
The cell cycle, or cell-division cycle, is the series of events that take place in a cell that cause it to divide into two daughter cells. These events include the duplication of its DNA and some of its organelles, and subsequently the partitioning of its cytoplasm and other components into two daughter cells in a process called cell division.

In molecular biology, a transcription factor (TF) is a protein that controls the rate of transcription of genetic information from DNA to messenger RNA, by binding to a specific DNA sequence. The function of TFs is to regulate—turn on and off—genes in order to make sure that they are expressed in the desired cells at the right time and in the right amount throughout the life of the cell and the organism. Groups of TFs function in a coordinated fashion to direct cell division, cell growth, and cell death throughout life; cell migration and organization during embryonic development; and intermittently in response to signals from outside the cell, such as a hormone. There are up to 1600 TFs in the human genome. Transcription factors are members of the proteome as well as regulome.

The G0 phase describes a cellular state outside of the replicative cell cycle. Classically, cells were thought to enter G0 primarily due to environmental factors, like nutrient deprivation, that limited the resources necessary for proliferation. Thus it was thought of as a resting phase. G0 is now known to take different forms and occur for multiple reasons. For example, most adult neuronal cells, among the most metabolically active cells in the body, are fully differentiated and reside in a terminal G0 phase. Neurons reside in this state, not because of stochastic or limited nutrient supply, but as a part of their developmental program.
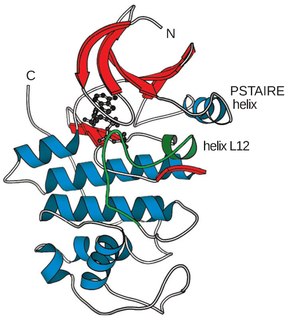
Cyclin-dependent kinases (CDKs) are the families of protein kinases first discovered for their role in regulating the cell cycle. They are also involved in regulating transcription, mRNA processing, and the differentiation of nerve cells. They are present in all known eukaryotes, and their regulatory function in the cell cycle has been evolutionarily conserved. In fact, yeast cells can proliferate normally when their CDK gene has been replaced with the homologous human gene. CDKs are relatively small proteins, with molecular weights ranging from 34 to 40 kDa, and contain little more than the kinase domain. By definition, a CDK binds a regulatory protein called a cyclin. Without cyclin, CDK has little kinase activity; only the cyclin-CDK complex is an active kinase but its activity can be typically further modulated by phosphorylation and other binding proteins, like p27. CDKs phosphorylate their substrates on serines and threonines, so they are serine-threonine kinases. The consensus sequence for the phosphorylation site in the amino acid sequence of a CDK substrate is [S/T*]PX[K/R], where S/T* is the phosphorylated serine or threonine, P is proline, X is any amino acid, K is lysine, and R is arginine.

A basic helix–loop–helix (bHLH) is a protein structural motif that characterizes one of the largest families of dimerizing transcription factors. The word "basic" does not refer to complexity but to the chemistry of the motif because transcription factors in general contain basic amino acid residues in order to facilitate DNA binding.
Inhibitor of DNA-binding/differentiation proteins, also known as ID proteins comprise a family of proteins that heterodimerize with basic helix-loop-helix (bHLH) transcription factors to inhibit DNA binding of bHLH proteins. ID proteins also contain the HLH-dimerization domain but lack the basic DNA-binding domain and thus regulate bHLH transcription factors when they heterodimerize with bHLH proteins. The first helix-loop-helix proteins identified were named E-proteins because they bind to Ephrussi-box (E-box) sequences. In normal development, E proteins form dimers with other bHLH transcription factors, allowing transcription to occur. However, in cancerous phenotypes, ID proteins can regulate transcription by binding E proteins, so no dimers can be formed and transcription is inactive. E proteins are members of the class I bHLH family and form dimers with bHLH proteins from class II to regulate transcription. Four ID proteins exist in humans: ID1, ID2, ID3, and ID4. The ID homologue gene in Drosophila is called extramacrochaetae (EMC) and encodes a transcription factor of the helix-loop-helix family that lacks a DNA binding domain. EMC regulates cell proliferation, formation of organs like the midgut, and wing development. ID proteins could be potential targets for systemic cancer therapies without inhibiting the functioning of most normal cells because they are highly expressed in embryonic stem cells, but not in differentiated adult cells. Evidence suggests that ID proteins are overexpressed in many types of cancer. For example, ID1 is overexpressed in pancreatic, breast, and prostate cancers. ID2 is upregulated in neuroblastoma, Ewing’s sarcoma, and squamous cell carcinoma of the head and neck.

A leucine zipper is a common three-dimensional structural motif in proteins. They were first described by Landschulz and collaborators in 1988 when they found that an enhancer binding protein had a very characteristic 30-amino acid segment and the display of these amino acid sequences on an idealized alpha helix revealed a periodic repetition of leucine residues at every seventh position over a distance covering eight helical turns. The polypeptide segments containing these periodic arrays of leucine residues were proposed to exist in an alpha-helical conformation and the leucine side chains from one alpha helix interdigitate with those from the alpha helix of a second polypeptide, facilitating dimerization.
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence or have a general affinity to DNA. Some DNA-binding domains may also include nucleic acids in their folded structure.

Sterol regulatory element-binding proteins (SREBPs) are transcription factors that bind to the sterol regulatory element DNA sequence TCACNCCAC. Mammalian SREBPs are encoded by the genes SREBF1 and SREBF2. SREBPs belong to the basic-helix-loop-helix leucine zipper class of transcription factors. Unactivated SREBPs are attached to the nuclear envelope and endoplasmic reticulum membranes. In cells with low levels of sterols, SREBPs are cleaved to a water-soluble N-terminal domain that is translocated to the nucleus. These activated SREBPs then bind to specific sterol regulatory element DNA sequences, thus upregulating the synthesis of enzymes involved in sterol biosynthesis. Sterols in turn inhibit the cleavage of SREBPs and therefore synthesis of additional sterols is reduced through a negative feed back loop.

CDK-activating kinase (CAK) activates the cyclin-CDK complex by phosphorylating threonine residue 160 in the CDK activation loop. CAK itself is a member of the Cdk family and functions as a positive regulator of Cdk1, Cdk2, Cdk4, and Cdk6.
In molecular biology, origin recognition complex (ORC) is a multi-subunit DNA binding complex that binds in all eukaryotes and archaea in an ATP-dependent manner to origins of replication. The subunits of this complex are encoded by the ORC1, ORC2, ORC3, ORC4, ORC5 and ORC6 genes. ORC is a central component for eukaryotic DNA replication, and remains bound to chromatin at replication origins throughout the cell cycle.
The scleraxis protein is a member of the basic helix-loop-helix (bHLH) superfamily of transcription factors. Currently two genes have been identified to code for identical scleraxis proteins.

Cyclin D is a member of the cyclin protein family that is involved in regulating cell cycle progression. The synthesis of cyclin D is initiated during G1 and drives the G1/S phase transition. Cyclin D protein is anywhere from 155 to 477 amino acids in length.
An E-box is a DNA response element found in some eukaryotes that acts as a protein-binding site and has been found to regulate gene expression in neurons, muscles, and other tissues. Its specific DNA sequence, CANNTG, with a palindromic canonical sequence of CACGTG, is recognized and bound by transcription factors to initiate gene transcription. Once the transcription factors bind to the promoters through the E-box, other enzymes can bind to the promoter and facilitate transcription from DNA to mRNA.
Transcription factor II B (TFIIB) is a general transcription factor that is involved in the formation of the RNA polymerase II preinitiation complex (PIC) and aids in stimulating transcription initiation. TFIIB is localised to the nucleus and provides a platform for PIC formation by binding and stabilising the DNA-TBP complex and by recruiting RNA polymerase II and other transcription factors. It is encoded by the TFIIB gene, and is homologous to archaeal transcription factor B and analogous to bacterial sigma factors.

DNA-binding protein inhibitor ID-2 is a protein that in humans is encoded by the ID2 gene.

Sterol regulatory element-binding protein 2 (SREBP-2) also known as sterol regulatory element binding transcription factor 2 (SREBF2) is a protein that in humans is encoded by the SREBF2 gene.

Transcription factor HES1 is a protein that is encoded by the Hes1 gene, and is the mammalian homolog of the hairy gene in Drosophila. HES1 is one of the seven members of the Hes gene family (HES1-7). Hes genes code nuclear proteins that suppress transcription.
RNA polymerase II holoenzyme is a form of eukaryotic RNA polymerase II that is recruited to the promoters of protein-coding genes in living cells. It consists of RNA polymerase II, a subset of general transcription factors, and regulatory proteins known as SRB proteins.
An upstream activating sequence or upstream activation sequence (UAS) is a cis-acting regulatory sequence. It is distinct from the promoter and increases the expression of a neighbouring gene. Due to its essential role in activating transcription, the upstream activating sequence is often considered to be analogous to the function of the enhancer in multicellular eukaryotes. Upstream activation sequences are a crucial part of induction, enhancing the expression of the protein of interest through increased transcriptional activity. The upstream activation sequence is found adjacently upstream to a minimal promoter and serves as a binding site for transactivators. If the transcriptional transactivator does not bind to the UAS in the proper orientation then transcription cannot begin. To further understand the function of an upstream activation sequence, it is beneficial to see its role in the cascade of events that lead to transcription activation. The pathway begins when activators bind to their target at the UAS recruiting a mediator. A TATA-binding protein subunit of a transcription factor then binds to the TATA box, recruiting additional transcription factors. The mediator then recruits RNA polymerase II to the pre-initiation complex. Once initiated, RNA polymerase II is released from the complex and transcription begins.
