An abjad, also abgad, is a writing system in which only consonants are represented, leaving vowel sounds to be inferred by the reader. This contrasts with alphabets, which provide graphemes for both consonants and vowels. The term was introduced in 1990 by Peter T. Daniels. Other terms for the same concept include partial phonemic script, segmentally linear defective phonographic script, consonantary, consonant writing, and consonantal alphabet.

The Arabic alphabet, or Arabic abjad, is the Arabic script as specifically codified for writing the Arabic language. It is written from right-to-left in a cursive style, and includes 28 letters, of which most have contextual letterforms. The Arabic alphabet is considered an abjad, with only consonants required to be written; due to its optional use of diacritics to notate vowels, it is considered an impure abjad.

A diacritic is a glyph added to a letter or to a basic glyph. The term derives from the Ancient Greek διακριτικός, from διακρίνω. The word diacritic is a noun, though it is sometimes used in an attributive sense, whereas diacritical is only an adjective. Some diacritics, such as the acute ⟨á⟩, grave ⟨à⟩, and circumflex ⟨â⟩, are often called accents. Diacritics may appear above or below a letter or in some other position such as within the letter or between two letters.
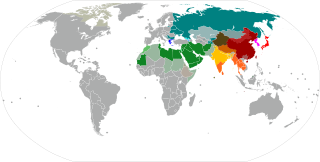
The Brahmic scripts, also known as Indic scripts, are a family of abugida writing systems. They are used throughout the Indian subcontinent, Southeast Asia and parts of East Asia. They are descended from the Brahmi script of ancient India and are used by various languages in several language families in South, East and Southeast Asia: Indo-Aryan, Dravidian, Tibeto-Burman, Mongolic, Austroasiatic, Austronesian, and Tai. They were also the source of the dictionary order (gojūon) of Japanese kana.
The Balinese script, natively known as Aksara Bali and Hanacaraka, is an abugida used in the island of Bali, Indonesia, commonly for writing the Austronesian Balinese language, Old Javanese, and the liturgical language Sanskrit. With some modifications, the script is also used to write the Sasak language, used in the neighboring island of Lombok. The script is a descendant of the Brahmi script, and so has many similarities with the modern scripts of South and Southeast Asia. The Balinese script, along with the Javanese script, is considered the most elaborate and ornate among Brahmic scripts of Southeast Asia.

In writing and typography, a ligature occurs where two or more graphemes or letters are joined to form a single glyph. Examples are the characters ⟨æ⟩ and ⟨œ⟩ used in English and French, in which the letters ⟨a⟩ and ⟨e⟩ are joined for the first ligature and the letters ⟨o⟩ and ⟨e⟩ are joined for the second ligature. For stylistic and legibility reasons, ⟨f⟩ and ⟨i⟩ are often merged to create ⟨fi⟩ ; the same is true of ⟨s⟩ and ⟨t⟩ to create ⟨st⟩. The common ampersand, ⟨&⟩, developed from a ligature in which the handwritten Latin letters ⟨e⟩ and ⟨t⟩ were combined.
Lao script or Akson Lao is the primary script used to write the Lao language and other minority languages in Laos. Its earlier form, the Tai Noi script, was also used to write the Isan language, but was replaced by the Thai script. It has 27 consonants, 7 consonantal ligatures, 33 vowels, and 4 tone marks.
The International Alphabet of Sanskrit Transliteration (IAST) is a transliteration scheme that allows the lossless romanisation of Indic scripts as employed by Sanskrit and related Indic languages. It is based on a scheme that emerged during the 19th century from suggestions by Charles Trevelyan, William Jones, Monier Monier-Williams and other scholars, and formalised by the Transliteration Committee of the Geneva Oriental Congress, in September 1894. IAST makes it possible for the reader to read the Indic text unambiguously, exactly as if it were in the original Indic script. It is this faithfulness to the original scripts that accounts for its continuing popularity amongst scholars.

The ʻokina, also called by several other names, is a consonant letter used within the Latin script to mark the phonemic glottal stop in many Polynesian languages. It does not have distinct uppercase and lowercase forms.
Uniscribe is the Microsoft Windows set of services for rendering Unicode-encoded text, supporting complex text layout. It is implemented in the dynamic link library USP10.DLL. Uniscribe was released with Windows 2000 and Internet Explorer 5.0. In addition, the Windows CE platform has supported Uniscribe since version 5.0.

Fula, also known as Fulani or Fulah, is a Senegambian language spoken by around 36.8 million people as a set of various dialects in a continuum that stretches across some 18 countries in West and Central Africa. Along with other related languages such as Serer and Wolof, it belongs to the Atlantic geographic group within Niger–Congo, and more specifically to the Senegambian branch. Unlike most Niger-Congo languages, Fula does not have tones.
Unicode has subscripted and superscripted versions of a number of characters including a full set of Arabic numerals. These characters allow any polynomial, chemical and certain other equations to be represented in plain text without using any form of markup like HTML or TeX.
Unicode supports several phonetic scripts and notations through its existing scripts and the addition of extra blocks with phonetic characters. These phonetic characters are derived from an existing script, usually Latin, Greek or Cyrillic. Apart from the International Phonetic Alphabet (IPA), extensions to the IPA and obsolete and nonstandard IPA symbols, these blocks also contain characters from the Uralic Phonetic Alphabet and the Americanist Phonetic Alphabet.

Pular (𞤆𞤵𞤤𞤢𞤪) is a Fula language spoken primarily by the Fula people of Fouta Djallon, Guinea. It is also spoken in parts of Guinea-Bissau, Sierra Leone, and Senegal. There are a small number of speakers in Mali. Pular is spoken by 4.3 million Guineans, about 55% of the national population. This makes Pular the most widely spoken indigenous language in the country. Substantial numbers of Pular speakers have migrated to other countries in West Africa, notably Senegal.
New Tai Lue script, also known as Xishuangbanna Dai and Simplified Tai Lue, is an abugida used to write the Tai Lü language. Developed in China in the 1950s, New Tai Lue is based on the traditional Tai Tham alphabet developed c. 1200. The government of China promoted the alphabet for use as a replacement for the older script; teaching the script was not mandatory, however, and as a result many are illiterate in New Tai Lue. In addition, communities in Burma, Laos, Thailand and Vietnam still use the Tai Tham alphabet.

The Latin script, also known as the Roman script, and technically Latin writing system is an alphabetic writing system based on the letters of the classical Latin alphabet, derived from a form of the Greek alphabet which was in use in the ancient Greek city of Cumae, in southern Italy. The Greek alphabet was altered by the Etruscans, and subsequently their alphabet was altered by the Romans. Several Latin-script alphabets exist, which differ in graphemes, collation and phonetic values from the classical Latin alphabet.

The Urdu alphabet is the right-to-left alphabet used for writing Urdu. It is a modification of the Persian alphabet, which itself is derived from the Arabic script. It has official status in the republics of Pakistan, India and South Africa. The Urdu alphabet has up to 39 or 40 distinct letters with no distinct letter cases and is typically written in the calligraphic Nastaʿlīq script, whereas Arabic is more commonly written in the Naskh style.
Standard Sundanese script is a writing system which is used by the Sundanese people. It is built based on Old Sundanese script which was used by the ancient Sundanese from the 14th to the 18th centuries.
The Fula language is written primarily in the Latin script, but in some areas is still written in an older Arabic script called the Ajami script or in the recently invented Adlam script.

