Holy Roman Empire Sacrum Imperium Romanum(Latin) Heiliges Römisches Reich(German)Holy Roman Empire of the German Nation Sacrum Imperium Romanum Nationis Germanicae(Latin) Heiliges Römisches Reich Deutscher Nation(German)
The Holy Roman Empire[e] was a polity in Central and Western Europe, usually headed by the Holy Roman Emperor.[8] It developed in the Early Middle Ages (beginning in either 800 or 962), and lasted for a millennium until its dissolution in 1806 during the Napoleonic Wars.[9] Initially, it comprised three parts—Germany, Italy, and, from 1032, Burgundy—held together by the emperor's overlordship. By the 15th century, imperial governance became concentrated in the Kingdom of Germany, as the empire's effective control over Italy and Burgundy had largely disappeared.[10]
On 25 December 800, Pope Leo III crowned Charlemagne (the Frankish king) Roman emperor, reviving the title more than three centuries after the fall of the Western Roman Empire in 476.[11] The title lapsed in 924 but was revived in 962 when OttoI was crowned emperor by Pope John XII, as Charlemagne's and the Carolingian Empire's successor.[12][13][14][f] From 962 until the 12th century, the empire was one of the most powerful monarchies in Europe.[15] It depended on cooperation between emperors and vassals;[16] this was disturbed during the Salian period.[17] The empire reached the apex of territorial expansion and power under the House of Hohenstaufen in the mid-13th century, but overextension led to a partial collapse.[18][19][20][21][22] The imperial office was traditionally elective by the mostly German prince-electors. In theory and diplomacy, the emperors were considered the first among equals of all of Europe's Catholic monarchs.[23]
A process of Imperial Reform in the late 15th and early 16th centuries transformed the empire, creating a set of institutions which endured until its final demise in the 19th century.[24][25][26][27] On 6 August 1806, Emperor Francis II abdicated and formally dissolved the empire following the creation by French emperor Napoleon of the Confederation of the Rhine from German client states loyal to France. For most of its history, the Empire primarily comprised the entirety of the modern countries of the Czech Republic, the Netherlands, Switzerland, Luxembourg, Liechtenstein, Monaco, Germany, Austria, Slovenia, Belgium, northern and central Italy, and large parts of modern-day eastern France and western Poland.
Initially, following Charlemagne's coronation in 800, the realm was simply referred to as the "Roman Empire".[28] The term sacrum ("holy", in the sense of "consecrated") in connection with the medieval Roman Empire was used beginning in 1157 under Frederick I Barbarossa ("Holy Empire"): the term was added to reflect Frederick's ambition to dominate Italy and the Papacy.[29] The form "Holy Roman Empire" is attested from 1254 onward.[30]
The exact term "Holy Roman Empire" was not in use until the 13th century, before which the empire was referred to variously as universum regnum ("the whole kingdom", as opposed to the regional kingdoms), imperium christianum ("Christian empire"), or Imperium Romanum ("Roman empire"),[22] but the Emperor's legitimacy always rested on the concept of translatio imperii,[g] that he held supreme power inherited from the ancient emperors of Rome.[20]
From the mid-13th century onward, the Holy Roman Empire came to be more firmly associated with a German (deutsch) identity.[31] By around 1500, contemporary sources often referred to it simply as "Germany", reflecting its identification as a specifically German polity.[32] In a decree following the Diet of Cologne in 1512, the name was changed to the "Holy Roman Empire of the German Nation" (German: Heiliges Römisches Reich Deutscher Nation, Latin: Sacrum Imperium Romanum Nationis Germanicae),[28] a form first used in a document in 1474.[29] The adoption of this new name coincided with the loss of imperial territories in Italy and Burgundy to the south and west by the late 15th century,[33] but also to emphasize the new importance of the German Imperial Estates in ruling the Empire due to the Imperial Reform.[34] The Hungarian denomination "German Roman Empire" (Hungarian: Német-római Birodalom) is the shortening of this.[35]
By the end of the 18th century, the term "Holy Roman Empire of the German Nation" fell out of official use. Contradicting the traditional view concerning that designation, Hermann Weisert has argued in a study on imperial titulature that, despite the claims of many textbooks, the name "Holy Roman Empire of the German Nation" never had an official status and points out that documents were thirty times as likely to omit the national suffix as include it.[36] Similarly, Peter Wilson states that "of the German Nation" was "appended more frequently after 1512 without becoming the Empire's official title – despite numerous later claims to the contrary", and that "German historians are far more likely to refer to [the Empire] as 'of the German nation' than were its actual inhabitants."[37] Still, the full name including "of the German Nation" was used in official documents and by contemporary chroniclers alike.[38]
In a famous assessment of the name, the political philosopher Voltaire remarked sardonically: "This body which was called and which still calls itself the Holy Roman Empire was in no way holy, nor Roman, nor an empire."[39] In the modern period, the Empire was often informally called the "German Empire" (Deutsches Reich) or "Roman-German Empire" (Römisch-Deutsches Reich).[40] After its dissolution through the end of the German Empire, it was often called "the old Empire" (das alte Reich). Beginning in 1923, early 20th-century German nationalists and Nazi Party propaganda would identify the Holy Roman Empire as the "First" Reich (Erstes Reich, Reich meaning empire), with the German Empire as the "Second" Reich and what would eventually become Nazi Germany as the "Third" Reich.[41]
David S. Bachrach opines that the Ottonian kings actually built their empire on the back of military and bureaucratic apparatuses as well as the cultural legacy they inherited from the Carolingians, who ultimately inherited these from the Late Roman Empire. He argues that the Ottonian empire was hardly an archaic kingdom of primitive Germans, maintained by personal relationships only and driven by the desire of the magnates to plunder and divide the rewards among themselves but instead, notable for their abilities to amass sophisticated economic, administrative, educational and cultural resources that they used to serve their enormous war machine.[42][43]
Until the end of the 15th century, the empire comprised three major blocks—Germany, Italy and Burgundy.[10] Effectively, the Kingdom of Germany became the sole remaining component.[10] The Burgundian territories were lost to France. Although the Italian territories were formally part of the empire, the territories were ignored in the Imperial Reform and splintered into numerous de facto independent territorial entities.[44][20][27] The status of Italy in particular varied throughout the 16th to 18th centuries. Some territories like Piedmont-Savoy became increasingly independent, while others became more dependent due to the extinction of their ruling noble houses causing these territories to often fall under the dominions of the Habsburgs and their cadet branches. Barring the loss of Franche-Comté in 1678, the external borders of the Empire did not change noticeably from the Peace of Westphalia – which acknowledged the exclusion of Switzerland and the Northern Netherlands, and the French protectorate over Alsace – to the dissolution of the Empire. At the conclusion of the Napoleonic Wars in 1815, most of the Holy Roman Empire was included in the German Confederation, with the main exceptions being the Italian states.
A map of the Carolingian Empire within Europe, c.814 AD
As Roman power in Gaul declined during the 5th century, local Germanic tribes assumed control.[45] In the late 5th and early 6th centuries, the Merovingians, under Clovis I and his successors, consolidated Frankish tribes and extended hegemony over others to gain control of northern Gaul and the middle Rhine river valley region.[46][47] By the middle of the 8th century, the Merovingians were reduced to figureheads, and the Carolingians, led by Charles Martel, became the de facto rulers.[48] In 751, Martel's son Pepin became King of the Franks, and later gained the sanction of the Pope.[49][50] The Carolingians would maintain a close alliance with the Papacy.[51] In 768, Pepin's son Charlemagne became King of the Franks and began an extensive expansion of the realm. He eventually incorporated the territories of present-day France, Germany, northern Italy, the Low Countries and beyond, linking the Frankish kingdom with Papal lands.[52][53]
Although antagonism about the expense of Byzantine domination had long persisted within Italy, a political rupture was set in motion in earnest in 726 by the iconoclasm of Emperor Leo III the Isaurian, in what Pope Gregory II saw as the latest in a series of imperial heresies.[54] In 797, the Eastern Roman Emperor Constantine VI was removed from the throne by his mother, Empress Irene, who declared herself sole ruler. As the Latin Church only regarded a male Roman emperor as the head of Christendom, Pope Leo III sought a new candidate for the dignity, excluding consultation with the patriarch of Constantinople.[55][56]
Charlemagne's good service to the Church in his defense of Papal possessions against the Lombards made him the ideal candidate. On Christmas Day of 800, Pope Leo III crowned Charlemagne emperor, restoring the title in the West for the first time in over three centuries.[55][56] This can be seen as symbolic of the papacy turning away from the declining Byzantine Empire toward the new power of CarolingianFrancia. Charlemagne adopted the formula Renovatio imperii Romanorum ("renewal of the Roman Empire"). In 802, Irene was overthrown and exiled by Nikephoros I and henceforth there were two Roman emperors.
After Charlemagne died in 814, the imperial crown passed to his son, Louis the Pious. Upon Louis' death in 840, it passed to his son Lothair, who had been his co-ruler. By this point the territory of Charlemagne was divided into several territories (cf. Treaty of Verdun, Treaty of Prüm, Treaty of Meerssen and Treaty of Ribemont), and over the course of the later 9th century the title of emperor was disputed by the Carolingian rulers of the Western Frankish Kingdom or West Francia and the Eastern Frankish Kingdom or East Francia, with first the western king (Charles the Bald) and then the eastern (Charles the Fat), who briefly reunited the Empire, attaining the prize.[57]
In the 9th century, Charlemagne and his successors promoted the intellectual revival, known as the Carolingian Renaissance. Some, like Mortimer Chambers,[58] opine that the Carolingian Renaissance made possible the subsequent renaissances (even though by the early 10th century, the revival already diminished).[59] After the death of Charles the Fat in 888, Carolingian rule in the Roman Empire came to an end. According to Regino of Prüm, the parts of the realm "spewed forth kinglets", and each part elected a kinglet "from its own bowels".[57] The last such emperor was Berengar I of Italy, who died in 924.
Post-Carolingian Eastern Frankish Kingdom
Around 900, East Francia's autonomous stem duchies (Franconia, Bavaria, Swabia, Saxony, and Lotharingia) reemerged. After the Carolingian king Louis the Child died without issue in 911, East Francia did not turn to the Carolingian ruler of West Francia to take over the realm but instead elected one of the dukes, Conrad of Franconia, as Rex Francorum Orientalium.[60] On his deathbed, Conrad yielded the crown to his main rival, Henry the Fowler of Saxony (r.919–936), who was elected king at the Diet of Fritzlar in 919.[61] Henry reached a truce with the raiding Magyars, and in 933 he won a first victory against them in the Battle of Riade.[62]
Henry died in 936, but his descendants, the Liudolfing (or Ottonian) dynasty, would continue to rule the Eastern kingdom or the Kingdom of Germany for roughly a century. Upon Henry the Fowler's death, Otto, his son and designated successor,[63] was elected king in Aachen in 936.[64] He overcame a series of revolts from a younger brother and from several dukes. After that, the king managed to control the appointment of dukes and often also employed bishops in administrative affairs.[65] He replaced leaders of most of the major East Frankish duchies with his own relatives. At the same time, he was careful to prevent members of his own family from making infringements on his royal prerogatives.[66][67]
In 951, Otto came to the aid of Queen Adelaide of Italy, defeating her enemies, marrying her, and taking control over Italy.[68] In 955, Otto won a decisive victory over the Magyars in the Battle of Lechfeld.[69] In 962, Otto was crowned emperor by Pope John XII,[69] thus intertwining the affairs of the German kingdom with those of Italy and the Papacy. Otto's coronation as emperor marked the German kings as successors to the empire of Charlemagne, which through the concept of translatio imperii, also made them consider themselves as successors to Ancient Rome. The flowering of arts beginning with Otto the Great's reign is known as the Ottonian Renaissance, centered in Germany but also happening in Northern Italy and France.[70][71]
Otto created the imperial church system, often called "Ottonian church system of the Reich", which tied the great imperial churches and their representatives to imperial service, thus providing "a stable and long-lasting framework for Germany".[72][73] During the Ottonian era, imperial women played a prominent role in political and ecclesiastic affairs, often combining their functions as religious leader and advisor, regent or co-ruler, notably Matilda of Ringelheim, Eadgyth, Adelaide of Italy, Theophanu, and Matilda of Quedlinburg.[74][75][76][77]
In 963, Otto deposed John XII and chose Leo VIII as the new pope (although John XII and Leo VIII both claimed the papacy until 964, when John XII died). This also renewed the conflict with the Byzantine emperor, especially after Otto's son Otto II (r.967–983) adopted the designation imperator Romanorum. Still, Otto II formed marital ties with the east when he married the Byzantine princess Theophanu.[78] Their son, Otto III, came to the throne only three years old, and was subjected to a power struggle and series of regencies until his age of majority in 994. Up to that time, he remained in Germany, while a deposed duke, Crescentius II, ruled over Rome and part of Italy, ostensibly in his stead.
In 996 Otto III appointed his cousin Gregory V the first German pope.[79] A foreign pope and foreign papal officers were seen with suspicion by Roman nobles, who were led by Crescentius II to revolt. Otto III's former mentor Antipope John XVI briefly held Rome, until the Holy Roman emperor seized the city.[80] Otto died young in 1002, and was succeeded by his cousin Henry II, who focused on Germany.[81] Otto III's (and his mentor Pope Sylvester's) diplomatic activities coincided with and facilitated the Christianization and the spread of Latin culture in different parts of Europe.[82][83] They coopted a new group of nations (Slavic) into the framework of Europe, with their empire functioning, as some remark, as a "Byzantine-like presidency over a family of nations, centered on pope and emperor in Rome". This has proved a lasting achievement.[84][85][86][87] Though, Otto's early death made his reign "the tale of largely unrealized potential".[88][89]
Henry II died in 1024 and Conrad II, first of the Salian dynasty, was elected king only after some debate among dukes and nobles. This group eventually developed into the college of electors. The Holy Roman Empire eventually came to be composed of four kingdoms:
Kings often employed bishops in administrative affairs and often determined who would be appointed to ecclesiastical offices.[90] In the wake of the Cluniac Reforms, this involvement was increasingly seen as inappropriate by the Papacy. The reform-minded Pope Gregory VII was determined to oppose such practices, which led to the Investiture Controversy with King Henry IV (r.1056–1106, crowned emperor in 1084).[90]
Henry IV repudiated the pope's interference and persuaded his bishops to excommunicate the pope, whom he famously addressed by his birth name "Hildebrand" rather than his papal name "Gregory".[91] The pope, in turn, excommunicated the king, declared him deposed, and dissolved the oaths of loyalty made to Henry.[13][91] The king found himself with almost no political support and was forced to make the famous Walk to Canossa in 1077,[92] by which he achieved a lifting of the excommunication at the price of humiliation. Meanwhile, the German princes had elected another king, Rudolf of Swabia.[93]
Henry managed to defeat Rudolf, but was subsequently confronted with more uprisings, renewed excommunication, and even the rebellion of his sons. After his death, his second son, Henry V, reached an agreement with the Pope and the bishops in the 1122 Concordat of Worms.[94] The political power of the Empire was maintained, but the conflict had demonstrated the limits of the ruler's power, especially in regard to the Church, and it robbed the king of the sacral status he had previously enjoyed. The pope and the German princes had surfaced as major players in the political system of the Holy Roman Empire.
As the result of Ostsiedlung, less populated regions of Central Europe (i.e. sparsely populated border areas in present-day Poland and the Czech Republic) received a significant number of German speakers. Silesia became part of the Holy Roman Empire as the result of the local Piast dukes' push for autonomy from the Polish Crown.[95] From the late 12th century, the Duchy of Pomerania was under the suzerainty of the Holy Roman Empire[96] and the conquests of the Teutonic Order made that region German-speaking.[97]
Hohenstaufen dynasty
Frederick Barbarossa, Holy Roman EmperorThe Hohenstaufen-ruled Holy Roman Empire and Kingdom of Sicily at its greatest extent under Frederick II. Imperial and directly held Hohenstaufen lands in the Empire are shown in bright yellow.
When the Salian dynasty ended with Henry V's death in 1125, the princes chose not to elect the next of kin, but rather Lothair III, the moderately powerful but already old duke of Saxony. When he died in 1137, the princes again aimed to check royal power; accordingly they did not elect Lothair's favoured heir, his son-in-law, Henry the Proud of the Welf family, but Conrad III of the Hohenstaufen family, the grandson of Emperor Henry IV and nephew of Emperor Henry V. This led to over a century of strife between the two houses. Conrad ousted the Welfs from their possessions, but after his death in 1152, his nephew Frederick Barbarossa succeeded him and made peace with the Welfs, restoring his cousin Henry the Lion to his – albeit diminished – possessions.
The Hohenstaufen rulers increasingly lent land to "ministeriales", formerly non-free servicemen, who Frederick hoped would be more reliable than dukes. Initially used mainly for war services, this new class of people would form the basis for the later knights, another basis of imperial power. A further important constitutional move at Roncaglia was the establishment of a new peace mechanism for the entire empire, the Landfrieden, with the first imperial one being issued in 1103 under Henry IV at Mainz.[98][99] This was an attempt to abolish private feuds, between the many dukes and other people, and to tie the emperor's subordinates to a legal system of jurisdiction and public prosecution of criminal acts–a predecessor of the modern concept of rule of law. Another new concept of the time was the systematic founding of new cities by the emperor and by the local dukes. These were partly a result of the explosion in population; they also concentrated economic power at strategic locations. Before this, cities had only existed in the form of old Roman foundations or older bishoprics. Cities that were founded in the 12th century include Freiburg, possibly the economic model for many later cities, and Munich.
Frederick Barbarossa was crowned emperor in 1155. He emphasized the "Romanness" of the empire, partly in an attempt to justify the power of the emperor independent of the (now strengthened) pope. An imperial assembly at the fields of Roncaglia in 1158 reclaimed imperial rights in reference to Justinian I's Corpus Juris Civilis. Imperial rights had been referred to as regalia since the Investiture Controversy but were enumerated for the first time at Roncaglia. This comprehensive list included public roads, tariffs, coining, collecting punitive fees, and the seating and unseating of office-holders. These rights were now explicitly rooted in Roman law, a far-reaching constitutional act.
Frederick's policies were primarily directed at Italy, where he clashed with the free-minded cities of the north, especially the Duchy of Milan. He also embroiled himself in another conflict with the Papacy by supporting a candidate elected by a minority against Pope Alexander III (1159–1181). Frederick supported a succession of antipopes before finally making peace with Alexander in 1177. In Germany, the emperor had repeatedly protected Henry the Lion against complaints by rival princes or cities (especially in the cases of Munich and Lübeck). Henry gave only lackluster support to Frederick's policies, and, in a critical situation during the Italian wars, Henry refused the emperor's plea for military support. After returning to Germany, an embittered Frederick opened proceedings against the duke, resulting in a public ban and the confiscation of all Henry's territories. In 1190, Frederick participated in the Third Crusade, dying in the Armenian Kingdom of Cilicia.[100]
During the Hohenstaufen period, German princes facilitated a successful, peaceful eastward settlement of lands that were uninhabited or inhabited sparsely by West Slavs. German-speaking farmers, traders, and craftsmen from the western part of the Empire, both Christians and Jews, moved into these areas. The gradual Germanization of these lands was a complex phenomenon that should not be interpreted in the biased terms of 19th-century nationalism. The eastward settlement expanded the influence of the empire to include Pomerania and Silesia, as did the intermarriage of the local, still mostly Slavic, rulers with German spouses. The Teutonic Knights were invited to Prussia by Duke Konrad of Masovia to Christianize the Prussians in 1226. The monastic state of the Teutonic Order (Deutschordensstaat) and its later German successor state of the Duchy of Prussia was never part of the Holy Roman Empire.
Under the son and successor of Frederick Barbarossa, Henry VI, the Hohenstaufen dynasty reached its apex, with the addition of the Norman kingdom of Sicily through the marriage of Henry VI and Constance of Sicily. Bohemia and Poland were under feudal dependence, while Cyprus and Lesser Armenia also paid homage. The Iberian-Moroccan caliph accepted his claims over the suzerainty over Tunis and Tripolitania and paid tribute. Fearing the power of Henry, the most powerful monarch in Europe since Charlemagne, the other European kings formed an alliance. But Henry broke this coalition by blackmailing English king Richard the Lionheart. The Byzantine emperor worried that Henry would turn his Crusade plan against his empire, and began to collect the alamanikon to prepare against the expected invasion. Henry also had plans for turning the Empire into a hereditary monarchy, although this met with opposition from some of the princes and the pope. The emperor suddenly died in 1197, leading to the partial collapse of his empire.[101][102][103] As his son, Frederick II, though already elected king, was still a small child and living in Sicily, German princes chose to elect an adult king, resulting in the dual election of Frederick Barbarossa's youngest son Philip of Swabia and Henry the Lion's son Otto of Brunswick, who competed for the crown. After Philip was murdered in a private squabble in 1208, Otto prevailed for a while, until he began to also claim Sicily.[clarification needed]
Pope Innocent III, who feared the threat posed by a union of the empire and Sicily, was now supported by Frederick II, who marched to Germany and defeated Otto. After his victory, Frederick did not act upon his promise to keep the two realms separate. Though he had made his son Henry king of Sicily before marching on Germany, he still reserved real political power for himself. This continued after Frederick was crowned emperor in 1220. Fearing Frederick's concentration of power, the pope finally excommunicated him. Another point of contention was the Crusade, which Frederick had promised but repeatedly postponed. Now, although excommunicated, Frederick led the Sixth Crusade in 1228, which ended in negotiations and a temporary restoration of the Kingdom of Jerusalem.
For his many-sided activities, prestige, and dynamic personality Frederick II has been called the greatest of all the medieval German emperors.[104] In the Kingdom of Sicily and much of Italy, Frederick built upon the work of his Norman predecessors and forged an early absolutist state bound together by an efficient secular bureaucracy. Despite his imperial prestige and power, Frederick II's rule was a major turning point toward the partitioning of central rule in the Empire. Since his political focus was south of the Alps, he was mostly absent from Germany and issued far-reaching privileges to Germany's secular and ecclesiastical princes to ensure their cooperation. In the 1220 Confoederatio cum principibus ecclesiasticis, Frederick gave up a number of regalia in favour of the bishops, among them tariffs, coining, and the right to build fortification. The 1232 Statutum in favorem principum mostly extended these privileges to secular territories. Although many of these privileges had existed earlier, they were now granted globally, and once and for all, to allow the German princes to maintain order north of the Alps while Frederick concentrated on Italy. The 1232 document marked the first time that the German dukes were called domini terrae, owners of their lands, a remarkable change in terminology as well. the Statutum affirmed a division of labor between the emperor and the princes and laid much groundwork for the development of particularism in Germany. Even so, from 1232 the vassals of the emperor had a veto over imperial legislative decisions and any new law established by the emperor had to be approved by the princes.
These provisions not withstanding, royal power in Germany remained strong under Frederick and by the 1240s the crown was still rich in fiscal resources, land holdings, retinues, and all other rights, revenues, and jurisdictions. Frederick II used the political loyalty and practical jurisdictions granted to the higher German aristocracy to impose peace, order, and justice upon Germany. The jurisdictional autarky of the German princes was favoured by the crown itself in the twelfth and thirteenth centuries in the interests of order and local peace. The inevitable result was the territorial particularism of churchmen, lay princes, and interstitial cities; however, Frederick was a ruler of vast territories and "could not be everywhere at once". The transference of jurisdiction was a practical solution to secure the further support of the German princes and, moreover, was a process which had already been underway even under Henry VI and Frederick Barbarossa. It is unlikely that a particularly "strong ruler" such as Frederick II would have even pragmatically agreed to legislation that was truly concessionary rather than cooperative, neither would the princes have insisted on such.[105]
The Mainz Landfriede or Constitutio Pacis, decreed at the Imperial Diet of 1235, became one of the basic laws of the empire and provided that the princes should share the burden of local government in Germany. The authority of the crown was not in question, rather its practical allocation in such a wide region which lacked a general administrative apparatus. Far from a broad diminution of royal power, the Mainz Landfriede was a constitutional recalibration based on the culmination of multi-decade political realities and a testament to Frederick II's considerable political strength, his increased prestige during the early 1230s, and sheer overpowering might that he succeeded in securing the princes' support and rebound them to Hohenstaufen power.[106]
Kingdom of Bohemia
The Kingdom of Bohemia was a significant regional power during the Middle Ages. In 1212, King Ottokar I (bearing the title "king" since 1198) extracted a Golden Bull of Sicily (a formal edict) from Emperor Frederick II, confirming the royal title for Ottokar and his descendants, and the Duchy of Bohemia was raised to a kingdom.[107] Bohemia's political and financial obligations to the Empire were gradually reduced.[108]Charles IV set Prague to be the seat of the Holy Roman emperor.
After the death of Frederick II in 1250, Conrad IV, Frederick's son (died 1254), enjoyed a strong position having defeated his papal-backed rival anti-king, William of Holland (died 1256). However, Conrad's death was followed by the Interregnum, during which no king could achieve universal recognition, allowing the princes to consolidate their holdings and become even more independent as rulers. After 1257, the crown was contested between Richard of Cornwall, who was supported by the Guelph party, and Alfonso X of Castile, who was recognized by the Hohenstaufen party but never set foot on German soil. After Richard's death in 1273, Rudolf I of Germany, a minor pro-Hohenstaufen count, was elected. He was the first of the Habsburgs to hold a royal title, but he was never crowned emperor. After Rudolf's death in 1291, Adolf and Albert were two further weak kings who were never crowned emperor.
Albert was assassinated in 1308. Almost immediately, King Philip IV of France began aggressively seeking support for his brother, Charles of Valois, to be elected the next king of the Romans. Philip thought he had the backing of the French Pope, Clement V (established at Avignon in 1309), and that his prospects of bringing the empire into the orbit of the French royal house were good. He lavishly spread French money in the hope of bribing the German electors. Although Charles of Valois had the backing of pro-French Henry, Archbishop of Cologne, many were not keen to see an expansion of French power, least of all Clement V. The principal rival to Charles appeared to be Count Palatine Rudolf II.
The electors, the great territorial magnates who had lived without a crowned emperor for decades, were unhappy with both Charles and Rudolf. Instead Count Henry of Luxembourg, with the aid of his brother, Archbishop Baldwin of Trier, was elected as Henry VII with six votes at Frankfurt on 27 November 1308. Though a vassal of King Philip, Henry was bound by few national ties, and thus suitable as a compromise candidate. Henry VII was crowned king at Aachen on 6 January 1309, and emperor by Pope Clement V on 29 June 1312 in Rome, ending the interregnum.
An illustration from Schedelsche Weltchronik depicting the structure of the Reich: The Holy Roman Emperor is sitting; on his right are three ecclesiastics; on his left are four secular electors.
During the 13th century, a general structural change in how land was administered prepared the shift of political power toward the rising bourgeoisie at the expense of the aristocratic feudalism that would characterize the Late Middle Ages. The rise of the cities and the emergence of the new burgher class eroded the societal, legal and economic order of feudalism.[109]
Peasants were increasingly required to pay tribute to their landlords. The concept of property began to replace more ancient forms of jurisdiction, although they were still very much tied together. In the territories (not at the level of the Empire), power became increasingly bundled: whoever owned the land had jurisdiction, from which other powers derived. Jurisdiction at the time did not include legislation, which was virtually nonexistent until well into the 15th century. Court practice heavily relied on traditional customs or rules described as customary.
During this time, territories began to transform into the predecessors of modern states. The process varied greatly among the various lands and was most advanced in those territories that were almost identical to the lands of the old Germanic tribes, e.g., Bavaria. It was slower in those scattered territories that were founded through imperial privileges.
In the 12th century the Hanseatic League established itself as a commercial and defensive alliance of the merchant guilds of towns and cities in the empire and all over northern and central Europe. It dominated marine trade in the Baltic Sea, the North Sea and along the connected navigable rivers. Each of the affiliated cities retained the legal system of its sovereign and, with the exception of the Free imperial cities, had only a limited degree of political autonomy. By the late 14th century, the powerful league enforced its interests with military means, if necessary. This culminated in the Danish–Hanseatic War from 1361 to 1370. The league declined after 1450.[h][110][111]
The difficulties in electing the king eventually led to the emergence of a fixed college of prince-electors (Kurfürsten), whose composition and procedures were set forth in the Golden Bull of 1356, issued by Charles IV (reigned 1355–1378, King of the Romans since 1346), which remained valid until 1806. This development probably best symbolizes the emerging duality between emperor and realm (Kaiser und Reich), which were no longer considered identical. The Golden Bull also set forth the system for election of the Holy Roman Emperor. The emperor now was to be elected by a majority rather than by consent of all seven electors. For electors the title became hereditary, and they were given the right to mint coins and to exercise jurisdiction. Also it was recommended that their sons learn the imperial languages – German, Latin, Italian, and Czech.[i][5]
The decision by Charles IV is the subject of debates: on one hand, it helped to restore peace in the lands of the Empire, that had been engulfed in civil conflicts after the end of the Hohenstaufen era; on the other hand, the "blow to central authority was unmistakable".[112] Thomas Brady Jr. opines that Charles IV's intention was to end contested royal elections (from the Luxembourghs' perspective, they also had the advantage that the King of Bohemia had a permanent and preeminent status as one of the Electors himself).[113][114] At the same time, he built up Bohemia as the Luxembourghs' core land of the Empire and their dynastic base. His reign in Bohemia is often considered the land's Golden Age. According to Brady Jr. though, under all the glitter, one problem arose: the government showed an inability to deal with the German immigrant waves into Bohemia, thus leading to religious tensions and persecutions. The imperial project of the Luxembourgh halted under Charles's son Wenceslaus (reigned 1378–1419 as King of Bohemia, 1376–1400 as King of the Romans), who also faced opposition from 150 local baronial families.[115]
The shift in power away from the emperor is also revealed in the way the post-Hohenstaufen kings attempted to sustain their power. Earlier, the Empire's strength (and finances) greatly relied on the Empire's own lands, the so-called Reichsgut, which always belonged to the king of the day and included many Imperial Cities. After the 13th century, the relevance of the Reichsgut faded, even though some parts of it did remain until the Empire's end in 1806. Instead, the Reichsgut was increasingly pawned to local dukes, sometimes to raise money for the Empire, but more frequently to reward faithful duty or as an attempt to establish control over the dukes. The direct governance of the Reichsgut no longer matched the needs of either the king or the dukes.[citation needed]
The kings beginning with Rudolf I of Germany increasingly relied on the lands of their respective dynasties to support their power. In contrast with the Reichsgut, which was mostly scattered and difficult to administer, these territories were relatively compact and thus easier to control. In 1282, Rudolf I thus lent Austria and Styria to his own sons. In 1312, Henry VII of the House of Luxembourg was crowned as the first Holy Roman Emperor since Frederick II. After him all kings and emperors relied on the lands of their own family (Hausmacht): Louis IV of Wittelsbach (king 1314, emperor 1328–1347) relied on his lands in Bavaria; Charles IV of Luxembourg, the grandson of Henry VII, drew strength from his own lands in Bohemia. It was thus increasingly in the king's own interest to strengthen the power of the territories, since the king profited from such a benefit in his own lands as well.[citation needed]
The "constitution" of the Empire still remained largely unsettled at the beginning of the 15th century. Feuds often happened between local rulers. The "robber baron" (Raubritter) became a social factor.[116] Simultaneously, the Catholic Church experienced crises of its own, with wide-reaching effects in the Empire. The conflict between several papal claimants (two anti-popes and the "legitimate" Pope) ended only with the Council of Constance (1414–1418); after 1419 the Papacy directed much of its energy to suppressing the Hussites. The medieval idea of unifying all Christendom into a single political entity, with the Church and the Empire as its leading institutions, began to decline. With these drastic changes, much discussion emerged in the 15th century about the Empire itself. Rules from the past no longer adequately described the structure of the time, and a reinforcement of earlier Landfrieden was urgently needed.[117]
The vision for a simultaneous reform of the Empire and the Church on a central level began with Sigismund (reigned 1433–1437, King of the Romans since 1411), who, according to historian Thomas Brady Jr., "possessed a breadth of vision and a sense of grandeur unseen in a German monarch since the thirteenth century". But external difficulties, self-inflicted mistakes and the extinction of the Luxembourg male line made this vision unfulfilled.[118]
Frederick III was the first Habsburg to be crowned Holy Roman Emperor, in 1452.[119] He had been very careful regarding the reform movement in the empire. For most of his reign, he considered reform as a threat to his imperial prerogatives. He avoided direct confrontations, which might lead to humiliation if the princes refused to give way.[120] After 1440, the reform of the Empire and Church was sustained and led by local and regional powers, particularly the territorial princes.[121] In his last years, he felt more pressure on taking action from a higher level. Berthold von Henneberg, the Archbishop of Mainz, who spoke on behalf of reform-minded princes (who wanted to reform the Empire without strengthening the imperial hand), capitalized on Frederick's desire to secure the imperial election for his son Maximilian. Thus, in his last years, he presided over the initial phase of Imperial Reform, which would mainly unfold under Maximilian. Maximilian himself was more open to reform, although naturally he also wanted to preserve and enhance imperial prerogatives. After Frederick retired to Linz in 1488, as a compromise, Maximilian acted as mediator between the princes and his father. When he attained sole rule after Frederick's death, he would continue this policy of brokerage, acting as the impartial judge between options suggested by the princes.[122][25]
Creation of institutions
Innsbruck, most important political centre under Maximilian, seat of the Hofkammer (Court Treasury) and the Court Chancery, which functioned as "the most influential body in Maximilian's government". Painting of Albrecht Dürer (1496)
Major measures for the Reform were launched at the 1495 Reichstag at Worms. A new organ was introduced, the Reichskammergericht, that was to be largely independent from the Emperor. A new tax was launched to finance it, the Gemeine Pfennig, although this would only be collected under Charles V and Ferdinand I, and not fully.[125][126][127] To create a rival for the Reichskammergericht, Maximilian established the Reichshofrat in 1497, which had its seat in Vienna. During Maximilian's reign, this council was not popular though. In the long run, the two Courts functioned in parallel, sometimes overlapping.[128][129]
In 1500, Maximilian agreed to establish an organ called the Reichsregiment (central imperial government, consisting of twenty members including the Electors, with the Emperor or his representative as its chairman), first organized in 1501 in Nuremberg. Maximilian resented the new organization, while the Estates failed to support it. The new organ proved politically weak, and its power returned to Maximilian in 1502.[130][129][131]
The most important governmental changes targeted the heart of the regime: the chancery. Early in Maximilian's reign, the Court Chancery at Innsbruck competed with the Imperial Chancery (which was under the elector-archbishop of Mainz, the senior Imperial chancellor). By referring the political matters in Tyrol, Austria as well as Imperial problems to the Court Chancery, Maximilian gradually centralized its authority. The two chanceries became combined in 1502.[124] In 1496, the emperor created a general treasury (Hofkammer) in Innsbruck, which became responsible for all the hereditary lands. The chamber of accounts (Raitkammer) at Vienna was made subordinate to this body.[132] Under Paul von Liechtenstein[de], the Hofkammer was entrusted with not only hereditary lands' affairs, but Maximilian's affairs as the German king too.[133]
Reception of Roman law
Maximilian I paying attention to an execution instead of watching the betrothal of his son Philip the Handsome and Joanna of Castile. The top right corner shows Cain and Abel. Satire against Maximilian's legal reform, associated with imperial tyranny. Created on behalf of the councilors of Augsburg. Plate 89 of Von der Arztney bayder Glück by the Petrarcameister[de].
At the 1495 Diet of Worms, the Reception of Roman Law was accelerated and formalized. The Roman Law was made binding in German courts, except in the case it was contrary to local statutes.[135] In practice, it became the basic law throughout Germany, displacing Germanic local law to a large extent, although Germanic law was still operative at the lower courts.[136][137][138][139] Other than the desire to achieve legal unity and other factors, the adoption also highlighted the continuity between the Ancient Roman empire and the Holy Roman Empire.[140] To realize his resolve to reform and unify the legal system, the emperor frequently intervened personally in matters of local legal matters, overriding local charters and customs. This practice was often met with irony and scorn from local councils, who wanted to protect local codes.[141]
The legal reform seriously weakened the ancient Vehmic court (Vehmgericht, or Secret Tribunal of Westphalia, traditionally held to be instituted by Charlemagne but this theory is now considered unlikely),[142][143] although it would not be abolished completely until 1811 (when it was abolished under the order of Jérôme Bonaparte).[144][145]
National political culture
Maximilian and Charles V (despite the fact both emperors were internationalists personally)[146][147] were the first who mobilized the rhetoric of the Nation, firmly identified with the Reich by the contemporary humanists.[116] With encouragement from Maximilian and his humanists, iconic spiritual figures were reintroduced or became notable. The humanists rediscovered the work Germania, written by Tacitus. According to Peter H. Wilson, the female figure of Germania was reinvented by the emperor as the virtuous pacific Mother of Holy Roman Empire of the German Nation.[148] Whaley further suggests that, despite the later religious divide, "patriotic motifs developed during Maximilian's reign, both by Maximilian himself and by the humanist writers who responded to him, formed the core of a national political culture."[149]
Maximilian's reign also witnessed the gradual emergence of the German common language, with the notable roles of the imperial chancery and the chancery of the Wettin Elector Frederick the Wise.[150][151] The development of the printing industry together with the emergence of the postal system (the first modern one in the world),[152] initiated by Maximilian himself with contribution from Frederick III and Charles the Bold, led to a revolution in communication and allowed ideas to spread. Unlike the situation in more centralized countries, the decentralized nature of the Empire made censorship difficult.[153][154][155][156]
Terence McIntosh comments that the expansionist, aggressive policy pursued by Maximilian I and Charles V at the inception of the early modern German nation (although not to further the aims specific to the German nation per se), relying on German manpower as well as utilizing fearsome Landsknechte and mercenaries, would affect the way neighbours viewed the German polity, although in the longue durée, Germany tended to be at peace.[157]
Maximilian was "the first Holy Roman Emperor in 250 years who ruled as well as reigned". In the early 1500s, he was true master of the Empire, although his power weakened during the last decade before his death.[158][159] Whaley notes that, despite struggles, what emerged at the end of Maximilian's rule was a strengthened monarchy and not an oligarchy of princes.[160] Benjamin Curtis opines that while Maximilian was not able to fully create a common government for his lands (although the chancellery and court council were able to coordinate affairs across the realms), he strengthened key administrative functions in Austria and created central offices to deal with financial, political and judicial matters – these offices replaced the feudal system and became representative of a more modern system that was administered by professionalized officials. After two decades of reforms, the emperor retained his position as first among equals, while the empire gained common institutions through which the emperor shared power with the estates.[161]
By the early 16th century, the Habsburg rulers had become the most powerful in Europe, but their strength relied on their composite monarchy as a whole, and not only the Holy Roman Empire (see also: Empire of Charles V).[162][163] Maximilian had seriously considered combining the Burgundian lands (inherited from his wife Mary of Burgundy) with his Austrian lands to form a powerful core (while also extending toward the east).[164] After the unexpected addition of Spain to the Habsburg Empire, at one point he intended to leave Austria (raised to a kingdom) to his younger grandson Ferdinand.[165] His elder grandson Charles V later gave Spain and most of the Burgundian lands to his son Philip II of Spain, the founder of the Spanish branch, and the Habsburg hereditary lands to his brother Ferdinand, the founder of the Austrian branch.[166]
In France and England, from the 13th century onward, stationary royal residences had begun to develop into capital cities that grew rapidly and developed corresponding infrastructure: the Palais de la Cité and the Palace of Westminster became the respective main residences. This was not possible in the Holy Roman Empire because no real hereditary monarchy emerged, but rather the tradition of elective monarchy prevailed (see: Imperial election) which, in the High Middle Ages, led to kings of very different regional origins being elected (List of royal and imperial elections in the Holy Roman Empire). If they wanted to control the empire and its rebellious regional rulers, they could not limit themselves to their home region and their private palaces. As a result, kings and emperors continued to travel around the empire well into modern times,[167] using their temporary residences (Kaiserpfalz) as transit stations for their itinerant courts. From the late Middle Ages onward, the weakly fortified pfalzen were replaced by imperial castles. It was only King Ferdinand I, the younger brother of the then Emperor Charles V, who moved his main residence to the Vienna Hofburg in the middle of the 16th century, where most of the following Habsburg emperors subsequently resided. Vienna did not become the capital of the empire, just of a Habsburg hereditary state (the Archduchy of Austria). The emperors continued to travel to their elections and coronations at Frankfurt and Aachen, to the Imperial Diets at different places and to other occasions. The Perpetual Diet of Regensburg was based in Regensburg from 1663 to 1806. Rudolf II resided in Prague, the Wittelsbach emperor Charles VII in Munich. A German capital in the true sense only existed in the Second German Empire from 1871, when the Kaiser, Reichstag and Reichskanzler resided in Berlin.
While particularism prevented the centralization of the Empire, it gave rise to early developments of capitalism. In Italian and Hanseatic cities like Genoa and Pisa, Hamburg and Lübeck, warrior-merchants appeared and pioneered raiding-and-trading maritime empires. These practices declined before 1500, but they managed to spread to the maritime periphery in Portugal, Spain, the Netherlands and England, where they "provoked emulation in grander, oceanic scale".[168] William Thompson agrees with M.N. Pearson that this distinctively European phenomenon happened because in the Italian and Hanseatic cities which lacked resources and were "small in size and population", the rulers (whose social status was not much higher than the merchants) had to pay attention to trade. Thus the warrior-merchants gained the state's coercive powers, which they could not gain in Mughal or other Asian realms – whose rulers had few incentives to help the merchant class, as they controlled considerable resources and their revenue was land-bound.[169]
In the 1450s, the economic development in Southern Germany gave rise to banking empires, cartels and monopolies in cities such as Ulm, Regensburg, and Augsburg. Augsburg in particular, associated with the reputation of the Fugger, Welser and Baumgartner families, is considered the capital city of early capitalism.[170][171] Augsburg benefitted majorly from the establishment and expansion of the Kaiserliche Reichspost in the late 15th and early 16th century.[153][152] Even when the Habsburg empire began to extend to other parts of Europe, Maximilian's loyalty to Augsburg, where he conducted a lot of his endeavours, meant that the imperial city became "the dominant centre of early capitalism" of the 16th century, and "the location of the most important post office within the Holy Roman Empire". From Maximilian's time, as the "terminuses of the first transcontinental post lines" began to shift from Innsbruck to Venice and from Brussels to Antwerp, in these cities, the communication system and the news market started to converge. As the Fuggers as well as other trading companies based their most important branches in these cities, these traders gained access to these systems as well.[172]
The 1557, 1575, and 1607 bankruptcies of the Spanish branch of the Habsburgs though damaged the Fuggers substantially. Moreover, "Discovery of water routes to India and the New World shifted the focus of European economic development from the Mediterranean to the Atlantic – emphasis shifted from Venice and Genoa to Lisbon and Antwerp. Eventually American mineral developments reduced the importance of Hungarian and Tyrolean mineral wealth. The nexus of the European continent remained landlocked until the time of expedient land conveyances in the form of primarily rail and canal systems, which were limited in growth potential; in the new continent, on the other hand, there were ports in abundance to release the plentiful goods obtained from those new lands." The economic pinnacles achieved in Germany in the period between 1450 and 1550 would not be seen again until the end of the 19th century.[173]
In the Netherlands part of the empire, financial centres evolved together with markets of commodities. Topographical development in the 15th century made Antwerp a port city.[174] Boosted by the privileges it received as a loyal city after the Flemish revolts against Maximilian, it became the leading seaport city in Northern Europe and served as "the conduit for a remarkable 40% of world trade".[175][176][177] Conflicts with the Habsburg-Spanish government in 1576 and 1585 though made merchants relocate to Amsterdam, which eventually replaced it as the leading port city.[178][174]
In 1516, Ferdinand II of Aragon died.[179] His grandson Charles would go on to inherit the thrones of Castile and Aragon (with his mother Joanna of Castile), despite only being a teenager at the time. This succession to both thrones would later evolve into the union of Spain. Another important event happened in 1517: Martin Luther launched what would later be known as the Protestant Reformation. The Reformation divided the Empire along religious lines as it proceeded, with the north, the east, and many of the major cities – Strasbourg, Frankfurt, and Nuremberg – becoming Protestant while the southern and western regions largely remained Catholic.
Maximilian died in 1519, triggering an election for the next Emperor. Charles was Ferdinand's grandson on his mother's side, but Maximilian's grandson on his father's side, and was one of the two main candidates for the position along with Francis I of France. Charles won the election, becoming Charles V, Holy Roman Emperor; he traveled to Germany in 1520.
At the beginning of Charles's reign, another Reichsregiment was set up again (1522), although Charles declared that he would only tolerate it in his absence and its chairman had to be a representative of his. Charles V was absent in Germany from 1521 to 1530. Similar to the one set up in the early 1500s, the Reichsregiment failed to create a federal authority independent of the emperor, due to the unsteady participation and differences between princes. Charles V defeated the Protestant princes in 1547 in the Schmalkaldic War, but the momentum was lost and the Protestant estates were able to survive politically despite military defeat.[180] In the 1555 Peace of Augsburg, Charles V, through his brother Ferdinand, officially recognized the right of rulers to choose Catholicism or Lutheranism (Zwinglians, Calvinists and radicals were not included).[181] In 1555, Paul IV was elected pope and took the side of France, whereupon an exhausted Charles finally gave up his hopes of a world Christian empire.[182][183]
The succession Charles V arranged split the Habsburgs into two branches. The senior branch continued to rule in Spain and in the Burgundian inheritance, headed by Charles's son, Philip II of Spain. The Holy Roman Empire went to a junior branch of the Habsburgs, Charles's brother Ferdinand I. Many factors contribute to this result. For James D. Tracy, it was the polycentric character of the European civilization that made it hard to maintain "a dynasty whose territories bestrode the continent from the Low Countries to Sicily and from Spain to Hungary–not to mention Spain's overseas possessions".[184] Others point out the religious tensions, fiscal problems and obstruction from external forces including France and the Ottomans.[185] On a more personal level, Charles failed to persuade the German princes to support his son Philip, whose "awkward and withdrawn character and lack of German language skills doomed this enterprise to failure".[186]
Germany would enjoy relative peace for the next six decades. On the eastern front, the Turks continued to loom large as a threat, although war would mean further compromises with the Protestant princes, and so the Emperor sought to avoid it. In the west, the Rhineland increasingly fell under French influence. After the Dutch revolt against Spain erupted, the Empire remained neutral, de facto allowing the Netherlands to depart the empire in 1581. A side effect was the Cologne War, which ravaged much of the upper Rhine. Emperor Ferdinand III formally accepted Dutch neutrality in 1653, a decision ratified by the Reichstag in 1728.
After Ferdinand died in 1564, his son Maximilian II became Emperor, and like his father accepted the existence of Protestantism and the need for occasional compromise with it. Maximilian was succeeded in 1576 by Rudolf II, who preferred classical Greek philosophy to Christianity and lived an isolated existence in Bohemia. He became afraid to act when the Catholic Church was forcibly reasserting control in Austria and Hungary, and the Protestant princes became upset over this.
Imperial power sharply deteriorated by the time of Rudolf's death in 1612. When Bohemians rebelled against the Emperor, the immediate result was the series of conflicts known as the Thirty Years' War (1618–1648), which devastated the empire. Foreign powers, including France and Sweden, intervened in the conflict and strengthened those fighting the Imperial power, but also seized considerable territory for themselves. Accordingly, the empire could never return to its former glory, leading Voltaire to make his infamous quip that the Holy Roman Empire was "neither Holy nor Roman nor an Empire."[187]
Still, its actual end did not come for two centuries. The Peace of Westphalia in 1648, which ended the Thirty Years' War allowed Calvinism, but Anabaptists, Arminians and other Protestant communities would still lack any support and continue to be persecuted well until the end of the empire. The Habsburg emperors focused on consolidating their own estates in Austria and elsewhere.
From 1792 onward, revolutionary France was at war with various parts of the Empire intermittently. The German mediatization was the series of mediatizations and secularizations that occurred between 1795 and 1814, during the latter part of the era of the French Revolution and then the Napoleonic era. "Mediatization" was the process of annexing the lands of one imperial estate to another, often leaving the annexed some rights. For example, the estates of the Imperial Knights were formally mediatized in 1806, having de facto been seized by the great territorial states in 1803 in the so-called Rittersturm. "Secularization" was the abolition of the temporal power of an ecclesiastical ruler such as a bishop or an abbot and the annexation of the secularized territory to a secular territory.
The Napoleonic Confederation of the Rhine was replaced by a new union, the German Confederation in 1815, following the end of the Napoleonic Wars. It lasted until 1866 when Prussia founded the North German Confederation, a forerunner of the German Empire which united the German-speaking territories outside of Austria and Switzerland under Prussian leadership in 1871. This state developed into modern Germany.
The abdication indicated that the Kaiser no longer felt capable of fulfilling his duties as head of the Reich, and so declared: "That we consider the tie that has bound us to the body politic of the German Reich to be broken, that we have expired the office and dignity of the head of the Reich through the unification of the confederated Rhenish estates and that we are thereby relieved of all the duties we have assumed towards the German Reich Consider counted, and lay down the imperial crown worn by the same until now and conducted imperial government, as is hereby done."[188]
The only princely member states of the Holy Roman Empire that have preserved their status as monarchies until today are the Grand Duchy of Luxembourg and the Principality of Liechtenstein. The only Free Imperial Cities still existing as states within Germany are Hamburg and Bremen. All other historic member states of the Holy Roman Empire were either dissolved or have adopted republican systems of government.
Demographics
Population
Overall population figures for the Holy Roman Empire are extremely vague and vary widely. The empire of Charlemagne may have had as many as 20 million people.[189] Given the political fragmentation of the later Empire, there were no central agencies that could compile such figures. Nevertheless, it is believed the demographic disaster of the Thirty Years' War meant that the population of the Empire in the early 17th century was similar to what it was in the early 18th century; by one estimate, the Empire did not exceed 1618 levels of population until 1750.[190] In the early 17th century, the electors held under their rule the following number of Imperial subjects:[191]
Habsburg Monarchy: 5,350,000 (including 3 million in the Bohemian crown lands)[192][full citation needed]
Electorate of Saxony: 1,200,000
Duchy of Bavaria (later Electorate of Bavaria): 800,000
Electoral Palatinate: 600,000
Electorate of Brandenburg: 350,000
Electorates of Mainz, Trier, and Cologne: 300–400,000 altogether[193]
While not electors, the Spanish Habsburgs had the second highest number of subjects within the Empire after the Austrian Habsburgs, with over 3 million in the early 17th century in the Burgundian Circle and Duchy of Milan.[j][k] Peter Wilson estimates the Empire's population at 20 million in 1700, plus 5 million in Imperial Italy, a total of around 25 million. By 1800, he estimates the Empire's population at 29 million (excluding Italy), with another 12.6 million held by under Austrian and Prussian dominion outside of the Empire.[7] According to a contemporary estimate of the Austrian War Archives for the first decade of the 18th century, the Empire–including Bohemia and the Spanish Netherlands–had a population of close to 28million with a breakdown as follows:[194]
65 ecclesiastical states with 14 percent of the total land area and 12 percent of the population;
45 dynastic principalities with 80 percent of the land and 80 percent of the population;
60 dynastic counties and lordships with 3 percent of the land and 3.5 percent of the population;
60 imperial towns with 1 percent of the land and 3.5 percent of the population;
Imperial knights' territories, numbering into the several hundreds, with 2 percent of the land and 1 percent of the population.
German demographic historians have traditionally worked on estimates of the population of the Holy Roman Empire based on assumed population within the frontiers of Germany in 1871 or 1914. More recent estimates use less outdated criteria, but they remain guesswork. One estimate based on the frontiers of Germany in 1870 gives a population of some 15–17million around 1600, declined to 10–13million around 1650 (following the Thirty Years' War). Other historians who work on estimates of the population of the early modern Empire suggest the population declined from 20million to some 16–17million by 1650.[195] A credible estimate for 1800 gives 27–28million inhabitants for the Empire (which at this point had already lost the remaining Low Countries, Italy, and the Left Bank of the Rhine in the 1797 Treaty of Campo Formio) with an overall breakdown as follows:[196]
9million Austrian subjects (including Silesia, Bohemia and Moravia);
4million Prussian subjects;
14–15million inhabitants for the rest of the Empire.
There are also numerous estimates for the Italian states that were formally part of the Empire:
States of Imperial Italy by population, early 17th century[197]
Front page of the Peace of Augsburg, which laid the legal groundwork for two co-existing religious confessions (Roman Catholicism and Lutheranism) in the German-speaking states of the Holy Roman Empire
Following the Peace of Augsburg, the official religion of a territory was determined by the principle cuius regio, eius religio according to which a ruler's religion determined that of his subjects. The Peace of Westphalia abrogated that principle by stipulating that the official religion of a territory was to be what it had been on 1 January 1624, considered to have been a "normal year". Henceforth, the conversion of a ruler to another faith did not entail the conversion of his subjects.[206]
In addition, all Protestant subjects of a Catholic ruler and vice versa were guaranteed the rights that they had enjoyed on that date. While the adherents of a territory's official religion enjoyed the right of public worship, the others were allowed the right of private worship (in chapels without either spires or bells). In theory, no one was to be discriminated against or excluded from commerce, trade, craft or public burial on grounds of religion. For the first time, the permanent nature of the division between the Christian churches of the empire was more or less assumed.[206]
A Jewish minority existed in the Holy Roman Empire. The Holy Roman Emperors claimed the right of protection and taxation of all the Jews of the empire, but there were also large-scale massacres of Jews, especially at the time of the First Crusade and during the wars of religion in the 16th century.
Institutions
The Holy Roman Empire was neither a centralized state nor a nation-state. Instead, it was divided into dozens – eventually hundreds – of individual entities governed by kings,[o]dukes, counts, bishops, abbots, and other rulers, collectively known as princes. There were also some areas ruled directly by the Emperor. From the High Middle Ages onwards, the Holy Roman Empire was marked by an uneasy coexistence with the princes of the local territories who were struggling to take power away from it. To a greater extent than in other medieval kingdoms such as France and England, the emperors were unable to gain much control over the lands that they formally owned. Instead, to secure their own position from the threat of being deposed, emperors were forced to grant more and more autonomy to local rulers, both nobles and bishops. This process began in the 11th century with the Investiture Controversy and was more or less concluded with the 1648 Peace of Westphalia. Several Emperors attempted to reverse this steady dilution of their authority but were thwarted both by the papacy and by the princes of the Empire.
The number of territories represented in the Imperial Diet was considerable, numbering about 300 at the time of the Peace of Westphalia. Many of these Kleinstaaten ("little states") covered no more than a few square miles, or included several non-contiguous pieces, so the Empire was often called a Flickenteppich ("patchwork carpet"). An entity was considered a Reichsstand (imperial estate) if, according to feudal law, it had no authority above it except the Holy Roman Emperor himself. The imperial estates comprised:
Territories ruled by a hereditary nobleman, such as a prince, archduke, duke, or count.
Territories in which secular authority was held by an ecclesiastical dignitary, such as an archbishop, bishop, or abbot. Such an ecclesiastic or Churchman was a prince of the Church. In the common case of a prince-bishop, this temporal territory (called a prince-bishopric) frequently overlapped with his often larger ecclesiastical diocese, giving the bishop both civil and ecclesiastical powers. Examples are the prince-archbishoprics of Cologne, Trier, and Mainz.
The most powerful lords of the later empire were the Austrian Habsburgs, who ruled 240,000km2 (93,000sqmi) of land within the Empire in the first half of the 17th century, mostly in modern-day Austria and the Czech Republic. At the same time the lands ruled by the electors of Saxony, Bavaria, and Brandenburg (prior to the acquisition of Prussia) were all close to 40,000km2 (15,000sqmi); the Duke of Brunswick-Lüneburg (later the Elector of Hanover) had a territory around the same size. These were the largest of the German realms. The Elector of the Palatinate had significantly less at 20,000km2 (7,700sqmi), and the ecclesiastical Electorates of Mainz, Cologne, and Trier were much smaller, with around 7,000km2 (2,700sqmi). Just larger than them, with roughly 7,000–10,000km2 (2,700–3,900sqmi), were the Duchy of Württemberg, the Landgraviate of Hessen-Kassel, and the Duchy of Mecklenburg-Schwerin. They were roughly matched in size by the prince-bishoprics of Salzburg and Münster. The majority of the other German territories, including the other prince-bishoprics, were under 5,000km2 (1,900sqmi), the smallest being those of the Imperial Knights; around 1790 the Knights consisted of 350 families ruling a total of only 5,000km2 (1,900sqmi) collectively.[208]
Imperial Italy was less fragmented politically, most of it c.1600 being divided between Savoy (Savoy, Piedmont, Nice, Aosta), the Grand Duchy of Tuscany (Tuscany, bar Lucca), the Republic of Genoa (Liguria, Corisca), the duchies of Modena-Reggio and Parma-Piacenza (Emilia), and the Spanish Duchy of Milan (most of Lombardy), each with between half a million and one and a half million people.[197] The Low Countries were also more coherent than Germany, being entirely under the dominion of the Spanish Netherlands as part of the Burgundian Circle, at least nominally. In 1792, 21 families (8 electors and 13 princely families) held 81 percent of the Empire's territory, plus all electoral and 56 of the 100 princely votes. These 21 families held 25 territories (some families had cadet branches e.g. the Bavarian and Palatinate Wittelsbachs), by far the largest being Austria and Prussia. Another 16.4 percent of the Empire was split between 151 ecclesiastical and secular lords, generally lacking princely status, with the majority of that 16.4 percent being held by a tenth of the lords. The remaining 2.6 percent of the Empire was split between 51 disconnected imperial cities and 400 families of Imperial Knights.[209]
Territorial shares of the Reich after the Thirty Years' War[210][p]
A prospective Emperor first had to be elected King of the Romans. German kings had been elected since the 9th century; at that point they were chosen by the leaders of the five most important tribes (the Salian Franks of Lorraine, Ripuarian Franks of Franconia, Saxons, Bavarians, and Swabians). In the Holy Roman Empire, the main dukes and bishops of the kingdom elected the King of the Romans. The imperial throne was transferred by election, but Emperors often ensured their own sons were elected during their lifetimes, enabling them to keep the crown for their families. This only changed after the end of the Salian dynasty in the 12th century.
After being elected, the King of the Romans could theoretically claim the title of "Emperor" only after being crowned by the Pope. In many cases, this took several years while the King was held up by other tasks: frequently he first had to resolve conflicts in rebellious northern Italy or was quarreling with the Pope himself. Later Emperors dispensed with the papal coronation altogether, being content with the styling Emperor-Elect: the last Emperor to be crowned by the Pope was Charles V in 1530.
The Emperor had to be male and of noble blood. No law required him to be a Catholic, but as the majority of the Electors adhered to this faith, no Protestant was ever elected. Whether and to what degree he had to be German was disputed among the Electors, contemporary experts in constitutional law, and the public. During the Middle Ages, some Kings and Emperors were not of German origin, but since the Renaissance, German heritage was regarded as vital for a candidate in order to be eligible for imperial office.[211]
The Imperial Diet (Reichstag or Reichsversammlung) was not a legislative body as is understood today, as its members envisioned it to be more like a central forum, where it was more important to negotiate than to decide.[212] The Diet was theoretically superior to the emperor himself. It was divided into three classes. The first class, the Council of Electors, consisted of the electors, or the princes who could vote for King of the Romans. The second class, the Council of Princes, consisted of the other princes. The Council of Princes was divided into two "benches", one for secular rulers and one for ecclesiastical ones. Higher-ranking princes had individual votes, while lower-ranking princes were grouped into "colleges" by geography. Each college had one vote.
The third class was the Council of Imperial Cities, which was divided into two colleges: Swabia and the Rhine. The Council of Imperial Cities was not fully equal with the others; it could not vote on several matters such as the admission of new territories. The representation of the Free Cities at the Diet had become common since the late Middle Ages. Nevertheless, their participation was formally acknowledged only as late as 1648 with the Peace of Westphalia ending the Thirty Years' War.
Imperial Aulic Chancellery
The Imperial Aulic Chancellery (Reichshofkanzlei) was the main Aulic (Courtly) Chancellery of the Holy Roman Empire. It was formed in 1559, by emperor Ferdinand I, and existed until the dissolution of the Empire in 1806. During that period, it was headed by the Imperial Archchancellor (Reichserzkanzler), an honorary post traditionally reserved for the Archbishops of Mainz. In practice, it was run by the Imperial Vicechancellor (Reichsvizekanzler), who was appointed among notable statesmen and administrators in imperial service.[213]
Imperial courts
Reichskammergericht, around 1750
Reichshofrat, around 1700
The Empire also had two courts: the Reichshofrat (also known in English as the Aulic Council) at the court of the King/Emperor, and the Reichskammergericht (Imperial Chamber Court), established with the Imperial Reform of 1495 by Maximilian I. The Reichskammergericht and the Aulic Council were the two highest judicial instances in the Old Empire. The Imperial Chamber court's composition was determined by both the Holy Roman Emperor and the subject states of the Empire. Within this court, the Emperor appointed the chief justice, always a highborn aristocrat, several divisional chief judges, and some of the other puisne judges.[214]
The Aulic Council held standing over many judicial disputes of state, both in concurrence with the Imperial Chamber court and exclusively on their own. The provinces Imperial Chamber Court extended to breaches of the public peace, cases of arbitrary distraint or imprisonment, pleas which concerned the treasury, violations of the Emperor's decrees or the laws passed by the Imperial Diet, disputes about property between immediate tenants of the Empire or the subjects of different rulers, and finally suits against immediate tenants of the Empire, with the exception of criminal charges and matters relating to imperial fiefs, which went to the Aulic Council. The Aulic Council even allowed the emperors the means to depose rulers who did not live up to expectations.[129][128]
Imperial circles
A map of the Empire showing division into Circles in 1512
As part of the Imperial Reform, six Imperial circles were established in 1500; four more were established in 1512. These were regional groupings of most (though not all) of the various states of the Empire for the purposes of defense, imperial taxation, supervision of coining, peace-keeping functions, and public security. Each circle had its own parliament, known as a Kreistag ("Circle Diet"), and one or more directors, who coordinated the affairs of the circle. Not all imperial territories were included within the imperial circles, even after 1512; the Lands of the Bohemian Crown were excluded, as were Switzerland, the imperial fiefs in northern Italy, the lands of the Imperial Knights, and certain other small territories like the Lordship of Jever.
The Army of the Holy Roman Empire (German: Reichsarmee, Reichsheer or Reichsarmatur; Latin: exercitus imperii) was created in 1422 and as a result of the Napoleonic Wars came to an end even before the Empire. It should not be confused with the Imperial Army (Kaiserliche Armee) of the Emperor. Despite appearances to the contrary, the Army of the Empire did not constitute a permanent standing army that was always at the ready to fight for the Empire. When there was danger, an Army of the Empire was mustered from among the elements constituting it,[215] in order to conduct an imperial military campaign or Reichsheerfahrt. In practice, the imperial troops often had local allegiances stronger than their loyalty to the Emperor.
Throughout the first half of its history the Holy Roman Empire was reigned over by a travelling court. Kings and emperors toured between the numerous Kaiserpfalzes (Imperial palaces), usually resided for several weeks or months and furnished local legal matters, law and administration. Most rulers maintained one or a number of favourite Imperial palace sites, where they would advance development and spent most of their time: Charlemagne (Aachen from 794), Otto I (Magdeburg, from 955),[216] Frederick II (Palermo 1220–1254), Wittelsbacher (Munich 1328–1347 and 1744–1745), Habsburger (Prague 1355–1437 and 1576–1611; and Vienna 1438–1576, 1611–1740 and 1745–1806).[12][217][218]
This practice eventually ended during the 16th century, as the emperors of the Habsburg dynasty chose Vienna and Prague and the Wittelsbach rulers chose Munich as their permanent residences (Maximilian I's "true home" was still "the stirrup, the overnight rest and the saddle", although Innsbruck was probably his most important base; Charles V was also a nomadic emperor).[219][220][221] Vienna became Imperial capital during the 1550s under Ferdinand I (reigned 1556–1564). Except for a period under Rudolf II (reigned 1570–1612) who moved to Prague, Vienna kept its primacy under his successors.[219][222] Before that, certain sites served only as the individual residence for a particular sovereign. A number of cities held official status, where the Imperial Estates would summon at Imperial Diets, the deliberative assembly of the empire.[223][224]
The Habsburg royal family had its own diplomats to represent its interests. The larger principalities in the Holy Roman Empire, beginning around 1648, also did the same. The Holy Roman Empire did not have its own dedicated ministry of foreign affairs and therefore the Imperial Diet had no control over these diplomats; occasionally the Diet criticised them.[229] When Regensburg served as the site of the Diet, France and, in the late 1700s, Russia, had diplomatic representatives there.[229] The kings of Denmark, Great Britain, and Sweden had land holdings in Germany and so had representation in the Diet itself.[230] The Netherlands also had envoys in Regensburg. Regensburg was the place where envoys met as it was where representatives of the Diet could be reached.[231]
Some constituencies of the Holy Roman Empire had additional royal or imperial territories that were, sometimes from the outset, outside the jurisdiction of the Holy Roman Empire. Henry VI, inheriting both German aspirations for imperial sovereignty and the Norman Sicilian kings' dream of hegemony in the Mediterranean, had ambitious design for a world empire. Boettcher remarks that marriage policy also played an important role here, "The marital policy of the Staufer ranged from Iberia to Russia, from Scandinavia to Sicily, from England to Byzantium and to the crusader states in the East. Henry was already casting his eyes beyond Africa and Greece, to Asia Minor and Syria and of course on Jerusalem." His annexation of Sicily changed the strategic balance in the Italian peninsula. The emperor, who wanted to make all his lands hereditary, also asserted that papal fiefs were imperial fiefs. On his death at the age of 31 though, he was unable to pass his powerful position to his son, Frederick II, who had only been elected King of the Romans.[232][233][234] The union between Sicily and the Empire thus remained personal union.[235] Frederick II became King of Jerusalem in 1225 through marriage to Isabella II (or Yolande) of Jerusalem and regained Bethlehem and Nazareth for the Christian side through negotiation with Al-Kamil. The Hohenstaufen dream of world empire ended with Frederick's death in 1250.[236][237]
In its earlier days, the Empire provided the principal medium for Christianity to infiltrate the pagans' realms in the North and the East (Scandinavians, Magyars, Slavic people etc.).[238] By the Reform era, the Empire, in its nature, was defensive and not aggressive, desiring of both internal peace and security against invading forces, a fact that even warlike princes such as Maximilian I appreciated.[239] In the Early Modern age, the association with the Church (the Church Universal for the Luxemburgs, and the Catholic Church for the Habsburgs) as well as the emperor's responsibility for the defence of Central Europe remained a reality though. Even the trigger for the conception of the Imperial Reform under Sigismund was the idea of helping the Church to put its house in order.[240][241][242]
Hungarian map of parts of the Holy Roman Empire (Német-római Császárság), including Italy, Bohemia (Csehország), and Hungary (Magyarország) under Sigismund in the 15th century
Traditionally, German dynasties had exploited the potential of the imperial title to bring Eastern Europe into the fold, in addition to their lands north and south of the Alps. Marriage and inheritance strategies, following by (usually defensive) warfare, played a great role both for the Luxemburgs and the Habsburgs. It was under Sigismund of the Luxemburg, who married Mary, Queen regnal and the rightful heir of Hungary and later consolidated his power with the marriage to the capable and well-connected noblewoman Barbara of Cilli,[243] that the emperor's personal empire expanded to a kingdom outside the boundary of the Holy Roman Empire: Hungary. This last monarch of the Luxemburg dynasty (who wore four royal crowns) had managed to gain an empire almost comparable in scale to the later Habsburg empire, although at the same time they lost the Kingdom of Burgundy and control over Italian territories. The Luxemburgs' focus on the East, especially Hungary, allowed the new Burgundian rulers from the Valois dynasty to foster discontent among German princes. Thus, the Habsburgs were forced to refocus their attention on the West. Frederick III's cousin and predecessor, Albert II of Germany (who was Sigismund's son-in-law and heir through his marriage with Elizabeth of Luxembourg) had managed to combine the crowns of Germany, Hungary, Bohemia and Croatia under his rule, but he died young.[244][245][246]
During his rule, Maximilian I had a double focus on both the East and the West. The successful expansion (with the notable role of marriage policy) under Maximilian bolstered his position in the Empire, and also created more pressure for an imperial reform, so that they could get more resources and coordinated help from the German territories to defend their realms and counter hostile powers such as France.[247][248] Ever since he became King of the Romans in 1486, the Empire provided essential help for his activities in Burgundian Netherlands as well as dealings with Bohemia, Hungary and other eastern polities.[249] In the reigns of his grandsons, Croatia and the remaining rump of the Hungarian kingdom chose Ferdinand as their ruler after he managed to rescue Silesia and Bohemia from Hungary's fate against the Ottoman. Simms notes that their choice was a contractual one, tying Ferdinand's rulership in these kingdoms and territories to his election as King of the Romans and his ability to defend Central Europe.[250][251] In turn, the Habsburgs' imperial rule also "depended on holding these additional extensive lands as independent sources of wealth and prestige."[252]
The empire of Charles V at its peak after the Peace of Crépy in 1544
The later Austrian Habsburgs from Ferdinand I were careful to maintain a distinction between their dynastic empire and the Holy Roman Empire. Peter Wilson argues that the institutions and structures developed by the Imperial Reform mostly served German lands and, although the Habsburg monarchy "remained closely entwined with the Empire", the Habsburgs deliberately refrained from including their other territories in its framework. "Instead, they developed their own institutions to manage what was, effectively, a parallel dynastic-territorial empire and which gave them an overwhelming superiority of resources, in turn allowing them to retain an almost unbroken grip on the imperial title over the next three centuries."[253] Ferdinand had an interest in keeping Bohemia separate from imperial jurisdiction and making the connection between Bohemia and the Empire looser (Bohemia did not have to pay taxes to the Empire). As he refused the rights of an Imperial Elector as King of Bohemia (which provided him with half of his revenue[254]), he was able to give Bohemia (as well as associated territories such as Upper and Lower Alsatia, Silesia and Moravia) the same privileged status as Austria, therefore affirming his superior position in the Empire.[156][255] The Habsburgs also tried to mobilize imperial aid for Hungary (which, throughout the 16th century, cost the dynasty more money in defence expenditure than the total revenue it yielded).[256]
Since 1542, Charles V and Ferdinand had been able to collect the Common Penny tax, or Türkenhilfe (Turkish aid), designed to protect the Empire against the Ottomans or France. But as Hungary, unlike Bohemia, was not part of the Empire, the imperial aid for Hungary depended on political factors. The obligation was only in effect if Vienna or the Empire were threatened.[125][257][258][126] Wilson notes that, "In the early 1520s the Reichstag hesitated to vote aid for Hungary's King Louis II, because it regarded him as a foreign prince. This changed once Hungary passed to the Habsburgs on Louis' death in battle in 1526 and the main objective of imperial taxation across the next 90 years was to subsidize the cost of defending the Hungarian frontier against the Ottomans. The bulk of the weaponry and other military materiel was supplied by firms based in the Empire and financed by German banks. The same is true of the troops who eventually evicted the Ottomans from Hungary between 1683 and 1699. The imperial law code of 1532 was used in parts of Hungary until the mid-17th century, but otherwise Hungary had its own legal system and did not import Austrian ones. Hungarian nobles resisted the use of Germanic titles like Graf for count until 1606, and very few acquired the personal status of imperial prince."[259]
Habsburg domains within the Holy Roman Empire in 1789
Responding to the opinion that the Habsburg's dynastic concerns were damaging to the Holy Roman Empire, Whaley writes that, "There was no fundamental incompatibility between dynasticism and participation in the empire, either for the Habsburgs or for the Saxons or others."[149] Imperial marriage strategies had double-edged effects for the Holy Roman Empire though. The Spanish connection was an example: while it provided a powerful partner in the defence of Christendom against the Ottomans, it allowed Charles V to transfer the Burgundian Netherlands, Franche-Comte as well as other imperial fiefs such as Milan to his son Philip II's Spanish Empire.[260][261]
Other than the imperial families, other German princes possessed foreign lands as well, and foreign rulers could also acquire imperial fiefs and thus become imperial princes. This phenomenon contributed to the fragmentation of sovereignty, in which imperial vassals remained semi-sovereign, while strengthening the interconnections (and chances of mutual interference) between the Kingdom of Germany and the Empire in general with other kingdoms such as Denmark and Sweden, who accepted the status of imperial vassals on behalf of their German possessions (which were subjected to imperial laws). The two Scandinanvian monarchies honoured the obligations to come to the aid of the Empire in the wars of 17th and early 18th centuries. They also imported German princely families as rulers, although in both cases, this did not produce direct unions. Denmark consistently tried to take advantage of its influence in imperial institutions to gain new imperial fiefs along the Elbe, although these attempts generally did not succeed.[262]
↑According to the perspective of the Eastern Orthodox Church, before the c. Great Schism of 1054 (a gradual process), the Holy Roman Empire (along with the rest of Western Europe) was Orthodox Christian, being under the ecclesiastical jurisdiction of the Patriarchate of Rome before Pope Leo IX broke communion with the other churches. As a prime example, Emperor Henry II (†1024) ruled the state and died shortly before the Schism, yet is venerated as a Saint by both Roman Catholicsand Orthodox. For the neutral purposes of this article, "Latin" designates the Empire's official faith before and after the Schism.
↑German "Roman" Empire: Due to feudal organization the realm controlled by the emperor is hard to define, much less measure. It is estimated to peak around 1050 at about 1.0 Mm2. (Taagepera 1997, p.494)
↑While Charlemagne and his successors assumed variations of the title emperor, none termed themselves Roman emperor until Otto II in 983. "Nature of the empire". Encyclopædia Britannica Online. Retrieved 15 February 2014.
↑Quapropter statuimus, ut illustrium principum, puta regis Boemie, comitis palatini Reni, ducis Saxonie et marchionis Brandemburgensis electorum filii vel heredes et successores, cum verisimiliter Theutonicum ydioma sibi naturaliter inditum scire presumantur et ab infancia didicisse, incipiendo a septimo etatis sue anno in gramatica, Italica ac Sclavica lingwis instruantur, ita quod infra quartum decimum etatis annum existant in talibus iuxta datam sibi a Deo graciam eruditi. (Zeumern 1908)
↑1.35 million population given for the Duchy of Milan. (Smith 1920, p.19)
↑Populations of 1.6 million and 1.5 million given for the areas within the borders of modern Belgium and the Netherlands, respectively, around 1600; the Spanish holdings in the Burgundian Circle also included Franche-Comte, Luxembourg, and other small territories. (Avakov 2015)
↑A figure of 800,000 is given by Smith for "Savoy in Italy", with no clarification as to whether that refers to the whole Savoyard state or just its Italian territories of Piedmont and the Aosta Valley (thus excluding Savoy proper and the County of Nice). However Hanlon 2014, p.87 gives early 17th century Piedmont's population as 700,000, and Savoy proper's as 400,000, with no numbers given for Aosta or Nice; indicating that Smith's use of "Savoy of Italy" does indeed only refer to Piedmont and Aosta.
↑Excluding the 500,000 inhabitants of the island of Sardinia, which was not part of the Empire.
↑Referred to in the source as "Austrian Lombardy." A large portion of the former duchy had been annexed by the Venetian Republic earlier in the 18th century.
↑The only prince allowed to call himself "king" of a territory in the Empire was the King of Bohemia (after 1556 usually the Emperor himself). Some other princes were kings by virtue of kingdoms they controlled outside of the Empire
↑Going by the given areas, Wilson's figures only include the German and Czech speaking parts of the Reich, thus excluding the French (e.g. Austrian Netherlands, Franche-Comté) and Italian (e.g. Tuscany, Piedmont-Savoy) parts. This is evident in how the territories of the electors and "other German rulers" adds up to the stated total of the Reich, and in how the Reich's area does not change from the given 687,338km2 (265,383sqmi) total from 1648 to 1792, despite many French territories of the Burgundian Circle being lost in this time. The figures also exclude lands held outside of the Empire (including German ones), such as the Hohenzollern Prussian territories.
↑In 1648: Saxony, Bavaria, and the Electoral Palatinate. At later dates: Saxony, Bavaria, the Electoral Palatinate, and Hanover.
↑Coy, Jason Philip; Marschke, Benjain min; Sabean, David Warren (2010). The Holy Roman Empire, Reconsidered. Berghahn Books. p.2. ISBN978-1-8454-5992-5.
↑"Holy Roman Empire". Encyclopædia Britannica Online. Retrieved 15 February 2014.
123Whaley 2012a, p.20: "Even so, it is possible to speak of the emergence of a 'German' Reich in the decades around 1500. In theory, the fifteenth-century Reich was composed of three major blocks or groups of territories: Italy, Germany, and Burgundy. In practice, however, only the Kingdom of Germany remained. One of Maximilian's enduring ambitions was to recover the Italian and Burgundian lands that had been lost; at one stage he even tried to reconquer Provence in order to regain the old centre of the Burgundian kingdom at Arles. Yet ultimately these were projects that failed and by the end of his reign the Reich was, more than ever, exclusively centred on the Kingdom of Germany."
↑"Charlemagne". History. 9 November 2009. Archived from the original on 6 September 2022. Retrieved 19 September 2022.
↑Loud, Graham A.; Schenk, Jochen (2017). The Origins of the German Principalities, 1100–1350: Essays by German Historians. Taylor & Francis. p.49. ISBN978-1-3170-2200-8.
↑Whaley 2011a, pp.xi–xii: "In humanist discourse around 1500, 'Germany' is frequently found. It remained in use in political discourse and in literature. The title Das Heilige Römische Reich deutscher Nation, which gained currency around 1500, also underlines the identification of the empire as a specifically German polity."
↑Arnold, Benjamin (2000). "Emperor Frederick II (1194–1250) and the political particularism of the German princes". Journal of Medieval History. 26 (3): 239–252. doi:10.1016/S0304-4181(00)00005-1.
↑Karl Otmar von Aretin: Das Reich ohne Hauptstadt? (The empire without a capital?), in: Hauptstädte in europäischen Nationalstaaten (Capitals in European nation states), ed T Schieder & G Brunn, Munich/Vienna, 1983, pp. 1–29
↑Behringer, Wolfgang (2011). "Core and Periphery: The Holy Roman Empire as a Communication(s) Universe". The Holy Roman Empire, 1495–1806(PDF). Oxford: Oxford University Press. pp.347–358. ISBN978-0-1996-0297-1. Archived(PDF) from the original on 9 October 2022. Retrieved 7 August 2022.
Arnold, Benjamin (1995). "14 The Western Empire 1125–1197". In Luscombe, David; Riley-Smith, Jonathan (eds.). The New Cambridge Medieval History, Volume 4: c. 1024–c. 1198, Part 2. Vol.4. doi:10.1017/CHOL9780521414111.016. ISBN978-0-5214-1411-1.
Avakov, Alexander V. (2015). Two Thousand Years of Economic Statistics. Vol.1. New York: Algora.
Cipolla, Carlo M. (1981). Fighting the Plague in Seventeenth Century Italy. Madison: University of Wisconsin Press.
Claus, Edda (1997). The Rebirth of a Communications Network: Europe at the Time of the Carolingians (M.Sc thesis). hdl:1866/803.
Collins, Paul (2014). The Birth of the West: Rome, Germany, France, and the Creation of Europe in the Tenth Century. PublicAffairs. ISBN978-1-6103-9368-3. OL28037381M.
Curtis, Benjamin (2013). The Habsburgs: The History of a Dynasty. Bloomsbury. p.36.
Corvisier, André; Childs, John (1994). A dictionary of military history and the art of war.
Davies, Norman (1996). A History of Europe. Oxford.
Holleger, Manfred (2012). "Personality and reign The biography of Emperor Maximilian I". In Michel, Eva; Sternat, Maria Luise (eds.). Emperor Maximilian I and the Age of Durer(PDF). Prestel; Albertina. pp.32–33. ISBN978-3-7913-5172-8. Retrieved 2 December 2021.
Hoyt, Robert S.; Chodorow, Stanley (1976). Europe in the Middle Ages. Harcourt brace Jovanovich.
Lauryssens, Stan (1999). The Man Who Invented the Third Reich: The Life and Times of Arthur Moeller van den Bruck. Stroud: Sutton. ISBN978-0-7509-1866-4.
Legauy, Jean Pierre (1995). "6. Urban Life". In Jones, Michael C. E. (ed.). The New Cambridge Medieval History, Volume 6, c. 1300–c.1415. Vol.6. Cambridge University Press. ISBN978-0-5213-6290-0.
Magill, Frank (1998). Dictionary of World Biography. Vol.II. London: Fitzroy Dearborn.
Malettke, Klaus (2001). Les relations entre la France et le Saint-Empire au XVIIe siècle (in French). Paris: Honoré Champion.
McBrien, Richard P. (2000). Lives of the Popes: The Pontiffs from St. Peter to Benedict XVI. HarperCollins.
Schulze, Hans K. (1998). Grundstrukturen der Verfassung im Mittelalter[Basic structures of the constitution in the Middle Ages] (in German). Vol.Bd. 3 (Kaiser und Reich). Stuttgart: Kohlhammer Verlag.
Taylor, Bayard; Hansen-Taylor, Marie (1894). A history of Germany from the earliest times to the present day. New York: D. Appleton & Co. p.117.
Voltaire (1773) [1756]. "Chapitre LXX". Essais sur les mœurs et l'ésprit des nations (in French). Vol.3 (nouvelleed.). Neuchâtel. p.338. OCLC797016561. Ce corps qui s'appelait, & qui s'appelle encore, le Saint-Empire Romain, n'était en aucune manière, ni saint, ni romain, ni empire
Wilson, Peter H. (2004). From Reich To Revolution: German History, 1558–1806.
Wilson, Peter H. (December 2006). "Bolstering the Prestige of the Habsburgs: The End of the Holy Roman Empire in 1806". The International History Review. 28 (4): 709–736. doi:10.1080/07075332.2006.9641109. S2CID154316830.
Wilson, Peter H. (2009). Europe's Tragedy: A History of the Thirty Years' War. Allen Lane.
Wilson, Peter H. (2016). Heart of Europe: A History of the Holy Roman Empire. Belknap Press. ISBN978-0-6740-5809-5.
Zeumern, Karl, ed. (1908), Goldene Bulle, Hermann Böhlaus
Coy, Jason Philip; Marschke, Benjamin; Sabean, David Warren, eds. (2010). The Holy Roman Empire, Reconsidered. Berghahn Books. ISBN978-1-8454-5992-5. OL38653949M.
Donaldson, George. Germany: A Complete History (Gotham Books, New York, 1985)
Hahn, Hans Joachim. German thought and culture: From the Holy Roman Empire to the present day (Manchester University Press, 1995).
Scribner, Bob. Germany: A New Social and Economic History, Vol. 1: 1450–1630 (1995)
Stollberg-Rilinger, Barbara. The Holy Roman Empire: A Short History. Princeton, New Jersey: Princeton University Press, 2018.
Treasure, Geoffrey. The Making of Modern Europe, 1648–1780 (3rd ed. 2003). pp.374–426.
Zophy, Jonathan W., ed. The Holy Roman Empire: A Dictionary Handbook (Greenwood Press, 1980)
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.





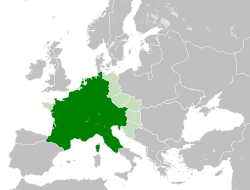












![Maximilian I paying attention to an execution instead of watching the betrothal of his son Philip the Handsome and Joanna of Castile. The top right corner shows Cain and Abel. Satire against Maximilian's legal reform, associated with imperial tyranny. Created on behalf of the councilors of Augsburg. Plate 89 of Von der Arztney bayder Gluck by the Petrarcameister [de]. Maximilian I watching an execution during Philip and Joanna betrothal.jpg](http://upload.wikimedia.org/wikipedia/commons/thumb/9/9b/Maximilian_I_watching_an_execution_during_Philip_and_Joanna_betrothal.jpg/330px-Maximilian_I_watching_an_execution_during_Philip_and_Joanna_betrothal.jpg)






















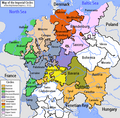

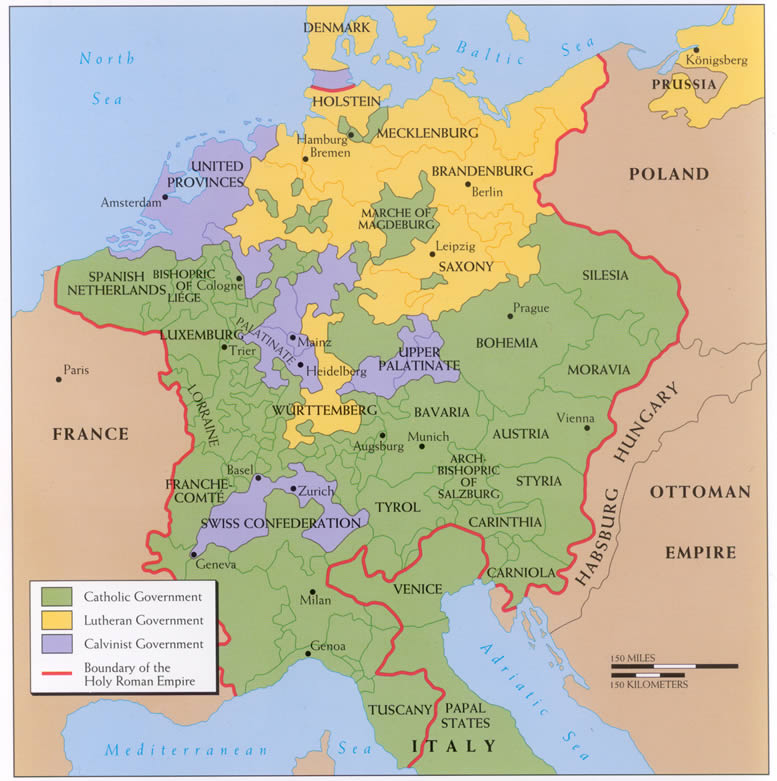{kind=link}