑 (huá; 'slippery'). Each of these characters have three short strokes on their left-hand side: 氵, a simplified combining form of ⽔ ('water'). This component serves a semantic function in each example, indicating the character has some meaning related to water. The remainder of each character is its phonetic component: 湖 (hú) is pronounced identically to 胡 (hú) in Standard Chinese, 河 (hé) is pronounced similarly to 可 (kě), and 沖 (chōng) is pronounced similarly to 中 (zhōng).[35]
The phonetic components of most compounds may only provide an approximate pronunciation, even before subsequent sound shifts in the spoken language. Some characters may only have the same initial or final sound of a syllable in common with phonetic components.[36] A phonetic series comprises all the characters created using the same phonetic component, which may have diverged significantly in their pronunciations over time. For example, 茶 (chá; caa4; 'tea') and 途 (tú; tou4; 'route') are characters in the phonetic series using 余 (yú; jyu4), a literary first-person pronoun. Their Old Chinese pronunciations were similar, but the phonetic component no longer serves as a useful hint for their pronunciation in modern varieties of Chinese due to subsequent sound shifts—demonstrated here in both their Mandarin and Cantonese readings.[37]
Loangraphs
The phenomenon of existing characters being adapted to write other words with similar pronunciations was necessary in the initial development of Chinese writing, and has remained common throughout its subsequent history. Some loangraphs (假借; jiǎjiè; 'borrowing') are introduced to represent words previously lacking a written form—this is often the case with abstract grammatical particles such as 之 and 其.[38] The process of characters being borrowed as loangraphs should not be conflated with the distinct process of semantic extension, where a word acquires additional senses, which often remain written with the same character. As both processes often result in a single character form being used to write several distinct meanings, loangraphs are often misidentified as being the result of semantic extension, and vice versa.[39]
Loangraphs are also used to write words borrowed from other languages, such as the Buddhist terminology introduced to China in antiquity, as well as contemporary non-Chinese words and names. For example, each character in the name 加拿大 (Jiānádà; 'Canada') is often used as a loangraph for its respective syllable. However, the barrier between a character's pronunciation and meaning is never total; when transcribing into Chinese, loangraphs are often chosen deliberately as to create certain connotations. This is regularly done with corporate brand names—for example, Coca-Cola's Chinese name is 可口可乐; 可口可樂 (Kěkǒu Kělè; 'delicious enjoyable').[40][41][42]
Signs
Some characters and components are pure signs, with meanings merely stemming from their having a fixed and distinct form. Basic examples of pure signs are found with the numerals beyond four, e.g. 五 ('five') and 八 ('eight'), whose forms do not give visual hints to the quantities they represent.[43]
Traditional Shuowen Jiezi classification
The Shuowen Jiezi is a character dictionary authored c.100CE by the scholar Xu Shen. In its postface, Xu analyses what he sees as all the methods by which characters are created. Later authors iterated upon Xu's analysis, developing a categorization scheme known as the 'six writings' (六书; 六書; liùshū), which identifies every character with one of six categories that had previously been mentioned in the Shuowen Jiezi. For nearly two millennia, this scheme was the primary framework for character analysis used throughout the Sinosphere.[44] Xu based most of his analysis on examples of Qin seal script that were written down several centuries before his time—these were usually the oldest specimens available to him, though he stated he was aware of the existence of even older forms.[45] The first five categories are pictographs, indicatives, compound ideographs, phono-semantic compounds, and loangraphs. The sixth category is given by Xu as 轉注 (zhuǎnzhù; 'reversed and refocused'); however, its definition is unclear, and it is generally disregarded by modern scholars.[46]
Modern scholars agree that the theory presented in the Shuowen Jiezi is problematic, failing to fully capture the nature of Chinese writing, both in the present, as well as at the time Xu was writing.[47] Traditional Chinese lexicography as embodied in the Shuowen Jiezi has suggested implausible etymologies for some characters.[48] Moreover, several categories are considered to be ill-defined—for example, it is unclear whether characters like 大 ('large') should be classified as pictographs or indicatives.[34] However, awareness of the 'six writings' model has remained a common component of character literacy, and often serves as a tool for students memorizing characters.[49]
Diagram comparing the abstraction of pictographs in cuneiform, Egyptian hieroglyphs, and Chinese characters–from an 1870 publication by French Egyptologist Gaston Maspero
The broadest trend in the evolution of Chinese characters over their history has been simplification, both in graphical shape (字形; zìxíng), the "external appearances of individual graphs", and in graphical form (字体; 字體; zìtǐ), "overall changes in the distinguishing features of graphic[al] shape and calligraphic style, ... in most cases refer[ring] to rather obvious and rather substantial changes".[50] The traditional notion of an orderly procession of script styles, each suddenly appearing and displacing the one previous, has been disproven by later scholarship and archaeological work. Instead, scripts evolved gradually, with several distinct styles often coexisting within a given area.[51]
Traditional invention narrative
Several of the Chinese classics indicate that knotted cords were used to keep records prior to the invention of writing.[52] Works that reference the practice include chapter 80 of the Tao Te Ching[B] and the "XiciII" commentary to the I Ching.[C] According to one tradition, Chinese characters were invented during the 3rd millenniumBCE by Cangjie, a scribe of the legendary Yellow Emperor. Cangjie is said to have invented symbols called 字 (zì) due to his frustration with the limitations of knotting, taking inspiration from his study of the tracks of animals, landscapes, and the stars in the sky. On the day that these first characters were created, grain rained down from the sky; that night, the people heard the wailing of ghosts and demons, lamenting that humans could no longer be cheated.[53][54]
Collections of graphs and pictures have been discovered at the sites of several Neolithic settlements throughout the Yellow River valley, including Jiahu (c.6500BCE), Dadiwan and Damaidi (6th millenniumBCE), and Banpo (5th millenniumBCE). Symbols at each site were inscribed or drawn onto artefacts, appearing one at a time and without indicating any greater context. Qiu concluded, "We simply possess no basis for saying that they were already being used to record language."[55] A historical connection with the symbols used by the late Neolithic Dawenkou culture (c.4300– c.2600BCE) in Shandong has been deemed possible by palaeographers, with Qiu concluding that they "cannot be definitively treated as primitive writing, nevertheless they are symbols which resemble most the ancient pictographic script discovered thus far in China...They undoubtedly can be viewed as the forerunners of primitive writing."[56]
Ox scapula inscribed with characters recording the result of divinations–dated c.1200BCE
The oldest attested Chinese writing comprises a body of inscriptions produced during the Late Shang period (c.1250–1050BCE), with the very earliest examples from the reign of Wu Ding dated between 1250 and 1200BCE.[57] Many of these inscriptions were made on oracle bones—usually either ox scapulae or turtle plastrons—and recorded official divinations carried out by the Shang royal house. Contemporaneous inscriptions in a related but distinct style were also made on ritual bronze vessels. This oracle bone script (甲骨文; jiǎgǔwén) was first documented in 1899, after specimens were discovered being sold as "dragon bones" for medicinal purposes, with the symbols carved into them identified as early character forms. By 1928, the source of the bones had been traced to a village near Anyang in Henan—discovered to be the site of Yin, the final Shang capital—which was excavated by a team led by Li Ji from the Academia Sinica between 1928 and 1937.[58] To date, over 150000 oracle bone fragments have been found.[59]
Oracle bone inscriptions recorded divinations undertaken to communicate with the spirits of royal ancestors. The inscriptions range from a few characters in length at their shortest, to several dozen at their longest. The Shang king would communicate with his ancestors by means of scapulimancy, inquiring about subjects such as the royal family, military success, and the weather. Inscriptions were made in the divination material itself before and after it had been cracked by exposure to heat; they generally include a record of the questions posed, as well as the answers as interpreted in the cracks.[60][61] A minority of bones feature characters that were inked with a brush before their strokes were incised; the evidence of this also shows that the conventional stroke orders used by later calligraphers had already been established for many characters by this point.[62]
Oracle bone script is the direct ancestor of later forms of written Chinese. The oldest known inscriptions already represent a well-developed writing system, which suggests an initial emergence predating the late 2nd millenniumBCE. Although written Chinese is first attested in official divinations, it is widely believed that writing was also used for other purposes during the Shang, but that the media used in other contexts—likely bamboo and wooden slips—were less durable than bronzes or oracle bones, and have not been preserved.[63]
The Shi Qiang pan, a bronze ritual basin bearing inscriptions describing the deeds and virtues of the first seven Zhou kings–dated c.900BCE[64]
As early as the Shang, the oracle bone script existed as a simplified form alongside another that was used in bamboo books, in addition to elaborate pictorial forms often used in clan emblems. These other forms have been preserved in bronze script (金文; jīnwén), where inscriptions were made using a stylus in a clay mould, which was then used to cast ritual bronzes.[65] These differences in technique generally resulted in character forms that were less angular in appearance than their oracle bone script counterparts.[66]
Study of these bronze inscriptions has revealed that the mainstream script underwent slow, gradual evolution during the late Shang, which continued during the Zhou dynasty (c.1046–256BCE) until assuming the form now known as small seal script (小篆; xiǎozhuàn) within the Zhou state of Qin.[67][68] Other scripts in use during the late Zhou include the bird-worm seal script (鸟虫书; 鳥蟲書; niǎochóngshū), as well as the regional forms used in non-Qin states. Examples of these styles were preserved as variants in the Shuowen Jiezi.[69] Historically, Zhou forms were collectively known as large seal script (大篆; dàzhuàn), though Qiu refrained from using this term due to its lack of precision.[70]
Following Qin's conquest of the other Chinese states that culminated in the founding of the imperial Qin dynasty in 221BCE, the Qin small seal script was standardized for use throughout the entire country under the direction of Chancellor Li Si.[71] It was traditionally believed that Qin scribes only used small seal script, and the later clerical script was a sudden invention during the early Han. However, more than one script was used by Qin scribes—a rectilinear vulgar style had also been in use in Qin for centuries prior to the wars of unification. The popularity of this form grew as writing became more widespread.[72]
By the Warring States period (c.475–221BCE), an immature form of clerical script (隶书; 隸書; lìshū) had emerged based on the vulgar form developed within Qin, often called "early clerical" or "proto-clerical".[73] The proto-clerical script evolved gradually; by the Han dynasty (202BCE–220CE), it had arrived at a mature form, also called 八分 (bāfēn). Bamboo slips discovered during the late 20th century point to this maturation being completed during the reign of Emperor Wu of Han (r.141–87BCE). This process, called libian (隶变; 隸變), involved character forms being mutated and simplified, with many components being consolidated, substituted, or omitted. In turn, the components themselves were regularized to use fewer, straighter, and more well-defined strokes. As a result, clerical script largely lacks the pictorial qualities still evident in seal script.[74]
Around the midpoint of the Eastern Han (25–220CE), a simplified and easier form of clerical script appeared, which Qiu termed 'neo-clerical' (新隶体; 新隸體; xīnlìtǐ).[75] By the end of the Han, this had become the dominant script used by scribes, though clerical script remained in use for formal works, such as engraved stelae. Qiu described neo-clerical as a transitional form between clerical and regular script which remained in use through the Three Kingdoms period (220–280CE) and beyond.[76]
Cursive and semi-cursive
Cursive script
Cursive script (草书; 草書; cǎoshū) was in use as early as 24BCE, synthesizing elements of the vulgar writing that had originated in Qin with flowing cursive brushwork. By the Jin dynasty (266–420), the Han cursive style became known as 章草 (zhāngcǎo; 'orderly cursive'), sometimes known in English as 'clerical cursive', 'ancient cursive', or 'draft cursive'. Some attribute this name to the fact that the style was considered more orderly than a later form referred to as 今草 (jīncǎo; 'modern cursive'), which had first emerged during the Jin and was influenced by semi-cursive and regular script. This later form was exemplified by the work of figures like Wang Xizhi (fl.4thcentury), who is often regarded as the most important calligrapher in Chinese history.[77][78]
Semi-cursive script
An early form of semi-cursive script (行书; 行書; xíngshū; 'running script') can be identified during the late Han, with its development stemming from a cursive form of neo-clerical script. Liu Desheng (刘德升; 劉德升; fl.2nd centuryCE) is traditionally recognized as the inventor of the semi-cursive style, though accreditations of this kind often indicate a given style's early masters, rather than its earliest practitioners. Later analysis has suggested popular origins for semi-cursive, as opposed to it being an invention of Liu.[79] It can be characterized partly as the result of clerical forms being written more quickly, without formal rules of technique or composition—what would be discrete strokes in clerical script frequently flow together instead. The semi-cursive style is commonly adopted in contemporary handwriting.[80]
Page from a Song-era publication printed using a regular script style
Regular script (楷书; 楷書; kǎishū), based on clerical and semi-cursive forms, is the predominant form in which characters are written and printed.[81] Its innovations have traditionally been credited to the calligrapher Zhong Yao, who lived in the state of Cao Wei (extant 220–266); he is often called the "father of regular script".[82] The earliest surviving writing in regular script comprises copies of Zhong Yao's work, including at least one copy by Wang Xizhi. Characteristics of regular script include the 'pause' (頓; dùn) technique used to end horizontal strokes, as well as heavy tails on diagonal strokes made going down and to the right. It developed further during the Eastern Jin (317–420) in the hands of Wang Xizhi and his son Wang Xianzhi.[83] However, most Jin-era writers continued to use neo-clerical and semi-cursive styles in their daily writing. It was not until the Northern and Southern period (420–589) that regular script became the predominant form.[84] The system of imperial examinations for the civil service established during the Sui dynasty (581–618) required test takers to write in Literary Chinese using regular script, which contributed to the prevalence of both throughout later Chinese history.[85]
Structure
Each character of a text is written within a uniform square allotted for it. As part of the evolution from seal script into clerical script, character components became regularized as discrete series of strokes (笔画; 筆畫; bǐhuà).[86] Strokes can be considered both the basic unit of handwriting, as well as the writing system's basic unit of graphemic organization. In clerical and regular script, individual strokes traditionally belong to one of eight categories according to their technique and graphemic function. In what is known as the Eight Principles of Yong, calligraphers practise their technique using the character 永 (yǒng; 'eternity'), which can be written with one stroke of each type.[87] In ordinary writing, 永 is now written with five strokes instead of eight, and a system of five basic stroke types is commonly employed in analysis—with certain compound strokes treated as sequences of basic strokes made in a single motion.[88]
Characters are constructed according to predictable visual patterns. Some components have distinct combining forms when occupying specific positions within a character—for example, the ⼑ ('knife') component appears as 刂 on the right side of characters, but as ⺈ at the top of characters.[89] The order in which components are drawn within a character is fixed. The order in which the strokes of a component are drawn is also largely fixed, but may vary according to several different standards.[90][91] This is summed up in practice with a few rules of thumb, including that characters are generally assembled from left to right, then from top to bottom, with "enclosing" components started before, then closed after, the components they enclose.[92] For example, 永 is drawn in the following order:
Variants of the Chinese character for 'turtle', collected c.1800 from printed sources. The traditional form 龜 (left) is used in Taiwan and Hong Kong. The simplified form 龟 (not pictured) is used in mainland China, and the simplified form 亀 (also not pictured) is used in Japan.
Over a character's history, variant character forms (异体字; 異體字; yìtǐzì) emerge via several processes. Variant forms have distinct structures, but represent the same morpheme; as such, they can be considered instances of the same underlying character. This is comparable to visually distinct double-storey |a| and single-storey |ɑ| forms both representing the Latin letter ⟨A⟩. Variants also emerge for aesthetic reasons, to make handwriting easier, or to correct what the writer perceives to be errors in a character's form.[93] Individual components may be replaced with visually, phonetically, or semantically similar alternatives.[94] The boundary between character structure and style—and thus whether forms represent different characters, or are merely variants of the same character—is often non-trivial or unclear.[95]
For example, prior to the Qin dynasty the character meaning 'bright' was written as either 明 or 朙—with either 日 ('Sun') or 囧 ('window') on the left, and 月 ('Moon') on the right. As part of the Qin programme to standardize small seal script across China, the 朙 form was promoted. Some scribes ignored this, and continued to write the character as 明. However, the increased usage of 朙 was followed by the proliferation of a third variant: 眀, with 目 ('eye') on the left—likely derived as a contraction of 朙. Ultimately, 明 became the character's standard form.[96]
From the earliest inscriptions until the 20th century, texts were generally laid out vertically—with characters written from top to bottom in columns, arranged from right to left. Word boundaries are generally not indicated with spaces. A horizontal writing direction—with characters written from left to right in rows, arranged from top to bottom—only became predominant in the Sinosphere during the 20th century as a result of Western influence.[97] Many publications outside mainland China continue to use the traditional vertical writing direction.[98] Western influence also resulted in the generalized use of punctuation being widely adopted in print during the 19th and 20th centuries. Prior to this, the context of a passage was considered adequate to guide readers; this was enabled by characters being easier to read than alphabets when written without spaces or punctuation due to their more discretized shapes.[99]
Methods of writing
Ordinary handwriting on a lunch menu in Hong Kong. Here, 反 (fǎn) is being used as an unofficial short form of 飯 (fàn; 'meal') by omitting the latter's ⾷ ('eat') component.
The earliest attested Chinese characters were carved into bone, or marked using a stylus in clay moulds used to cast ritual bronzes. Characters have also been incised into stone, or written in ink onto slips of silk, wood, and bamboo. The invention of paper for use as a writing medium occurred during the 1st centuryCE, and is traditionally credited to Cai Lun.[100] There are numerous styles, or scripts (书; 書; shū) in which characters can be written, including the historical forms like seal script and clerical script. Most styles used throughout the Sinosphere originated within China, though they may display regional variation. Styles that have been created outside of China tend to remain localized in their use—these include the Japanese edomoji and Vietnamese lệnh thư scripts.[101]
Chinese calligraphy of mixed styles by the Song-era poet Mi Fu
Calligraphy was traditionally one of the four arts to be mastered by Chinese scholars, considered to be an artful means of expressing thoughts and teachings. Chinese calligraphy typically makes use of an ink brush to write characters. Strict regularity is not required, and character forms may be accentuated to evoke a variety of aesthetic effects.[102] Traditional ideals of calligraphic beauty often tie into broader philosophical concepts native to East Asia. For example, aesthetics can be conceptualized using the framework of yin and yang, where the extremes of any number of mutually reinforcing dualities are balanced by the calligrapher—such as the duality between strokes made quickly or slowly, between applying ink heavily or lightly, between characters written with symmetrical or asymmetrical forms, and between characters representing concrete or abstract concepts.[103]
Woodblock printing was invented in China between the 6th and 9th centuries,[104] followed by the invention of moveable type by Bi Sheng during the 11th century.[105] The increasing use of print during the Ming (1368–1644) and Qing dynasties (1644–1912) led to considerable standardization in character forms, which prefigured later script reforms during the 20th century. This print orthography, exemplified by the 1716 Kangxi Dictionary, was later dubbed the jiu zixing ('old character shapes').[106] Printed Chinese characters may use different typefaces,[107] of which there are four broad classes in use:[108]
Song (宋体; 宋體) or Ming (明体; 明體) typefaces—with "Song" generally used with simplified Chinese typefaces, and "Ming" with others—broadly correspond to Western serif styles. Song typefaces are broadly within the tradition of historical Chinese print; both names for the style refer to eras regarded as high points for printing in the Sinosphere. While type during the Song dynasty (960–1279) generally resembled the regular script style of a particular calligrapher, most modern Song typefaces are intended for general purpose use and emphasize neutrality in their design.
Sans-serif typefaces are called 'black form' (黑体; 黑體; hēitǐ) in Chinese and 'Gothic' (ゴシック体) in Japanese. Sans-serif strokes are rendered as simple lines of even thickness.
Before computers became ubiquitous, earlier electro-mechanical communications devices like telegraphs and typewriters were originally designed for use with alphabets, often by means of alphabetic text encodings like Morse code and ASCII. Adapting these technologies for a writing system that uses thousands of distinct characters was non-trivial.[109][110]
Chinese IME displaying candidates based on pinyin spelling
Chinese characters are predominantly input on computers using a standard keyboard. Many input methods (IMEs) are phonetic, where typists enter characters according to schemes like pinyin or bopomofo for Mandarin, Jyutping for Cantonese, or Hepburn for Japanese. For example, 香港 ('Hong Kong') could be input as xiang1gang3 using pinyin, or as hoeng1gong2 using Jyutping.[111]
Character input methods may also be based on form, using the shape of characters and existing rules of handwriting to assign unique codes to each character, potentially increasing the speed of typing. Popular form-based input methods include Wubi on the mainland, and Cangjie—named after the mythological inventor of writing—in Taiwan and Hong Kong.[111] Often, unnecessary parts are omitted from the encoding according to predictable rules. For example, 疆 ('border') is encoded using the Cangjie method as NGMWM, which corresponds to the components 弓土一田一.[112]
Contextual constraints may be used to improve candidate character selection. When ignoring tones, 知道 and 直刀 are both transcribed as zhidao; the system may prioritize which candidate appears first based on context.[113]
While special text encodings for Chinese characters were introduced prior to its popularization, The Unicode Standard is the predominant text encoding worldwide.[114] According to the philosophy of the Unicode Consortium, each distinct graph is assigned a number in the standard, but specifying its appearance or the particular allograph used is a choice made by the engine rendering the text.[F] Unicode's Basic Multilingual Plane (BMP) represents the standard's 216 smallest code points. Of these, 20992 (or 32%) are assigned to CJK Unified Ideographs, a designation comprising characters used in each of the Chinese family of scripts. As of version 17.0, published in 2025, Unicode defines a total of 102998 Chinese characters.[G]
Writing first emerged during the historical stage of the Chinese language known as Old Chinese. Most characters correspond to morphemes that originally functioned as stand-alone Old Chinese words.[115]Classical Chinese is the form of written Chinese used in the classic works of Chinese literature from roughly the 5thcenturyBCE until the 2ndcenturyCE.[116] This form of the language was imitated by later authors, even as it began to diverge from the language they spoke. This later form, referred to as Literary Chinese, remained the predominant written language in China until the 20thcentury. Its use in the Sinosphere was loosely analogous to that of Latin in pre-modern Europe.[117] While it was not static over time, Literary Chinese retained many properties of spoken Old Chinese. Informed by the local spoken vernaculars, texts were read aloud using literary and colloquial readings that varied by region.[118] Over time, sound mergers created ambiguities in vernacular speech as more words became homophonic. This ambiguity was often reduced through the introduction of multi-syllable compound words,[119] which comprise much of the vocabulary in modern varieties of Chinese.[120][121]
Over time, use of Literary Chinese spread to neighbouring countries, including Vietnam, Korea, and Japan. Alongside other aspects of Chinese culture, local elites adopted writing for record-keeping, histories, and official communications.[122] Excepting hypotheses by some linguists of the latter two sharing a common ancestor, Chinese, Vietnamese, Korean, and Japanese each belong to different language families,[123] and tend to function differently from one another. Reading systems were devised to enable non-Chinese speakers to interpret Literary Chinese texts in terms of their native language, a phenomenon that has been variously described as either a form of diglossia, as reading by gloss,[124] or as a process of translation into and out of Chinese. Compared to other traditions that wrote using alphabets or syllabaries, the literary culture that developed in this context was less directly tied to a specific spoken language. This is exemplified by the cross-linguistic phenomenon of brushtalk, where mutual literacy allowed speakers of different languages to engage in face-to-face conversations.[125][126]
Following the introduction of Literary Chinese, characters were later adapted to write many non-Chinese languages spoken throughout the Sinosphere. These new writing systems used characters to write both native vocabulary and the numerous loanwords each language had borrowed from Chinese, collectively termed Sino-Xenic vocabulary. Characters may have native readings, Sino-Xenic readings, or both.[127] Comparison of Sino-Xenic vocabulary across the Sinosphere has been useful in the reconstruction of Middle Chinese phonology.[128] Literary Chinese was used in Vietnam during the millennium of Chinese rule that began in 111BCE. By the 15thcentury, a system that adapted characters to write Vietnamese called chữ Nôm had fully matured.[129] The 2ndcenturyBCE is the earliest possible period for the introduction of writing to Korea; the oldest surviving manuscripts in the country date to the early 5thcenturyCE. Also during the 5thcentury, writing spread from Korea to Japan.[130] Characters were being used to write both Korean and Japanese by the 6thcentury.[131] By the late 20thcentury, characters had largely been replaced with alphabets designed to write Vietnamese and Korean. This leaves Japanese as the only major non-Sinitic language typically written using Chinese characters.[132]
Words in Classical Chinese were generally a single character in length.[134] An estimated 25–30% of the vocabulary used in Classical Chinese texts consists of two-character words.[135] Over time, the introduction of multi-syllable vocabulary into vernacular varieties of Chinese was encouraged by phonetic shifts that increased the number of homophones.[136] The most common process of Chinese word formation after the Classical period has been to create compounds of existing words. Words have also been created by appending affixes to words, by reduplication, and by borrowing words from other languages.[137] While multi-syllable words are generally written with one character per syllable, abbreviations are occasionally used.[138] For example, 二十 (èrshí; 'twenty') may be written as the contracted form 廿.[139]
Sometimes, different morphemes come to be represented by characters with identical shapes. For example, 行 may represent either 'road' (xíng) or the extended sense of 'row' (háng)—these morphemes are ultimately cognates that diverged in pronunciation but remained written with the same character. However, Qiu reserved the term homograph to describe identically shaped characters with different meanings that emerge via processes other than semantic extension. An example homograph is 铊; 鉈, which originally meant 'weight used at a steelyard' (tuó). In the 20th century, this character was created again with the meaning 'thallium' (tā). Both of these characters are phono-semantic compounds with ⾦ ('gold') as the semantic component and 它 as the phonetic component, but the words represented by each are not related.[140]
There are a number of 'dialect characters' (方言字; fāngyánzì) that are not used in standard written vernacular Chinese, but reflect the vocabulary of other spoken varieties. The most complete example of an orthography based on a variety other than Standard Chinese is Written Cantonese. A common Cantonese character is 冇 (mou5; 'to not have'), derived by removing two strokes from 有 (jau5; 'to have').[141] It is common to use standard characters to transcribe previously unwritten words in Chinese dialects when obvious cognates exist. When no obvious cognate exists due to factors like irregular sound changes, semantic drift, or an origin in a non-Chinese language, characters are often borrowed or invented to transcribe the word—either ad hoc, or according to existing principles.[142] These new characters are generally phono-semantic compounds.[143]
In Japanese, Chinese characters are referred to as kanji. During the Nara period (710–794), readers and writers of kanbun—the Japanese term for Literary Chinese writing—began utilizing a system of reading techniques and annotations called kundoku. When reading, Japanese speakers would adapt the syntax and vocabulary of Literary Chinese texts to reflect their Japanese-language equivalents. Writing essentially involved the inverse of this process, and resulted in ordinary Literary Chinese.[144] When adapted to write Japanese, characters were used to represent both Sino-Japanese vocabulary loaned from Chinese, as well as the corresponding native synonyms. Most kanji were subject to both borrowing processes, and as a result have both Sino-Japanese and native readings, known as on'yomi and kun'yomi respectively. Moreover, kanji may have multiple readings of either kind. Distinct classes of on'yomi were borrowed into Japanese at different points in time from different varieties of Chinese.[145]
The Japanese writing system is a mixed script, and has also incorporated syllabaries called kana to represent phonetic units called moras, rather than morphemes. Prior to the Meiji era (1868–1912), writers used certain kanji to represent their sound values instead, in a system known as man'yōgana. Starting in the 9th century, specific man'yōgana were graphically simplified to create two distinct syllabaries called hiragana and katakana, which slowly replaced the earlier convention. Modern Japanese retains the use of kanji to represent most word stems, while kana syllabograms are generally used for grammatical affixes, particles, and loanwords. The forms of hiragana and katakana are visually distinct from one another, owing in large part to different methods of simplification—katakana were derived from smaller components of each man'yōgana, while hiragana were derived from the cursive forms of man'yōgana in their entirety. In addition, the hiragana and katakana for some moras were derived from different man'yōgana.[146] Characters invented for Japanese-language use are called kokuji. The methods employed to create kokuji are equivalent to those used by Chinese-original characters, though most are ideographic compounds. For example, 峠 (tōge; 'mountain pass') is a compound kokuji composed of 山 ('mountain'), 上 ('above'), and 下 ('below').[147]
While characters used to write Chinese are monosyllabic, many kanji have multi-syllable readings. For example, the kanji 刀 has a native kun'yomi reading of katana. In different contexts, it can also be read with the on'yomi reading tō, such as in the Chinese loanword 日本刀 (nihontō; 'Japanese sword'), with a pronunciation corresponding to that in Chinese at the time of borrowing. Prior to the universal adoption of katakana, loanwords were typically written with unrelated kanji with on'yomi readings matching the syllables in the loanword. These spellings are called ateji—for example, 亜米利加 (Amerika) was the ateji spelling of 'America', now rendered as アメリカ. As opposed to man'yōgana used solely for their pronunciation, ateji still corresponded to specific Japanese words. Some are still in use, with the official list of jōyō kanji including 106 ateji readings.[148]
Korean
Literary Chinese calligraphy by the 17th- and 18th-century Korean artist and scholar Kim Chŏnghŭi
In Korean, Chinese characters are referred to as hanja. Literary Chinese may have been written in Korea as early as the 2nd centuryBCE. During Korea's Three Kingdoms period (57BCE–668CE), characters were also used to write idu, a form of Korean-language literature that mostly made use of Sino-Korean vocabulary. During the Goryeo period (918–1392), Korean writers developed a system of phonetic annotations for Literary Chinese called gugyeol, comparable to kundoku in Japan, though it only entered widespread use during the later Joseon period (1392–1897).[149] While the hangul alphabet was invented by the Joseon king Sejong in 1443, it was not adopted by the Korean literati and was relegated to use in glosses for Literary Chinese texts until the late 19th century.[150]
Much of the Korean lexicon consists of Chinese loanwords, especially technical and academic vocabulary.[151] While hanja were usually only used to write this Sino-Korean vocabulary, there is evidence that vernacular readings were sometimes used.[128] Compared to the other written vernaculars, very few characters were invented to write Korean words; these are called gukja.[152] During the late 19th and early 20th centuries, Korean was written either using a mixed script of hangul and hanja, or only using hangul.[153] Following the end of the Empire of Japan's occupation of Korea in 1945, the total replacement of hanja with hangul was advocated throughout the country as part of a broader "purification movement" of the national language and culture.[154] However, due to the lack of tones in spoken Korean, there are many Sino-Korean words that are homophones with identical hangul spellings. For example, the phonetic dictionary entry for 기사 (gisa) yields more than 30 different entries. This ambiguity had historically been resolved by also including the associated hanja. While still sometimes used for Sino-Korean vocabulary, it is much rarer for native Korean words to be written using hanja.[155] When learning new characters, Korean students are instructed to associate each one with both its Sino-Korean pronunciation, as well as a native Korean synonym.[156] Examples include:
The first two lines of the 19th-century Vietnamese epic poem The Tale of Kieu, written in both chữ Nôm and the Vietnamese alphabet
Borrowed characters representing Sino-Vietnamese words
Borrowed characters representing native Vietnamese words
Invented chữ Nôm representing native Vietnamese words
In Vietnamese, Chinese characters are referred to as chữ Hán (𡨸漢), chữ Nho (𡨸儒; 'Confucian characters'), or Hán tự (漢字). Literary Chinese was used for all formal writing in Vietnam until the modern era,[157] having first acquired official status in 1010. Literary Chinese written by Vietnamese authors is first attested in the late 10th century, though the local practice of writing is likely several centuries older.[158] Characters used to write Vietnamese called chữ Nôm (𡨸喃) are first attested in an inscription dated to 1209 made at the site of a pagoda.[159] A mature chữ Nôm script had likely emerged by the 13th century, and was initially used to record Vietnamese folk literature. Some chữ Nôm characters are phono-semantic compounds corresponding to spoken Vietnamese syllables.[160] Another technique with no equivalent in China created chữ Nôm compounds using two phonetic components. This was done because Vietnamese phonology included consonant clusters not found in Chinese, and were thus poorly approximated by the sound values of borrowed characters. Compounds used components with two distinct consonant sounds to specify the cluster, e.g. 𢁋 (blăng;[d] 'Moon') was created as a compound of 巴 (ba) and 陵 (lăng).[162] As a system, chữ Nôm was highly complex, and the literacy rate among the Vietnamese population never exceeded 5%.[163] Both Literary Chinese and chữ Nôm fell out of use during the French colonial period, and were gradually replaced by the Latin-based Vietnamese alphabet. Following the end of colonial rule in 1954, the Vietnamese alphabet has been sole official writing system in Vietnam, and is used exclusively in Vietnamese-language media.[164]
Other languages
Several minority languages of South and Southwestern China have been written with scripts using both borrowed and locally created characters. The most well-documented of these is the sawndip script for the Zhuang languages of Guangxi. While little is known about its early development, a tradition of vernacular Zhuang writing likely first emerged during the Tang dynasty (618–907). Modern scholarship characterizes sawndip writing as a network of regional traditions that have mutually influenced one another while maintaining their local characteristics.[165] Like Vietnamese, some invented Zhuang characters are phonetic–phonetic compounds, though not primarily ones intended to describe consonant clusters.[166] Despite the Chinese government encouraging its replacement with a Latin-based Zhuang alphabet, sawndip remains in use.[167] Other non-Sinitic languages of China historically written with Chinese characters include Miao, Yao, Bouyei, Bai, and Hani; each of these are now written with Latin-based alphabets designed for use with each language.[168]
Title page for a 1908 edition of the 13th-century Secret History of the Mongols, which uses Chinese characters to transcribe Mongolian and provides glosses to the right of each column
Between the 10th and 13th centuries, dynasties founded by non-Han peoples in northern China also created scripts for their languages that were inspired by Chinese characters, but did not use them directly—these included the Khitan large script, Khitan small script, Tangut script, and Jurchen script.[169] This has occurred in other contexts as well: Nüshu was a script used by Yao women to write the Xiangnan Tuhua language,[170] and bopomofo (注音符号; 注音符號; zhùyīn fúhào) is a semi-syllabary first invented in 1907[171] to represent the sounds of Standard Chinese;[172] both use forms graphically derived from Chinese characters. Other scripts within China that have adapted some characters but are otherwise distinct include the Geba syllabary used to write the Naxi language, the script for the Sui language, the script for the Yi languages, and the syllabary for the Lisu language.[169]
Chinese characters have also been repurposed phonetically to transcribe the sounds of non-Chinese languages. For example, the only manuscripts of the 13th-century Secret History of the Mongols that have survived from the medieval era use characters in this manner to write the Mongolian language.[173]
The memorization of thousands of different characters is required to achieve literacy in languages written with them, in contrast to the relatively small inventory of graphemes used in phonetic writing.[174] Historically, character literacy was often acquired via Chinese primers like the 6th-century Thousand Character Classic and 13th-century Three Character Classic,[175] as well as surname dictionaries like the Song-era Hundred Family Surnames.[176] Studies of Chinese-language literacy suggest that literate individuals generally have an active vocabulary of three to four thousand characters; for specialists in fields like literature or history, this figure may be between five and six thousand.[177]
The first four characters of the 6th-century Thousand Character Classic in different styles. From right to left: seal script, clerical script, regular script, Song type, and sans-serif type.
According to analyses of mainland Chinese, Taiwanese, Hong Kong, Japanese, and Korean sources, the total number of characters in the modern lexicon is around 15000.[178] Dozens of schemes have been devised for indexing Chinese characters and arranging them in dictionaries, though relatively few have achieved widespread use. Characters may be ordered according to methods based on their meaning, visual structure, or pronunciation.[179]
The Erya (c.3rd centuryBCE) organized the Chinese lexicon into 19 sections according to character meaning, with 3 dealing with everyday vocabulary, and each of the remaining 16 dedicated to specialized vocabulary related to a specific topic.[180] The Shuowen Jiezi (c.100CE) introduced what would ultimately become the predominant method of organization used by later character dictionaries, whereby characters are grouped according to certain visually prominent components called radicals (部首; bùshǒu; 'section headers'). The Shuowen Jiezi used a system of 540 radicals, while subsequent dictionaries have generally used fewer.[181] The set of 214 Kangxi radicals was popularized by the Kangxi Dictionary (1716), but originally appeared in the earlier Zihui (1615).[182] Character dictionaries have historically been indexed using radical-and-stroke sorting, where characters are grouped by radical and sorted within each group by stroke number. Some modern dictionaries arrange character entries alphabetically according to their pinyin spelling, while also providing a traditional radical-based index.[183]
Before the invention of romanization systems for Chinese, the pronunciation of characters was transmitted via rhyme dictionaries. These used the fanqie (反切; 'reverse cut') method, where each entry lists a common character with the same initial sound as the character in question, alongside one with the same final sound.[184]
Neurolinguistics
Using functional magnetic resonance imaging (fMRI), neurolinguists have studied the brain activity associated with literacy. Compared to phonetic systems, reading and writing with characters involves additional areas of the brain—including those associated with visual processing.[185] While the level of memorization required for character literacy is significant, identification of the phonetic and semantic components in compounds—which constitute the vast majority of characters—also plays a key role in reading comprehension. The ease of recognition for a given character is impacted by how regular the positioning of its components is, as well as how reliable its phonetic component is in indicating a specific pronunciation.[186] Moreover, due to the high level of homophony in Chinese languages and the more irregular correspondences between writing and the sounds of speech, it has been suggested that knowledge of orthography plays a greater role in speech recognition for literate Chinese speakers.[187]
Developmental dyslexia in readers of character-based languages appears to involve independent visuospatial and phonological disorders co-occurring. This seems to be a distinct phenomenon from dyslexia as experienced with phonetic orthographies, which can result from only one of the aforementioned disorders.[188]
Reform and standardization
The first official list of simplified character forms, published in 1935 and including 324 characters
Attempts to reform and standardize the use of characters—including aspects of form, stroke order, and pronunciation—have been undertaken by states throughout history. Thousands of simplified characters were standardized and adopted in mainland China during the 1950s and 1960s, with most either already existing as common variants, or being produced via the systematic simplification of their components.[190] After World War II, the Japanese government also simplified hundreds of character forms, including some simplifications distinct from those adopted in China.[191] Orthodox forms that have not undergone simplification are referred to as traditional characters. Across Chinese-speaking polities, mainland China, Malaysia, and Singapore use simplified characters, while Taiwan, Hong Kong, and Macau use traditional characters.[192] In general, Chinese and Japanese readers can successfully identify characters from all three standards.[193]
Prior to the 20th century, reforms were generally conservative and sought to reduce the use of simplified variants.[194] During the late 19th and early 20th centuries, an increasing number of intellectuals in China came to see both the Chinese writing system and the lack of a national spoken dialect as serious impediments to achieving the mass literacy and mutual intelligibility required for the country's successful modernization. Many began advocating for the replacement of Literary Chinese with a written language that more closely reflected speech, as well as for a mass simplification of character forms, or even the total replacement of characters with an alphabet tailored to a specific spoken variety. In 1909, the educator and linguist Lufei Kui formally proposed the adoption of simplified characters in education for the first time.[195]
In 1911, the Xinhai Revolution toppled the Qing dynasty, and resulted in the establishment of the Republic of China the following year. The early Republican era (1912–1949) was characterized by growing social and political discontent that erupted into the 1919 May Fourth Movement, catalysing the replacement of Literary Chinese with written vernacular Chinese over the subsequent decades. Alongside the corresponding spoken variety of Standard Chinese, this written vernacular was promoted by intellectuals and writers such as Lu Xun and Hu Shih.[196] It was based on the Beijing dialect of Mandarin,[197] as well as on the existing body of vernacular literature authored over the preceding centuries, which included classic novels such as Journey to the West (c.1592) and Dream of the Red Chamber (mid-18th century).[198] At this time, character simplification and phonetic writing were being discussed within both the ruling Kuomintang (KMT) party, as well as the Chinese Communist Party (CCP). In 1935, the Republican government published the first official list of simplified characters, comprising 324 forms collated by Peking University professor Qian Xuantong. However, strong opposition within the party resulted in the list being rescinded in 1936.[199]
People's Republic of China
Traditional (們)
Simplified (们)
Comparison between character forms, showing systematic simplification of the component ⾨ ('gate')
The project of script reform in China was ultimately inherited by the Communists, who resumed work following the proclamation of the People's Republic of China in 1949. In 1951, Premier Zhou Enlai ordered the formation of a Script Reform Committee, with subgroups investigating both simplification and alphabetization. The simplification subgroup began surveying and collating simplified forms the following year,[200] ultimately publishing a draft scheme of simplified characters and components in 1956. In 1958, Zhou Enlai announced the government's intent to focus on simplification, as opposed to replacing characters with Hanyu Pinyin, which had been introduced earlier that year.[201] The 1956 scheme was largely ratified by a revised list of 2235 characters promulgated in 1964.[202] The majority of these characters were drawn from conventional abbreviations or ancient forms with fewer strokes.[203] The committee also sought to reduce the total number of characters in use by merging some forms together.[203] For example, 雲 ('cloud') was written as 云 in oracle bone script. The simpler form remained in use as a loangraph meaning 'to say'; it was replaced in its original sense of 'cloud' with a form that added a semantic ⾬ ('rain') component. The simplified forms of these two characters have been merged into 云.[204]
A second round of simplified characters was promulgated in 1977, but was poorly received by the public and quickly fell out of official use. It was ultimately formally rescinded in 1986.[205] The second-round simplifications were unpopular in large part because most of the forms were completely new, in contrast to the familiar variants comprising the majority of the first round.[206] With the rescission of the second round, work toward further character simplification largely came to an end.[207] The Chart of Generally Utilized Characters of Modern Chinese was published in 1988 and included 7000 simplified and unsimplified characters. Of these, half were also included in the revised List of Commonly Used Characters in Modern Chinese, which specified 2500 common characters and 1000 less common characters.[208] In 2013, the List of Commonly Used Standard Chinese Characters was published as a revision of the 1988 lists; it includes a total of 8105 characters.[209]
Regional forms of the character 次 in the Noto Serif typeface family. From left to right: forms used in mainland China, Taiwan, and Hong Kong (top), and in Japan and Korea (bottom)
After World War II, the Japanese government instituted its own program of orthographic reforms. Some characters were assigned simplified forms called shinjitai; the older forms were then labelled kyūjitai. Inconsistent use of different variant forms was discouraged, and lists of characters to be taught to students at each grade level were developed. The first of these was the 1850-character tōyō kanji list published in 1946, later replaced by the 1945-character jōyō kanji list in 1981. In 2010, the jōyō kanji were expanded to include a total of 2136 characters.[210][211] The Japanese government restricts characters that may be used in names to the jōyō kanji, plus an additional list of 983 jinmeiyō kanji whose use are historically prevalent in names.[212][213]
South Korea
Hanja are still used in South Korea, though not to the extent that kanji are used in Japan. In general, there is a trend toward the exclusive use of hangul in ordinary contexts.[214] Characters remain in use in place names, newspapers, and to disambiguate homophones. They are also used in the practice of calligraphy. Use of hanja in education is politically contentious, with official policy regarding the prominence of hanja in curricula having vacillated since the country's independence.[215][216] Some support the total abandonment of hanja, while others advocate an increase in use to levels previously seen during the 1970s and 1980s. Students in grades 7–12 are presently taught with a principal focus on simple recognition and attaining sufficient literacy to read a newspaper.[150] The South Korean Ministry of Education published the Basic Hanja for Educational Use in 1972, which specified 1800 characters meant to be learned by secondary school students.[217] In 1991, the Supreme Court of Korea published the Table of Hanja for Use in Personal Names (인명용 한자; Inmyeong-yong Hanja), which initially included 2854 characters.[218] The list has been expanded several times since; as of 2022[update], it includes 8319 characters.[219]
North Korea
In the years following its establishment, the North Korean government sought to eliminate the use of hanja in standard writing; by 1949, characters had been almost entirely replaced with hangul in North Korean publications.[220] While mostly unused in writing, hanja remain an important part of North Korean education. A 1971 textbook for university history departments contained 3323 distinct characters, and in the 1990s North Korean schoolchildren were still expected to learn 2000 characters.[221] A 2013 textbook appears to integrate the use of hanja in secondary school education.[222] It has been estimated that North Korean students learn around 3000 hanja by the time they graduate university.[223]
Singapore's Ministry of Education promulgated three successive rounds of simplifications. The first round in 1969 included 502 simplified characters, and the second round in 1974 included 2287 simplified characters—including 49 that differed from those in the PRC, which were ultimately removed in the final round in 1976. In 1993, Singapore adopted the revisions made in mainland China in 1986.[225]
↑According to Handel: "While monosyllabism generally trumps morphemicity—that is to say, a bisyllabic morpheme is nearly always written with two characters rather than one—there is an unmistakable tendency for script users to impose a morphemic identity on the linguistic units represented by these characters."[10]
↑This is the Middle Vietnamese pronunciation; the word is pronounced in modern Vietnamese as trăng.[161]
↑改定常用漢字表、30日に内閣告示 閣議で正式決定[The amended list of jōyō kanji receives cabinet notice on 30th: to be officially confirmed in cabinet meeting]. The Nikkei (in Japanese). 24 November 2010.
↑人名用漢字に「渾」追加 司法判断を受け法務省 改正戸籍法施行規則を施行、計863字に["渾" added to kanji usable in personal names; Ministry of Justice enacts revised Family Registration Law Enforcement Regulations following judicial ruling, totaling 863 characters]. The Nikkei (in Japanese). 25 September 2017.
——— (2011). "Literacy and the Emergence of Writing in China". In Li, Feng; Branner, David Prager (eds.). Writing & Literacy in Early China. University of Washington Press. pp.51–84. ISBN978-0-295-80450-7.
Chan, Sin-Wai, ed. (2016). The Routledge Encyclopedia of the Chinese Language. Routledge. ISBN978-1-317-38249-2.
Chen Zhaorong (陳昭容) (2003). 秦系文字研究﹕从漢字史的角度考察[Research on the Qin Writing System: Through the Lens of the History of Writing in China] (in Chinese). Academia Sinica. ISBN978-957-671-995-0.
Cheung Kwan-hin (張系顯); Bauer, Robert S. (2002). "The Representation of Cantonese with Chinese Characters". Journal of Chinese Linguistics Monograph Series (18). ISSN2409-2878. JSTOR23826053.
Demattè, Paola (2022). The Origins of Chinese Writing. Oxford University Press. ISBN978-0-19-763576-6.
Denecke, Wiebke (2014). "Worlds Without Translation: Premodern East Asia and the Power of Character Scripts". In Bermann, Sandra; Porter, Catherine (eds.). A Companion to Translation Studies. Wiley. pp.204–216. ISBN978-0-470-67189-4.
Hannas, William C. (1997). Asia's Orthographic Dilemma. University of Hawaiʻi Press. ISBN978-0-8248-1892-0.
Hung, William (1951). "The Transmission of The Book Known as The Secret History of The Mongols". Harvard Journal of Asiatic Studies. 14 (3/4). Harvard–Yenching Institute: 433–492. JSTOR2718184.
Keightley, David (1978). Sources of Shang History: The Oracle-Bone Inscriptions of Bronze-Age China. University of California Press. ISBN978-0-520-02969-9.
Kin, Bunkyō (2021). King, Ross (ed.). Literary Sinitic and East Asia: A Cultural Sphere of Vernacular Reading. Language, Writing and Literary Culture in the Sinographic Cosmopolis. Vol.3. Translated by King, Ross; Burge, Marjorie; Park, Si Nae; Lushchenko, Alexey; Hattori, Mina. Brill. ISBN978-90-04-43730-2.
Louis, François (2003). "Written Ornament: Ornamental Writing: Birdscript of the Early Han Dynasty and the Art of Enchanting". Ars Orientalis. 33: 18–27. ISSN0571-1371. JSTOR4434272.
McBride, Catherine; Tong, Xiuhong; Mo, Jianhong (2015). "Developmental Dyslexia in Chinese". In Wang, William S.-Y.; Sun, Chaofen (eds.). The Oxford Handbook of Chinese Linguistics. Oxford University Press. ISBN978-0-19-026684-4.
Myers, James (2019). The Grammar of Chinese Characters: Productive Knowledge of Formal Patterns in an Orthographic System. Routledge. ISBN978-1-138-29081-5.
Nawar, Haytham (2020). "Transculturalism and Posthumanism". Language of Tomorrow: Towards a Transcultural Visual Communication System in a Posthuman Condition. Intellect. pp.130–155. ISBN978-1-78938-183-2. JSTORj.ctv36xvqb7.
———; Harbsmeier, Christoph, eds. (1998). Language and Logic. Science and Civilisation in China. Vol.VII:1. Cambridge University Press. ISBN978-0-521-57143-2.
现代汉语[Modern Chinese] (in Chinese). Peking University Modern Chinese Language Teaching and Research Office, The Commercial Press. 2004. ISBN978-7-100-00940-9.
Phan, John (Winter 2013). "Chữ Nôm and the Taming of the South". Journal of Vietnamese Studies. 8 (1). University of California Press: 1–33. doi:10.1525/vs.2013.8.1.1.
Qiu, Xigui (2000) [1988]. Chinese Writing. Early China Special Monograph Series. Vol.4. Translated by Mattos, Gilbert L.; Norman, Jerry. Society for the Study of Early China and The Institute of East Asian Studies, University of California. ISBN978-1-55729-071-7.
——— (2013). 文字学概要[Chinese Writing] (in Chinese) (2nded.). The Commercial Press. ISBN978-7-100-09369-9.
Ramsey, S. Robert (1987). The Languages of China. Princeton University Press. ISBN978-0-691-01468-5.
Sampson, Geoffrey; Chen Zhiqun (陳志群) (2013). "The Reality of Compound Ideographs". Journal of Chinese Linguistics. 41 (2): 255–272. JSTOR23754815.
Shang, Guowen; Zhao, Shouhui (2017). "Standardising the Chinese language in Singapore: Issues of Policy and Practice". Journal of Multilingual and Multicultural Development. 38 (4): 315–329. doi:10.1080/01434632.2016.1201091. ISSN0143-4632.
Tong, Xiuli; Liu, Phil D.; McBride-Chang, Catherine (2009). "Metalinguistic and Subcharacter Skills in Chinese Literacy Acquisition". In Wood, Clare Patricia; Connelly, Vincent (eds.). Contemporary Perspectives on Reading and Spelling. Routledge. pp.202–221. ISBN978-0-415-49716-9– via Google Books.
Vogelsang, Kai (2021). Introduction to Classical Chinese. Oxford University Press. ISBN978-0-19-883497-7.
Xue, Shiqi (1982). "Chinese Lexicography Past and Present". Journal of the Dictionary Society of North America. 4 (1): 151–169. doi:10.1353/dic.1982.0009. ISSN2160-5076.
Yang, Lihui; An, Deming (2008). Handbook of Chinese Mythology. Oxford University Press. ISBN978-0-19-533263-6.
Yang Runlu (杨润陆) (2008). 现代汉字学[Modern Chinese Characters] (in Chinese). Beijing Normal University Press. ISBN978-7-303-09437-0.
Yin Jiming (殷寄明); etal. (2007). 现代汉语文字学[Modern Chinese Writing] (in Chinese). Fudan University Press. ISBN978-7-309-05525-2.
Yip, Po-ching (2000). The Chinese Lexicon: A Comprehensive Survey. Psychology Press. ISBN978-0-415-15174-0.
Yong, Heming; Peng, Jing (2008). Chinese Lexicography: A History from 1046BC to AD1911. Oxford University Press. ISBN978-0-19-156167-2.
Zhang Xiaoheng (张小衡); Li Xiaotong (李笑通) (2013). 一二三笔顺检字手册[Handbook of the YES Sorting Method] (in Chinese). The Language Press. ISBN978-7-80241-670-3.
Zhao, Liming (1998). "Nüshu: Chinese Women's Characters". International Journal of the Sociology of Language. 129 (1): 127–137. doi:10.1515/ijsl.1998.129.127. ISSN0165-2516.
Zhong, Yurou (2019). Chinese Grammatology: Script Revolution and Literary Modernity, 1916–1958. Columbia University Press. doi:10.7312/zhon19262. ISBN978-0-231-54989-9.
——— (2003). The Historical Evolution of Chinese Languages and Scripts中国语文的时代演进. Pathways to Advanced Skills (in English and Chinese). Vol.8. Translated by Zhang Liqing (张立青). National East Asian Languages Resource Center, Ohio State University. ISBN978-0-87415-349-1.
↑Laozi (1891). "80". 道德經[Tao Te Ching] (in Literary Chinese and English). Translated by Legge, James– via the Chinese Text Project. [I would make the people return to the use of knotted cords (instead of the written characters).]
↑係辭下[Xi Ci II]. 易經[I Ching] (in Literary Chinese and English). Translated by Legge, James. 1899 – via the Chinese Text Project. [In the highest antiquity, government was carried on successfully by the use of knotted cords (to preserve the memory of things). In subsequent ages the sages substituted for these written characters and bonds.]
Handel, Zev (2025). Chinese Characters Across Asia: How the Chinese Script Came to Write Japanese, Korean, and Vietnamese. University of Washington Press. ISBN978-0-295-75302-7.
King, Ross, ed. (2023). Cosmopolitan and Vernacular in the World of Wen 文. Language, Writing and Literary Culture in the Sinographic Cosmopolis. Vol.5. Brill. ISBN978-90-04-43769-2.
Simmons, Richard VanNess, ed. (2022). Studies in Colloquial Chinese and Its History: Dialect and Text. Hong Kong University Press. ISBN978-988-8754-09-0.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.




















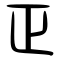


















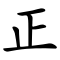









![Ordinary handwriting on a lunch menu in Hong Kong. Here,
Fan (fan) is being used as an unofficial short form of
Fan (fan; 'meal') by omitting the latter's [?]
('eat') component. Dang Dang Cha Can Ting 2021Nian 7Yue Chu De Wu Can Can Pai -tweaked.jpg](http://upload.wikimedia.org/wikipedia/commons/thumb/2/21/%E5%99%B9%E5%99%B9%E8%8C%B6%E9%A4%90%E5%BB%B32021%E5%B9%B47%E6%9C%88%E5%88%9D%E7%9A%84%E5%8D%88%E9%A4%90%E9%A4%90%E7%89%8C-tweaked.jpg/330px-%E5%99%B9%E5%99%B9%E8%8C%B6%E9%A4%90%E5%BB%B32021%E5%B9%B47%E6%9C%88%E5%88%9D%E7%9A%84%E5%8D%88%E9%A4%90%E9%A4%90%E7%89%8C-tweaked.jpg)












